[Python] 파이썬 h5py 설치 및 사용방법 알아보기 : HDF5 예제
Hierarchical Data Format 는 매우 크고 복잡한 대용량 데이터를 저장하기 위한 파일 형식(HDF4, HDF5)입니다. 파일 확장자는 hdf5 또는 h5입니다.
HDF5의 가장 큰 특징은 빅데이터 처리시 유용하며, 빠른 입출력(IO)을 지원합니다. numpy 모듈을 사용하여 hdf5 데이터에 접근할 수 있습니다.
HDF5는 그룹(Group), 데이터셋(Dataset), 속성(attirbute)으로 구성됩니다.
HDF5 파일을 생성시, 루트 그룹(/)이 생성됩니다. 그리고 그 하위에 트리 구조로 다른 그룹을 생성할 수 있습니다. 하위 그룹에는 또 다른 그룹을 생성할 수도 있으며, 데이터셋이 존재할 수 도 있습니다. 디렉토리와 파일 구조를 생각하면 이해하기 쉽습니다.
HDF5 사용을 위한 h5py 설치하기
명령프롬프트창(cmd)을 열고 pip install h5py 명령어를 실행하여 설치합니다.
C:>pip install h5py
Collecting h5py
Downloading h5py-3.1.0-cp39-cp39-win_amd64.whl (2.7 MB)
|████████████████████████████████| 2.7 MB 6.8 MB/s
Requirement already satisfied: numpy>=1.19.3 in c:usersilikeappdatalocalprogramspythonpython39libsite-packages (from h5py) (1.19.3)
Installing collected packages: h5py
Successfully installed h5py-3.1.0
WARNING: You are using pip version 20.3.1; however, version 20.3.3 is available.
You should consider upgrading via the 'c:usersilikeappdatalocalprogramspythonpython39python.exe -m pip install --upgrade pip' command.
C:>
이미 설치를 하셨을 경우, 최신버전이 출시되었다면 –upgrade 옵션을 주고 업그레이드를 할 수 있습니다.
pip install h5py –upgrade
C:>pip install h5py --upgrade
Requirement already satisfied: h5py in c:usersilikeappdatalocalprogramspythonpython39libsite-packages (3.1.0)
Requirement already satisfied: numpy>=1.19.3 in c:usersilikeappdatalocalprogramspythonpython39libsite-packages (from h5py) (1.19.3)
파이참 IDE를 사용중인 경우에는 마우스 커서를 올리면 install package h5py를 클릭하여 설치할 수 있습니다.

생성한 hdf5파일은 별도의 프로그램을 실행하여 파일의 내용을 볼 수 있으며, HDFVIEW를 제공합니다. 윈도우10 운영체제의 경우 아래 경로에서 64HDFView-3.1.0-win10vs15_64.zip 파일을 다운받으신 후 압축을 풀고, 설치하세요. 압축파일의 크기는 약 200메가 정도 됩니다.
리눅스 centos7, osx1013, 윈도우7, 윈도우10 등의 운영체제별로 다운로드를 제공합니다.
support.hdfgroup.org/ftp/HDF5/releases/HDF-JAVA/hdfview-3.1/bin/
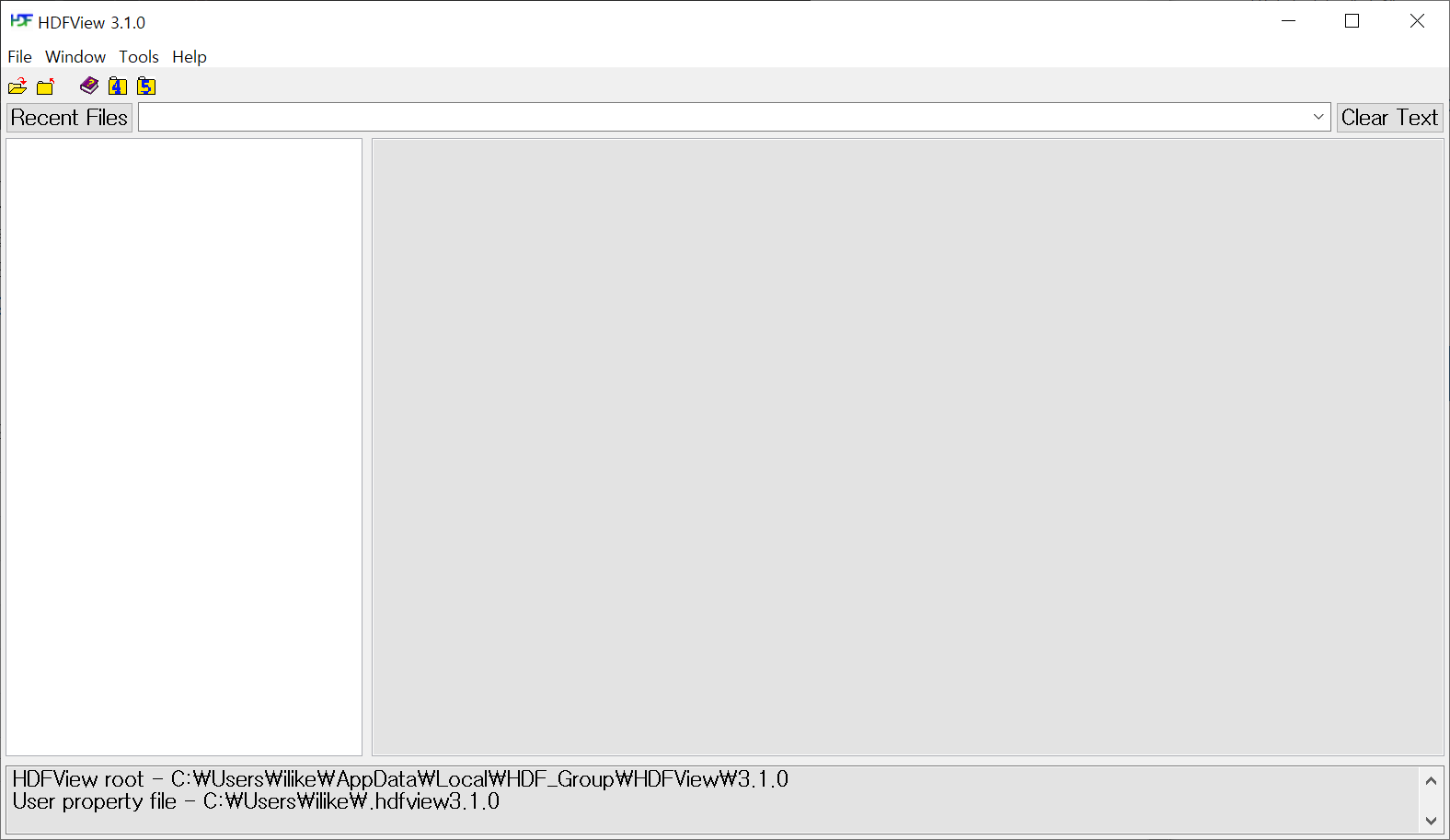
hdf5파일 생성
h5py 모듈을 임포트 후 File()메서드를 사용하여 파일 생성을 시작합니다. ‘w’는 파일에 쓸 때 사용하는 옵션으로 기존 파일이 있을 경우 덮어쓰기합니다. 추가가 필요한경우 ‘a’ 옵션을 사용합니다.
import h5py
file = h5py.File('test_hdf5.hdf5', 'w')
그룹 생성
create_group() 메서드를 사용하여 그룹을 생성하게 됩니다. 그룹은 하나씩 생성해도 되며, 여러개의 그룹을 한번에 생성할 수 도 있습니다. 존재하지 않는 그룹에 create_group()메서드를 사용하여 그룹을 추가하려는 경우 KeyError: “Unable to open object (object ‘c’ doesn’t exist)” 가 발생합니다. 그룹을 추가하기전에 keys()메서드를 사용하여 키의 존재를 파악해보세요.
import h5py
file = h5py.File('test_hdf5.hdf5', 'w') # 'a'
#그룹에 추가하는 방법
file.create_group("a")
#여러 그룹을 동시에 추가하는 방법
file.create_group("b/c")
#기존 그룹에 추가하는 또 다른 방법 1
file["a"].create_group("d")
file["b"].create_group("f")
#C라는 그룹이 없음으로 오류 발생
#file["c"].create_group("g/h/i")
#기존 그룹에 추가하는 또 다른 방법 2
g = file.create_group("a")
gg = g.create_group("sub")
#키값 출력
print(file.keys())
print(g.keys())
print(gg.keys())
#실행결과
<KeysViewHDF5 ['a', 'b']>
<KeysViewHDF5 ['d', 'sub']>
<KeysViewHDF5 []>
HDFVIEW 프로그램을 실행하여 지금까지에 대한 정보를 확인해봅니다. File메뉴나 파일 오픈 아이콘을 클릭하여 파일을 불러옵니다. 파일에 변화가 발생할 때 마다 매번 불러오기를 할 필요는 없으며, 파일명 위에 마우스 오른쪽 버튼을 클릭하면 Reload File메뉴가 있으니 클릭하여 갱신하면 됩니다.
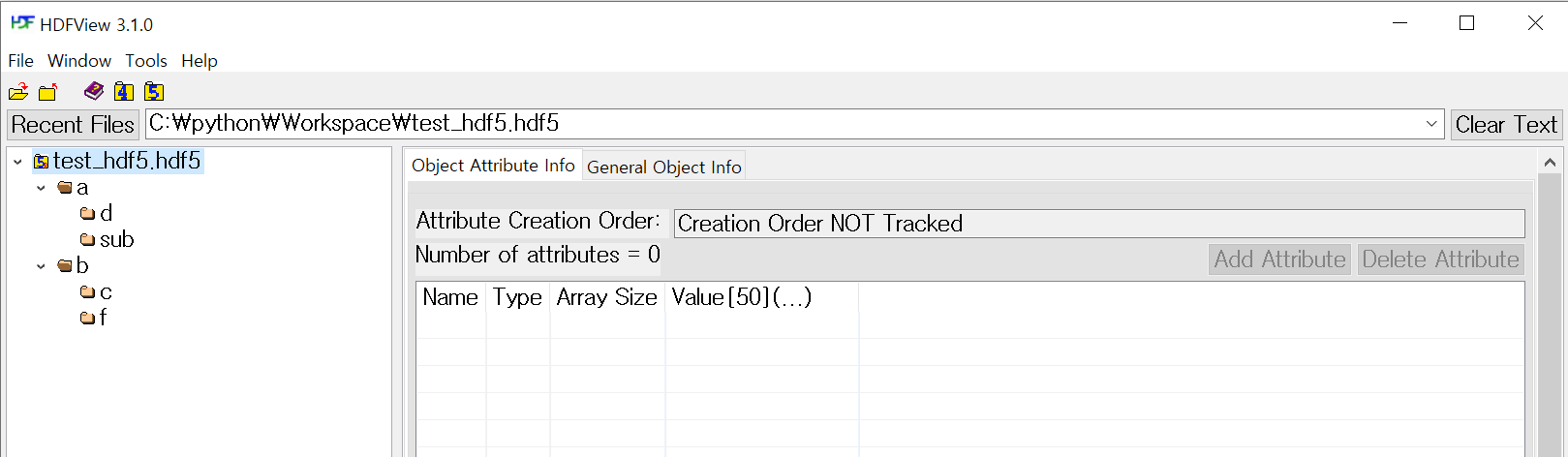
그룹 속성 추가
생성된 그룹에 attrs()메서드를 사용하여 속성을 추가할 수 있습니다. HDF5의 가장 큰 장점 중 하나가 그룹과 데이터셋에 대한 부연 설명을 사용자가 원하는 방향으로 메타 데이터 속성으로 지정할 수 있다는 점이라고 합니다. 속성의 자료형은 튜플(tuple) 타입입니다.
gg.attrs['message'] = "Hello Python!!"
gg.attrs['dt'] = "2020.12.30"
print(gg.attrs['message'])
print(gg.attrs.keys())
#속성의 키와 값을 출력해보기
print(f'-----속성의 키와 값을 출력해보기-----')
for key in gg.attrs.keys():
print(f'{key}: {gg.attrs[key]}')
#속성의 값만 표기
print(f'nn-----속성의 값만 출력해보기-----')
for value in gg.attrs.values():
print(f'{value}')
print(f'nn-----속성의 자료형 체크 해보기-----')
for value in gg.attrs.items():
print(f'자료형: {type(value)}, 출력:{value}')
print(f'nn---------------------------')
for key, value in gg.attrs.items():
print(f'{key}: {value}')
#실행결과
<KeysViewHDF5 ['dt', 'message']>
-----속성의 키와 값을 출력해보기-----
dt: 2020.12.30
message: Hello Python!!
-----속성의 값만 출력해보기-----
2020.12.30
Hello Python!!
-----속성의 자료형 체크 해보기-----
자료형: <class 'tuple'>, 출력:('dt', '2020.12.30')
자료형: <class 'tuple'>, 출력:('message', 'Hello Python!!')
---------------------------
dt: 2020.12.30
message: Hello Python!!
HDFVIEW 프로그램을 실행하여 속성까지 추가한 정보를 확인해봅니다.
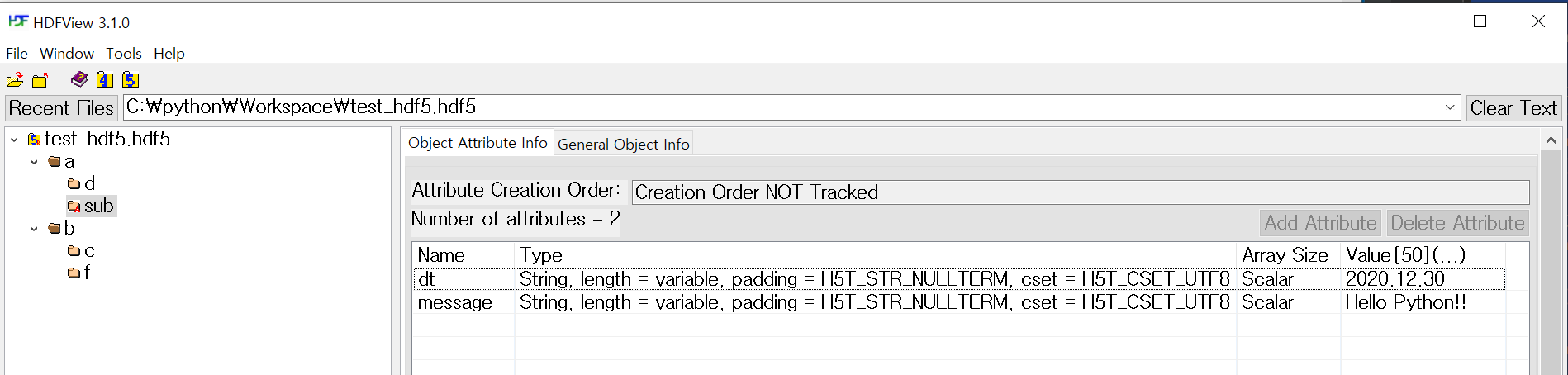
데이터셋 추가
그룹에 데이터셋을 추가하기위해 create_dataset()메서드를 사용합니다. 또는 직접 데이터를 지정하여 데이터셋을 추가할 수 있습니다. 데이터셋에 대한 참조는 File객체에 구분자를 사용하여 데이터셋과 그룹과 접근할 수 있어요. 데이터셋 객체의 정보는 name(), shape(), dtype()메서드를 통하여 확인이 가능합니다. 데이터 셋 객체의 데이터에 접근하는 방법은 리스트 접근 방법과 동일합니다.
dt = g.create_dataset("test", data=np.arange(30))
g['sub2'] = np.arange(15)
print(f'dt: {dt.name}')
print(f'dt: {dt.shape}')
print(f'dt: {dt.dtype}')
print(f'dt: {dt[1:10]}')
# 데이터셋의 값의 변경하기
dt[1] = 100
dt[2:10] = -1.5
#데이터셋 값 출력
print(dt[:])
#실행결과
dt: /a/test
dt: (30,)
dt: int32
dt: [1 2 3 4 5 6 7 8 9]
[ 0 100 -1 -1 -1 -1 -1 -1 -1 -1 10 11 12 13 14 15 16 17
18 19 20 21 22 23 24 25 26 27 28 29]
#데이터셋에 접근하기
c = file['/a/sub2']
print(c)
c = gg['/a/test']
print(c)
#실행결과
<HDF5 dataset "sub2": shape (15,), type "<i4">
<HDF5 dataset "test": shape (30,), type "<i4">HDFVIEW 프로그램을 실행하여 그룹, 속성, 데이터 셋까지 추가된 정보를 확인해봅니다. 왼쪽의 디렉토리와 같은 구조에서 데이터 셋을 클릭하면 데이터를 확인할 수 있습니다.
sqlite3 데이터베이스를 사용하여 조회한 결과를 hdf파일로 저장할 수도 있습니다.
import sqlite3
import pandas as pd
import tables
conn = sqlite3.connect("C:pythondatabasecustomer_database.db", isolation_level=None)
df = pd.read_sql_query("SELECT * FROM TB_USER_INFO", conn)
#print(df)
df.to_hdf('sql_test_hdf5.hdf5', key='test', mode='w')tables모듈이 없을 경우 ImportError: Missing optional dependency 'tables'. Use pip or conda to install tables. 오류가 발생합니다. pip install tables 명령어를 실행하여 설치합니다. pandas 모듈 I/O 처리에 대한 자세한 정보는 아래 링크를 참고하세요.
pandas.pydata.org/pandas-docs/stable/user_guide/io.html
IO tools (text, CSV, HDF5, …) — pandas 1.2.0 documentation
The pandas I/O API is a set of top level reader functions accessed like pandas.read_csv() that generally return a pandas object. The corresponding writer functions are object methods that are accessed like DataFrame.to_csv(). Below is a table containing av
pandas.pydata.org
support.hdfgroup.org에서는 아래와 같은 파이썬 HDF5 예제 코드를 함께 제공하고 있습니다. 자바나 다른 언어들에 대한 예제 코드도 제공하고 있으니 필요하신분은 사이트를 방문해보세요.
| Create a dataset | h5_crtdat.py |
| Read and write to a dataset | h5_rdwt.py |
| Create an attribute | h5_crtatt.py |
| Create a group | h5_crtgrp.py |
| Create groups in a file using absolute and relative paths | h5_crtgrpar.py |
| Create datasets in a group | h5_crtgrpd.py |
| Create a chunked and compressed dataset | h5_cmprss.py |
HDF5 TUTORIAL
support.hdfgroup.org/HDF5/Tutor/index.html
[REFERENCE]
공학자를 위한 Python : wikidocs.net/book/1704
docs.h5py.org/en/stable/quick.html
jehoons.github.io/hdf5-format/
stackoverflow.com/questions/22935030/convert-python-sqlite-db-to-hdf5
[관련 사이트]
About the NeXus Data Format · NeXus
About the NeXus Data Format NeXus is a common data format for neutron, x-ray, and muon science. It is being developed as an international standard by scientists and programmers representing major scientific facilities in order to facilitate greater coopera
www.nexusformat.org
HDF5 for Python
About the project The h5py package is a Pythonic interface to the HDF5 binary data format. It lets you store huge amounts of numerical data, and easily manipulate that data from NumPy. For example, you can slice into multi-terabyte datasets stored on disk,
www.h5py.org



