[Python] 파이썬 웹 크롤링 BeautifulSoup모듈을 사용하여 뉴스 긁어오기: HTML파싱(뉴스 제목, 날짜, 링크,이미지URL)
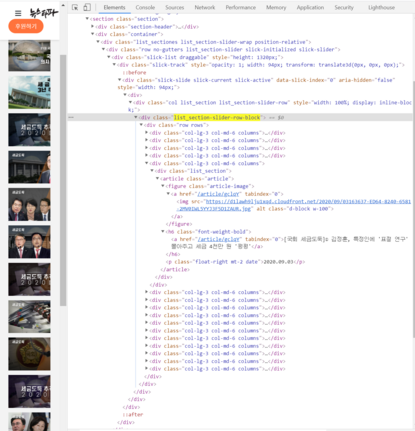
뉴스타파 사이트의 “세금도둑추적2020” 뉴스 크롤링을 시도해봅니다. 뉴스부분의 HTML을 파싱하기위해서 크롬 브라우저를 열고 newstapa.org 사이트를 열어요. 그리고 난 후 F12키를 눌러 개발자 도구를 사용합니다. 왼쪽에 커서버튼을 눌러 뉴스 하나를 선택하여, 뉴스를 감싸고 있는 최상의 div태그를 찾아요. 노란색 블럭된 부분이 바로 뉴스가 모여있는 태그입니다. 파싱할 대상을 찾았으니 이제 코딩을 시작해볼까요?
제일 먼저 BeautifulSoup모듈을 설치를 해야합니다. 명령프롬포트를 실행하거나 파이참 툴을 사용중이라면 하단 터미널(Terminal)창에서 설치명령어를 실행하면 됩니다.
설치 명령어는 다음과 같습니다.
pip install bs4[실행결과] 이미설치를 하였음으로 로그가 다르답니다.
C:pythonWorkspace>pip install bs4
Collecting bs4
Downloading bs4-0.0.1.tar.gz (1.1 kB)
Requirement already satisfied: beautifulsoup4 in c:usersilikeappdatalocalprogramspythonpython39libsite-packages (from bs4) (4.9.3)
Requirement already satisfied: soupsieve>1.2 in c:usersilikeappdatalocalprogramspythonpython39libsite-packages (from beautifulsoup4->bs4) (2.0.1)
Using legacy 'setup.py install' for bs4, since package 'wheel' is not installed.
Installing collected packages: bs4
Running setup.py install for bs4 ... done
Successfully installed bs4-0.0.1
C:pythonWorkspace>
requests 모듈과 BeautifulSoup모듈을 import하여 크롤링 작업을 할 수 있습니다. features인자 값으로 “html.parser”를 적용하였습니다. 인자값으로 “lxml”과 “html5lib”등도 사용할 수 있습니다.
import requests
from bs4 import BeautifulSoup
url = "https://newstapa.org"
request = requests.get('https://newstapa.org/tags/%EC%84%B8%EA%B8%88%EB%8F%84%EB%91%91%EC%B6%94%EC%A0%812020')
soup = BeautifulSoup(request.content, features="html.parser")
request.close()
# print(soup)
# find_str = soup.find('div', attrs={'class': 'col-lg-3 col-md-6 columns'})
find_str = soup.find('div', attrs={'class': 'list_section-slider-row-block'})
print(find_str)
for news in find_str.findAll('div', attrs={'class': 'col-lg-3 col-md-6 columns'}):
# print(news)
#print(news.find("h6", attrs={'class': 'font-weight-bold'}).text) # 기사 제목
print(news.h6.text) # 기사 제목
print(url + str(news.find("h6", attrs={'class': 'font-weight-bold'}).a['href']).strip()) # 기사 url
print(news.find("p", attrs={'class': 'float-right mt-2 date'}).text) # 기사 날짜
#print(news.find('figure', attrs={'class': 'article-image'}).img['src']) # 이미지 url
print(news.figure.img['src']) # 이미지 url[코드 실행결과]
'횡령범' 몰린 국회인턴, 경찰서 '무혐의'...검찰이 종결 안해 큰 고통
https://newstapa.org/article/3A5cw
2020.09.18
https://d1lawh9lju1xqd.cloudfront.net/2020/09/28170837-D98B-8F51-6B5E-1HAAXK4VI2Z1FPVFKKCH.jpg
21대 국회에 물었다..."국회개혁 의지 있나요"
https://newstapa.org/article/DeQ69
2020.09.18
https://d1lawh9lju1xqd.cloudfront.net/2020/09/28170800-77DB-98CE-F45B-U21HINT51J9BL0RGD515.jpg
국회세금도둑 3년 추적기-의원님과 인턴
https://newstapa.org/article/Mzp54
2020.09.17
https://d1lawh9lju1xqd.cloudfront.net/2020/09/24091518-3EF8-8217-B369-APRJ6UQPJI159AADCQOH.jpg
<국회세금도둑 추적 2020> 임기 끝났다고 ‘끝이 아니다’
https://newstapa.org/article/4kcdv
2020.09.03
https://d1lawh9lju1xqd.cloudfront.net/2020/09/03163746-A562-50B0-0A78-009SB47X3UMA4WNKHFXZ.jpg
[국회 세금도둑]① 김정훈, 특정인에 '표절 연구' 몰아주고 세금 4천만 원 '펑펑'
https://newstapa.org/article/gclqY
2020.09.03
https://d1lawh9lju1xqd.cloudfront.net/2020/09/03163637-ED64-8240-6581-2MV0IWL5YYJ3F5D1ZAUR.jpg
[국회 세금도둑]② 백재현 표절 정책연구 추가 확인, 박선숙・신창현은 반납
https://newstapa.org/article/Yh8H5
2020.09.03
https://d1lawh9lju1xqd.cloudfront.net/2020/09/03163544-A932-C98D-8A9E-208WE015XE5OFWHHOJWA.jpg
[국회 세금도둑]③ 조원진, 권석창, 김용태 '예산 오남용'...환수 방법 없어
https://newstapa.org/article/xJ9oo
2020.09.03
https://d1lawh9lju1xqd.cloudfront.net/2020/09/03163440-9435-F246-5D48-NQ9R3W4VHYLMMULHU96F.jpg
국회의 또 다른 혈세낭비...발간비와 여론조사
https://newstapa.org/article/Nea2a
2020.07.22
https://d1lawh9lju1xqd.cloudfront.net/2020/07/22143153-A034-60B9-0275-E3DHZNSNBTN6J2IY4L7B.jpg
[국회 세금도둑]① 국회의원 '발간비' 허위·과다 청구...혈세 낭비
https://newstapa.org/article/Vc-M3
2020.07.22
https://d1lawh9lju1xqd.cloudfront.net/2020/07/22145407-6F87-90F2-5EED-JLSMCJ28RVNK6TQ7IUMD.jpg
[국회 세금도둑]② 정책개발비로 의원 개인홍보 여론조사...국회규정 위반
https://newstapa.org/article/Q9kQ7
2020.07.22
https://d1lawh9lju1xqd.cloudfront.net/2020/07/22145853-D4B2-2FA5-018B-VUB35770OK2S2VMGMSF4.jpg
'국회 세금도둑 추적 2020'...여야 의원 7명 공개
https://newstapa.org/article/YQBUb
2020.07.14
https://d1lawh9lju1xqd.cloudfront.net/2020/07/14150254-D592-61C7-A50F-K7S100K0ZBDIJ35BS0KM.jpg
[국회 세금도둑]①김태흠·송옥주·이학영 정책연구 표절 인정...예산 반납하겠다
https://newstapa.org/article/gHQov
2020.07.14
https://d1lawh9lju1xqd.cloudfront.net/2020/07/14150109-3F86-CB5A-D8A5-UDWEJJY2VSA5JA4BVVFH.jpg
[국회 세금도둑]②임종성·어기구도 정책연구 표절...혈세 낭비 불감증
https://newstapa.org/article/N71gi
2020.07.14
https://d1lawh9lju1xqd.cloudfront.net/2020/07/14150149-424B-00D8-7A01-21AJL7R7GIW40PLE86I9.jpg
[국회 세금도둑]③'표절 질타' 이용호·이종배...표절 정책자료집 발간
https://newstapa.org/article/whRn8
2020.07.14
https://d1lawh9lju1xqd.cloudfront.net/2020/07/14150233-6141-2971-3FBF-TTPQ0UO16AXXE590V844.jpg
'국회 세금도둑 추적 2020'...국회예산 이렇게 샜다
https://newstapa.org/article/obolG
2020.06.04
https://d1lawh9lju1xqd.cloudfront.net/2020/06/03195606-F13F-2CBB-F508-53ZHENTLVZVDKBCALOXE.jpg
[국회 세금도둑]① 정책용역보고서 천여 건 입수...혈세 낭비 또 확인
https://newstapa.org/article/RIIhW
2020.06.04
https://d1lawh9lju1xqd.cloudfront.net/2020/06/04103153-B215-BFE8-A7F7-TPNDJ03CKJ3RZ7GS57MS.jpg
Process finished with exit code 0
위와 같은 방법으로 웹 크롤링을 하여 앱을 만들 수도 있어요. 그러나 웹사이트가 개편되는 경우가 종종 있음으로 사이트가 개편되면 번거로운 일이 발생하죠. 웹 크롤링 작업을 다시 해야합니다.
웹사이트의 이미지 다운로드 하는 방법
위에서 이미 모든 작업을 끝냈음으로, 우리는 이미지 경로를 알고 있습니다. urlib.request 모듈을 임포트 후 urlretrieve()함수를 사용하여 다운로드가 가능합니다.
urlretrieve(이미지 경로 url, 로컬에 저장될 파일이름(폴더 지정 가능) )
from urllib.request import urlretrieve
try:
url = "https://d1lawh9lju1xqd.cloudfront.net/2020/09/03163637-ED64-8240-6581-2MV0IWL5YYJ3F5D1ZAUR.jpg"
urlretrieve(url, "C:/python/Workspace/downimg.jpg")
except Exception as e:
print("-" * 30)
print("- 이미지 다운로드 실패")
print("-" * 30)
else:
print("-" * 30)
print("- 이미지 다운로드 성공")
print("-" * 30)모든 이미지를 리스트에 담은 후 for문을 돌려서 전체 다운받기도 가능 하겠죠??
[REFERENCE]
github.com/hwangyoungjae/study/blob/master/20170117.py
zetcode.com/python/beautifulsoup/
github.com/hwangyoungjae/study/blob/master/20170118.py
docs.python.org/3/library/urllib.request.html
velog.io/@shchoice/urllib.request-urlretrieve-urlopen
[참고하면 유용할 사이트]
hleecaster.com/python-web-crawling-with-beautifulsoup/
[파이썬 더 알아보기]
[프로그래밍/Python] – [Python] 파이썬 BeautifulSoup 설치 오류시 해결 방법 : os.system(), pip install beautifulsoup4
[프로그래밍/Python] – [Python] 파이썬 싱글 쓰레드(Single Thread)와 멀티 쓰레드(multi Thread) 사용 예제 및 개념 이해하기
[프로그래밍/Python] – [Python] 파이썬 날짜 시간 계산 , 날짜 및 시간 표기법 예제 및 총정리 : datetime, timedelta
[프로그래밍/Python] – [Python] 파이썬 기본(기초) 문법 : 예제 및 총정리



