[jsoup]Fatal Exception: java.lang.ExceptionInInitializerError
처음으로 사용해보는 jsoup라이브러리…. 오류가 터져 나오고 있음이 감지 되었다.
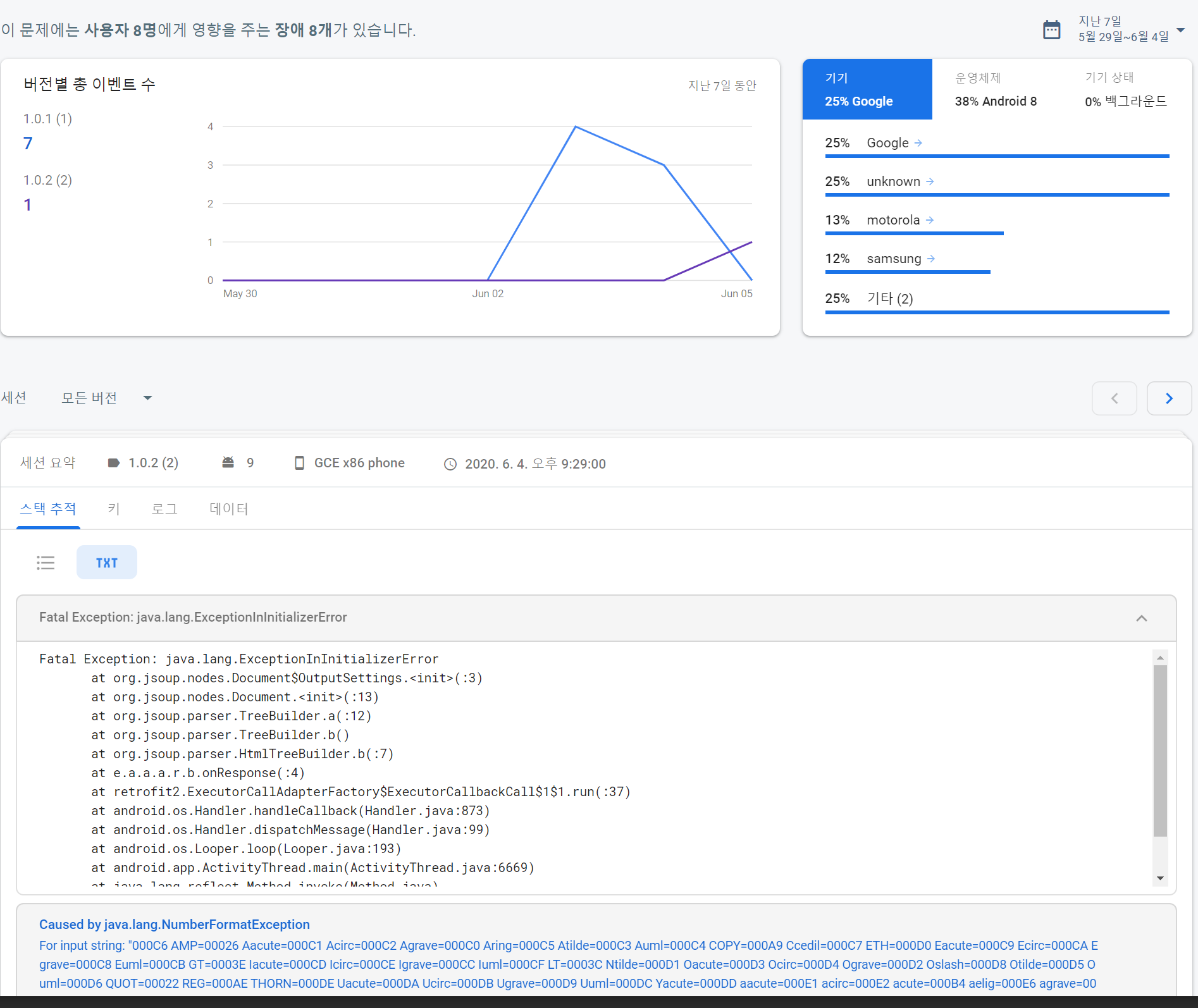
Fatal Exception: java.lang.ExceptionInInitializerError
at org.jsoup.nodes.Document$OutputSettings.<init>(:3)
at org.jsoup.nodes.Document.<init>(:13)
at org.jsoup.parser.TreeBuilder.a(:12)
at org.jsoup.parser.TreeBuilder.b()
at org.jsoup.parser.HtmlTreeBuilder.b(:7)
at e.a.a.a.r.b.onResponse(:4)
at retrofit2.ExecutorCallAdapterFactory$ExecutorCallbackCall$1$1.run(:37)
at android.os.Handler.handleCallback(Handler.java:873)
at android.os.Handler.dispatchMessage(Handler.java:99)
at android.os.Looper.loop(Looper.java:193)
at android.app.ActivityThread.main(ActivityThread.java:6669)
at java.lang.reflect.Method.invoke(Method.java)
at com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:493)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:858)Caused by java.lang.NumberFormatException: For input string: "000C6
AMP=00026
Aacute=000C1
Acirc=000C2
Agrave=000C0
Aring=000C5
Atilde=000C3
Auml=000C4
COPY=000A9
Ccedil=000C7
ETH=000D0
Eacute=000C9
Ecirc=000CA
Egrave=000C8
Euml=000CB
GT=0003E
Iacute=000CD
Icirc=000CE
Igrave=000CC
Iuml=000CF
LT=0003C
Ntilde=000D1
Oacute=000D3
Ocirc=000D4
Ograve=000D2
Oslash=000D8
Otilde=000D5
Ouml=000D6
QUOT=00022
REG=000AE
THORN=000DE
Uacute=000DA
Ucirc=000DB
Ugrave=000D9
Uuml=000DC
Yacute=000DD
aacute=000E1
acirc=000E2
acute=000B4
aelig=000E6
agrave=000E0
amp=00026
aring=000E5
atilde=000E3
auml=000E4
brvbar=000A6
ccedil=000E7
cedil=000B8
cent=000A2
copy=000A9
curren=000A4
deg=000B0
divide=000F7
eacute=000E9
ecirc=000EA
egrave=000E8
eth=000F0
euml=000EB
frac12=000BD
frac14=000BC
frac34=000BE
gt=0003E
iacute=000ED
icirc=000EE
iexcl=000A1
igrave=000EC
iquest=000BF
iuml=000EF
laquo=000AB
lt=0003C
macr=000AF
micro=000B5
middot=000B7
nbsp=000A0
not=000AC
ntilde=000F1
oacute=000F3
ocirc=000F4
ograve=000F2
ordf=000AA
ordm=000BA
oslash=000F8
otilde=000F5
ouml=000F6
para=000B6
plusmn=000B1
pound=000A3
quot=00022
raquo=000BB
reg=000AE
sect=000A7
shy=000AD
sup1=000B9
sup2=000B2
sup3=000B3
szlig=000DF
thorn=000FE
times=000D7
uacute=000FA
ucirc=000FB
ugrave=000F9
uml=000A8
uuml=000FC
yacute=000FD
yen=000A5
yuml=000FF
"
at java.lang.Integer.parseInt(Integer.java:615)
at org.jsoup.nodes.Entities.a(:9)
at org.jsoup.nodes.Entities$EscapeMode.<init>(:3)
at org.jsoup.nodes.Entities$EscapeMode.<clinit>(:22)
at org.jsoup.nodes.Document$OutputSettings.<init>(:3)
at org.jsoup.nodes.Document.<init>(:13)
at org.jsoup.parser.TreeBuilder.a(:12)
at org.jsoup.parser.TreeBuilder.b()
at org.jsoup.parser.HtmlTreeBuilder.b(:7)
at e.a.a.a.r.b.onResponse(:4)
at retrofit2.ExecutorCallAdapterFactory$ExecutorCallbackCall$1$1.run(:37)
at android.os.Handler.handleCallback(Handler.java:873)
at android.os.Handler.dispatchMessage(Handler.java:99)
at android.os.Looper.loop(Looper.java:193)
at android.app.ActivityThread.main(ActivityThread.java:6669)
at java.lang.reflect.Method.invoke(Method.java)
at com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:493)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:858)코드 난독화 해제만이 해결책인가???????????????????????????????????????????????
코드 난독화 제외를 위해 proguard-ruels.pro 파일에 아래 내용을 추가보았으나 오류는 동일하게 계속 발생되었다.
-keep class org.jsoup.**
org.jsoup.nodes.Entties의 소스 코드 보기
package org.jsoup.nodes;
import org.jsoup.SerializationException;
import org.jsoup.internal.StringUtil;
import org.jsoup.helper.Validate;
import org.jsoup.nodes.Document.OutputSettings;
import org.jsoup.parser.CharacterReader;
import org.jsoup.parser.Parser;
import java.io.IOException;
import java.nio.charset.CharsetEncoder;
import java.util.Arrays;
import java.util.HashMap;
import static org.jsoup.nodes.Document.OutputSettings.*;
import static org.jsoup.nodes.Entities.EscapeMode.base;
import static org.jsoup.nodes.Entities.EscapeMode.extended;
/**
* HTML entities, and escape routines. Source: <a href="http://www.w3.org/TR/html5/named-character-references.html#named-character-references">W3C
* HTML named character references</a>.
*/
public class Entities {
private static final int empty = -1;
private static final String emptyName = "";
static final int codepointRadix = 36;
private static final char[] codeDelims = {',', ';'};
private static final HashMap<String, String> multipoints = new HashMap<>(); // name -> multiple character references
private static final OutputSettings DefaultOutput = new OutputSettings();
public enum EscapeMode {
/**
* Restricted entities suitable for XHTML output: lt, gt, amp, and quot only.
*/
xhtml(EntitiesData.xmlPoints, 4),
/**
* Default HTML output entities.
*/
base(EntitiesData.basePoints, 106),
/**
* Complete HTML entities.
*/
extended(EntitiesData.fullPoints, 2125);
// table of named references to their codepoints. sorted so we can binary search. built by BuildEntities.
private String[] nameKeys;
private int[] codeVals; // limitation is the few references with multiple characters; those go into multipoints.
// table of codepoints to named entities.
private int[] codeKeys; // we don't support multicodepoints to single named value currently
private String[] nameVals;
EscapeMode(String file, int size) {
load(this, file, size);
}
int codepointForName(final String name) {
int index = Arrays.binarySearch(nameKeys, name);
return index >= 0 ? codeVals[index] : empty;
}
String nameForCodepoint(final int codepoint) {
final int index = Arrays.binarySearch(codeKeys, codepoint);
if (index >= 0) {
// the results are ordered so lower case versions of same codepoint come after uppercase, and we prefer to emit lower
// (and binary search for same item with multi results is undefined
return (index < nameVals.length - 1 && codeKeys[index + 1] == codepoint) ?
nameVals[index + 1] : nameVals[index];
}
return emptyName;
}
private int size() {
return nameKeys.length;
}
}
private Entities() {
}
/**
* Check if the input is a known named entity
*
* @param name the possible entity name (e.g. "lt" or "amp")
* @return true if a known named entity
*/
public static boolean isNamedEntity(final String name) {
return extended.codepointForName(name) != empty;
}
/**
* Check if the input is a known named entity in the base entity set.
*
* @param name the possible entity name (e.g. "lt" or "amp")
* @return true if a known named entity in the base set
* @see #isNamedEntity(String)
*/
public static boolean isBaseNamedEntity(final String name) {
return base.codepointForName(name) != empty;
}
/**
* Get the character(s) represented by the named entity
*
* @param name entity (e.g. "lt" or "amp")
* @return the string value of the character(s) represented by this entity, or "" if not defined
*/
public static String getByName(String name) {
String val = multipoints.get(name);
if (val != null)
return val;
int codepoint = extended.codepointForName(name);
if (codepoint != empty)
return new String(new int[]{codepoint}, 0, 1);
return emptyName;
}
public static int codepointsForName(final String name, final int[] codepoints) {
String val = multipoints.get(name);
if (val != null) {
codepoints[0] = val.codePointAt(0);
codepoints[1] = val.codePointAt(1);
return 2;
}
int codepoint = extended.codepointForName(name);
if (codepoint != empty) {
codepoints[0] = codepoint;
return 1;
}
return 0;
}
/**
* HTML escape an input string. That is, {@code <} is returned as {@code <}
*
* @param string the un-escaped string to escape
* @param out the output settings to use
* @return the escaped string
*/
public static String escape(String string, OutputSettings out) {
if (string == null)
return "";
StringBuilder accum = StringUtil.borrowBuilder();
try {
escape(accum, string, out, false, false, false);
} catch (IOException e) {
throw new SerializationException(e); // doesn't happen
}
return StringUtil.releaseBuilder(accum);
}
/**
* HTML escape an input string, using the default settings (UTF-8, base entities). That is, {@code <} is returned as
* {@code <}
*
* @param string the un-escaped string to escape
* @return the escaped string
*/
public static String escape(String string) {
return escape(string, DefaultOutput);
}
// this method is ugly, and does a lot. but other breakups cause rescanning and stringbuilder generations
static void escape(Appendable accum, String string, OutputSettings out,
boolean inAttribute, boolean normaliseWhite, boolean stripLeadingWhite) throws IOException {
boolean lastWasWhite = false;
boolean reachedNonWhite = false;
final EscapeMode escapeMode = out.escapeMode();
final CharsetEncoder encoder = out.encoder();
final CoreCharset coreCharset = out.coreCharset; // init in out.prepareEncoder()
final int length = string.length();
int codePoint;
for (int offset = 0; offset < length; offset += Character.charCount(codePoint)) {
codePoint = string.codePointAt(offset);
if (normaliseWhite) {
if (StringUtil.isWhitespace(codePoint)) {
if ((stripLeadingWhite && !reachedNonWhite) || lastWasWhite)
continue;
accum.append(' ');
lastWasWhite = true;
continue;
} else {
lastWasWhite = false;
reachedNonWhite = true;
}
}
// surrogate pairs, split implementation for efficiency on single char common case (saves creating strings, char[]):
if (codePoint < Character.MIN_SUPPLEMENTARY_CODE_POINT) {
final char c = (char) codePoint;
// html specific and required escapes:
switch (c) {
case '&':
accum.append("&");
break;
case 0xA0:
if (escapeMode != EscapeMode.xhtml)
accum.append(" ");
else
accum.append(" ");
break;
case '<':
// escape when in character data or when in a xml attribute val or XML syntax; not needed in html attr val
if (!inAttribute || escapeMode == EscapeMode.xhtml || out.syntax() == Syntax.xml)
accum.append("<");
else
accum.append(c);
break;
case '>':
if (!inAttribute)
accum.append(">");
else
accum.append(c);
break;
case '"':
if (inAttribute)
accum.append(""");
else
accum.append(c);
break;
default:
if (canEncode(coreCharset, c, encoder))
accum.append(c);
else
appendEncoded(accum, escapeMode, codePoint);
}
} else {
final String c = new String(Character.toChars(codePoint));
if (encoder.canEncode(c)) // uses fallback encoder for simplicity
accum.append(c);
else
appendEncoded(accum, escapeMode, codePoint);
}
}
}
private static void appendEncoded(Appendable accum, EscapeMode escapeMode, int codePoint) throws IOException {
final String name = escapeMode.nameForCodepoint(codePoint);
if (!emptyName.equals(name)) // ok for identity check
accum.append('&').append(name).append(';');
else
accum.append("&#x").append(Integer.toHexString(codePoint)).append(';');
}
/**
* Un-escape an HTML escaped string. That is, {@code <} is returned as {@code <}.
*
* @param string the HTML string to un-escape
* @return the unescaped string
*/
public static String unescape(String string) {
return unescape(string, false);
}
/**
* Unescape the input string.
*
* @param string to un-HTML-escape
* @param strict if "strict" (that is, requires trailing ';' char, otherwise that's optional)
* @return unescaped string
*/
static String unescape(String string, boolean strict) {
return Parser.unescapeEntities(string, strict);
}
/*
* Provides a fast-path for Encoder.canEncode, which drastically improves performance on Android post JellyBean.
* After KitKat, the implementation of canEncode degrades to the point of being useless. For non ASCII or UTF,
* performance may be bad. We can add more encoders for common character sets that are impacted by performance
* issues on Android if required.
*
* Benchmarks: *
* OLD toHtml() impl v New (fastpath) in millis
* Wiki: 1895, 16
* CNN: 6378, 55
* Alterslash: 3013, 28
* Jsoup: 167, 2
*/
private static boolean canEncode(final CoreCharset charset, final char c, final CharsetEncoder fallback) {
// todo add more charset tests if impacted by Android's bad perf in canEncode
switch (charset) {
case ascii:
return c < 0x80;
case utf:
return true; // real is:!(Character.isLowSurrogate(c) || Character.isHighSurrogate(c)); - but already check above
default:
return fallback.canEncode(c);
}
}
enum CoreCharset {
ascii, utf, fallback;
static CoreCharset byName(final String name) {
if (name.equals("US-ASCII"))
return ascii;
if (name.startsWith("UTF-")) // covers UTF-8, UTF-16, et al
return utf;
return fallback;
}
}
private static void load(EscapeMode e, String pointsData, int size) {
e.nameKeys = new String[size];
e.codeVals = new int[size];
e.codeKeys = new int[size];
e.nameVals = new String[size];
int i = 0;
CharacterReader reader = new CharacterReader(pointsData);
try {
while (!reader.isEmpty()) {
// NotNestedLessLess=10913,824;1887&
final String name = reader.consumeTo('=');
reader.advance();
final int cp1 = Integer.parseInt(reader.consumeToAny(codeDelims), codepointRadix);
final char codeDelim = reader.current();
reader.advance();
final int cp2;
if (codeDelim == ',') {
cp2 = Integer.parseInt(reader.consumeTo(';'), codepointRadix);
reader.advance();
} else {
cp2 = empty;
}
final String indexS = reader.consumeTo('&');
final int index = Integer.parseInt(indexS, codepointRadix);
reader.advance();
e.nameKeys[i] = name;
e.codeVals[i] = cp1;
e.codeKeys[index] = cp1;
e.nameVals[index] = name;
if (cp2 != empty) {
multipoints.put(name, new String(new int[]{cp1, cp2}, 0, 2));
}
i++;
}
Validate.isTrue(i == size, "Unexpected count of entities loaded");
} finally {
reader.close();
}
}
}https://github.com/jhy/jsoup/blob/master/src/main/java/org/jsoup/nodes/Entities.java
GitHub - jhy/jsoup: jsoup: the Java HTML parser, built for HTML editing, cleaning, scraping, and XSS safety.
jsoup: the Java HTML parser, built for HTML editing, cleaning, scraping, and XSS safety. - GitHub - jhy/jsoup: jsoup: the Java HTML parser, built for HTML editing, cleaning, scraping, and XSS safety.
github.com
나와 동일한 오류로 고생중인 개발자도 있다
Caused by java.lang.NumberFormatException in CleaningUtils #805



