[Python]파이썬 테서랙트(Tesseract OCR) 설치 및 사용방법 총정리 : 이미지에서 문자 텍스트 추출하는 방법
지난 6월 8일 애플 WWDC 2021 전세계 개발자 회의에서 애플은 OCR 기능을 선보였습니다. 강의 영상을 사진으로 찍은 후 바로 문서화 하거나 또는 길거리 간판에서 사진을 찍은 후 사진속의 전화번호를 클릭하여 바로 전화로 연결하는 기능을 보여주었습니다. 애플이 테서랙트 OCR를 사용했다는 것은 아닙니다. 누구나 다 아는 OCR의 특성을 한 걸음 더 들어가 스마트폰의 기능으로 구현것에 대한 박수를 보냅니다. 전 직장에서 OCR관련하여 안드로이드로 개발시 테서랙트 OCR 라이브러리를 사용하여 개발 및 테스트를 진행했었는데, 왜 난 저런 생각을 못했을까요? 아마도 핑계를 대자면 한글 인식률이 너무 떨어져서 프로젝트를 중간에 접어서 그랬을까요? 테서랙트 OCR를 사용하게 되면 서버 특정위치에 이미지 파일이 저장됨으로 주기적으로 삭제하는 스케줄러를 등록해야합니다. 그 정보가 개인정보라면 더더욱 문제가 발생하기 때문에 주의를 요합니다. 오늘은 그런 테스랙트를 파이썬 언어에서 이용해보는 방법에 대해 알아봅니다.
Tesseract OCR 이란?
테서랙트(Tesseract)는 Apache 2.0 라이선스에 따라 사용할 수 있는 오픈 소스 텍스트 인식 (Open Source OCR
) 엔진 입니다. Tesseract는 유니 코드 (UTF-8)를 지원 하며 100개 이상의 언어를 지원합니다. 사용시 단점으로 GPU지원을 하지 않으며, 속도가 느린편입니다. 테서랙트 OCR 사용시 유의사항은 본문 아래쪽 내용을 참고하세요.
Source Repository: https://github.com/tesseract-ocr/tesseract
파이썬 테서랙트란?
Python-tesseract는 Google의 Tesseract-OCR Engine을 래핑한 라이브러리입니다. jpeg, png, gif, bmp, tiff 등을 포함하여 Pillow 및 Leptonica 이미징 라이브러리에서 지원하는 모든 이미지 유형을 읽을 수 있으므로 tesseract에 대한 독립 실행 형 호출 스크립트로도 유용합니다. 또한 스크립트로 사용되는 경우 Python-tesseract는 인식 된 텍스트를 파일에 쓰는 대신 인쇄합니다.
문자 추출을 위한 사전 설치 작업
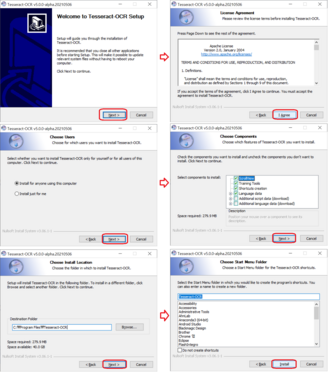
1. 테서랙트 다운로드(https://github.com/UB-Mannheim/tesseract/wiki) 및 설치
위 사이트를 방문하여 본인이 사용하는 PC의 운영체제에 맞게 설치합니다. 윈도우 사용자라면 아래 링크 클릭하여 설치파일을 다운로드 하세요. 설치파일의 용량은 50메가입니다.
- tesseract-ocr-w64-setup-v5.0.0-alpha.20210506.exe (64 bit) resp.
설치하지않은 상태에서 pytesseract 모듈만 설치 후 테스트 코드를 실행하게 되면 아래와 같이 pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH. See README file for more information. 오류가 발생하니, 반드시 설치해야합니다.
Traceback (most recent call last):
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespytesseractpytesseract.py", line 255, in run_tesseract
proc = subprocess.Popen(cmd_args, **subprocess_args())
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsubprocess.py", line 947, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsubprocess.py", line 1416, in _execute_child
hp, ht, pid, tid = _winapi.CreateProcess(executable, args,
FileNotFoundError: [WinError 2] 지정된 파일을 찾을 수 없습니다
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:pythonWorkspacemain.py", line 6, in <module>
OCR_text = pytesseract.image_to_string(Image.open('c:/python/ocr/lotto.jpg'), lang='kor')
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespytesseractpytesseract.py", line 409, in image_to_string
return {
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespytesseractpytesseract.py", line 412, in <lambda>
Output.STRING: lambda: run_and_get_output(*args),
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespytesseractpytesseract.py", line 287, in run_and_get_output
run_tesseract(**kwargs)
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespytesseractpytesseract.py", line 259, in run_tesseract
raise TesseractNotFoundError()
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH. See README file for more information.
그럼에도 불구하고 여전히 설치경로를 찾지 못해서 오류가 발생한다면 윈도우 환경변수에 설치경로를 지정하거나 스크립트 실행시 설치경로를 코드상에 지정하는 방법이 있습니다. 자세한 방법은 아래 포스팅을 참고하여 설정하세요.
[오류 해결 방법]pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH
테서랙트 OCR를 설치 후 코드 실행히 pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH와 같은 오류가 발생한다. Traceback (most recent call last): File..
playground.naragara.com
2. 파이썬에서 이미지 처리를 위해 pillow모듈을 설치합니다. 자세항 사용법 및 설치 방법은 아래 포스팅을 참고하세요.
[Python] 파이썬 이미지 처리 pillow(PIL) 설치 및 사용 예제 총정리:드루와
이미지 분석 및 처리를 쉽게 할 수 있는 라이브러리(Python Imaging Library : PIL)가 있습니다. 바로 pillow모듈입니다. 다양한 이미지 파일 형식을 지원하며, 강력한 이미지 처리와 그래픽 기능을 제공하
playground.naragara.com
3.pip install 명령어를 사용하여 pytesseract모듈을 설치합니다. 명령프롬프트(cmd)창을 열고 pip install pytesseract 명령어를 실행하여 설치하면되고, 파이참IDE를 사용중이라면 하단의 터미널(Terminal)창에서 명령어를 실행하세요.
| pip install pytesseract 실행 시 설치 로그 |
| Microsoft Windows [Version 10.0.19042.1052] (c) Microsoft Corporation. All rights reserved. C:>pip install pytesseract |
4. 한글 문자 인식 추출 기능을 테스트한다면??
pytesseract.pytesseract.TesseractError: (1, 'Error opening data file C:Program FilesTesseract-OCR/tessdata/kor.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language 'kor' Tesseract couldn't load any languages! Could not initialize tesseract.')오류가 발생합니다.
C:UsersilikeAppDataLocalProgramsPythonPython39python.exe C:/python/Workspace/main.py
Traceback (most recent call last):
File "C:pythonWorkspacemain.py", line 8, in <module>
OCR_text = pytesseract.image_to_string(Image.open('c:/python/ocr/lotto.jpg'), lang='Hangul')
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespytesseractpytesseract.py", line 409, in image_to_string
return {
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespytesseractpytesseract.py", line 412, in <lambda>
Output.STRING: lambda: run_and_get_output(*args),
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespytesseractpytesseract.py", line 287, in run_and_get_output
run_tesseract(**kwargs)
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespytesseractpytesseract.py", line 263, in run_tesseract
raise TesseractError(proc.returncode, get_errors(error_string))
pytesseract.pytesseract.TesseractError: (1, 'Error opening data file C:Program FilesTesseract-OCR/tessdata/Hangul.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language 'kor' Tesseract couldn't load any languages! Could not initialize tesseract.')
Process finished with exit code 1
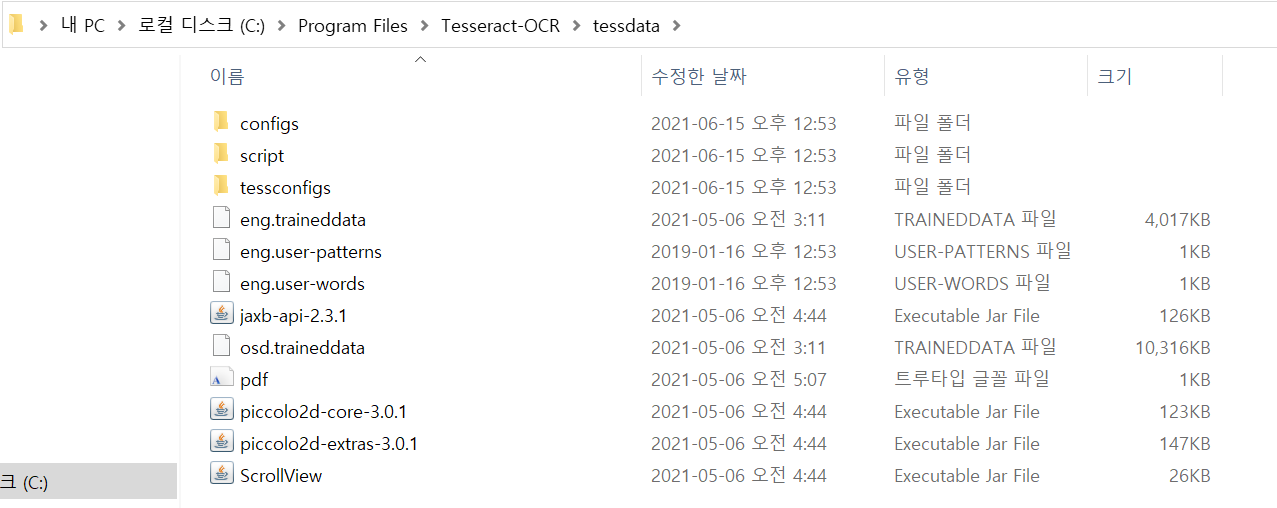
한글인식을 위해 학습된 Hangul.traineddata 파일이 필요한데 없어서 발생하는 오류입니다. 테스랙트 윈도우용 프로그램 설치시 기본적으로 영문 데이터 파일만 존재하기 때문에 발생됩니다. 오류 해결을 위해 학습된 한글 데이터 파일을 다운받아야합니다. 아래 사이트에서 다운받으세요.
| 다운로드 경로 |
| 깃허브 : https://github.com/tesseract-ocr/tessdata |
| 다운받아야하는 학습된 한글 데이터 파일명: kor.traineddata |
다운받은 파일은 테서랙트가 설치된 경로의 C:Program FilesTesseract-OCRtessdata 폴더에 복사해줍니다.
OCR기능 구현 테스트를 위한 모든 준비는 끝났습니다. 코드 테스트를 시작해볼까요?
테서랙트 라이브러리 사용방법 샘플 코드를 제공합니다.(https://github.com/madmaze/pytesseract)
try:
from PIL import Image
except ImportError:
import Image
import pytesseract
# If you don't have tesseract executable in your PATH, include the following:
pytesseract.pytesseract.tesseract_cmd = r'<full_path_to_your_tesseract_executable>'
# Example tesseract_cmd = r'C:Program Files (x86)Tesseract-OCRtesseract'
# Simple image to string
print(pytesseract.image_to_string(Image.open('test.png')))
# List of available languages
print(pytesseract.get_languages(config=''))
# French text image to string
print(pytesseract.image_to_string(Image.open('test-european.jpg'), lang='fra'))
# In order to bypass the image conversions of pytesseract, just use relative or absolute image path
# NOTE: In this case you should provide tesseract supported images or tesseract will return error
print(pytesseract.image_to_string('test.png'))
# Batch processing with a single file containing the list of multiple image file paths
print(pytesseract.image_to_string('images.txt'))
# Timeout/terminate the tesseract job after a period of time
try:
print(pytesseract.image_to_string('test.jpg', timeout=2)) # Timeout after 2 seconds
print(pytesseract.image_to_string('test.jpg', timeout=0.5)) # Timeout after half a second
except RuntimeError as timeout_error:
# Tesseract processing is terminated
pass
# Get bounding box estimates
print(pytesseract.image_to_boxes(Image.open('test.png')))
# Get verbose data including boxes, confidences, line and page numbers
print(pytesseract.image_to_data(Image.open('test.png')))
# Get information about orientation and script detection
print(pytesseract.image_to_osd(Image.open('test.png')))
# Get a searchable PDF
pdf = pytesseract.image_to_pdf_or_hocr('test.png', extension='pdf')
with open('test.pdf', 'w+b') as f:
f.write(pdf) # pdf type is bytes by default
# Get HOCR output
hocr = pytesseract.image_to_pdf_or_hocr('test.png', extension='hocr')
# Get ALTO XML output
xml = pytesseract.image_to_alto_xml('test.png')
OpenCV 이미지 / NumPy 배열 객체 지원
import cv2
img_cv = cv2.imread(r'/<path_to_image>/digits.png')
# By default OpenCV stores images in BGR format and since pytesseract assumes RGB format,
# we need to convert from BGR to RGB format/mode:
img_rgb = cv2.cvtColor(img_cv, cv2.COLOR_BGR2RGB)
print(pytesseract.image_to_string(img_rgb))
# OR
img_rgb = Image.frombytes('RGB', img_cv.shape[:2], img_cv, 'raw', 'BGR', 0, 0)
print(pytesseract.image_to_string(img_rgb))
oem / psm과 같은 사용자 정의 구성(custom)이 필요한 경우 config 키워드를 사용
# Example of adding any additional options
custom_oem_psm_config = r'--oem 3 --psm 6'
pytesseract.image_to_string(image, config=custom_oem_psm_config)
# Example of using pre-defined tesseract config file with options
cfg_filename = 'words'
pytesseract.run_and_get_output(image, extension='txt', config=cfg_filename)
import cv2
import sys
import pytesseract
if len(sys.argv) < 2:
print('Usage: python ocr')
sys.exit(1)
# Read image path from command line
imPath = sys.argv[1]
# Define config parameters.
# '-l eng' for using the English language
# '--oem 1' sets the OCR Engine Mode to LSTM only.
config = ('-l eng --oem 1 --psm 3')
# Read image from disk
im = cv2.imread(imPath, cv2.IMREAD_COLOR)
#im = cv2.imread(imPath, cv2.COLOR_BGR2GRAY)
# Run tesseract OCR on image
text = pytesseract.image_to_string(im, config=config)
# Print recognized text
print(text)
datafile 오픈 오류 발생시 config 추가
# Example config: r'--tessdata-dir "C:Program Files (x86)Tesseract-OCRtessdata"'
# It's important to add double quotes around the dir path.
tessdata_dir_config = r'--tessdata-dir "<replace_with_your_tessdata_dir_path>"'
pytesseract.image_to_string(image, lang='chi_sim', config=tessdata_dir_config)
이미지에서 텍스트 추출하는 가장 기본적인 샘플 코드
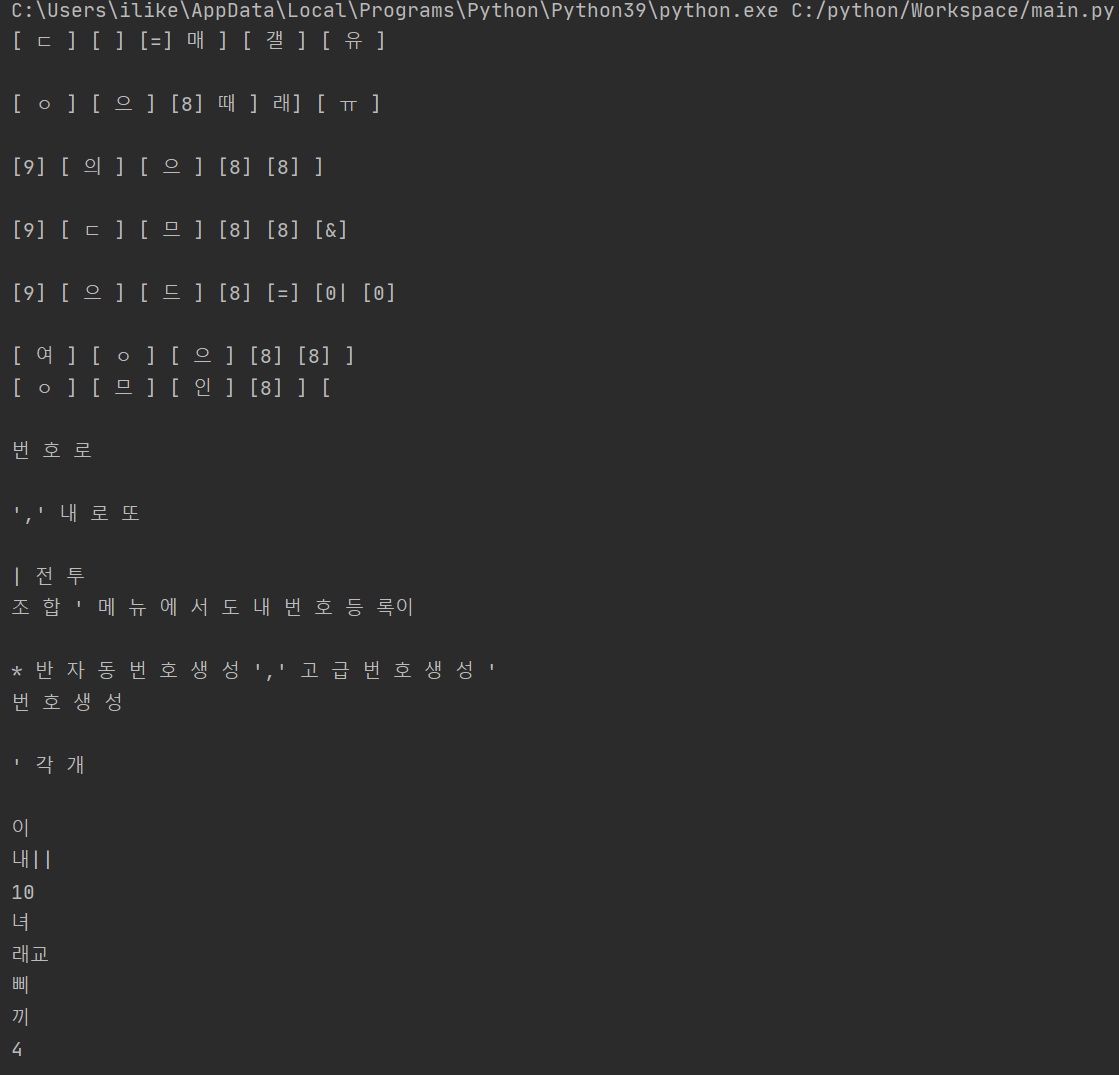
샘플 이미지 정보 : lotto.jpg

from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = R'C:Program FilesTesseract-OCRtesseract'
str = pytesseract.image_to_string(Image.open('c:/python/ocr/lotto.jpg'), lang='kor')
print(str)[실행결과]
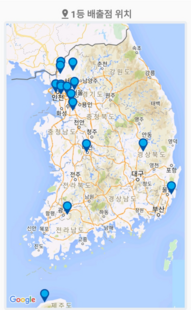
<두번째 테스트 샘플 이미지>
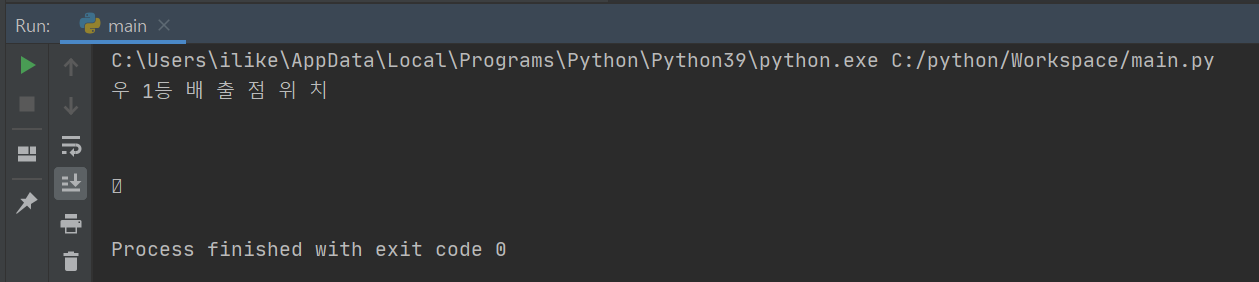
구글 지도 위에 표기된 시도 단위에 대한 한글 인식 기능을 테스트하였습니다.
[실행결과]
지도 안에 표기된 텍스트에 대한 인식률은 0%입니다.
<네번째 테스트 샘플 이미지>

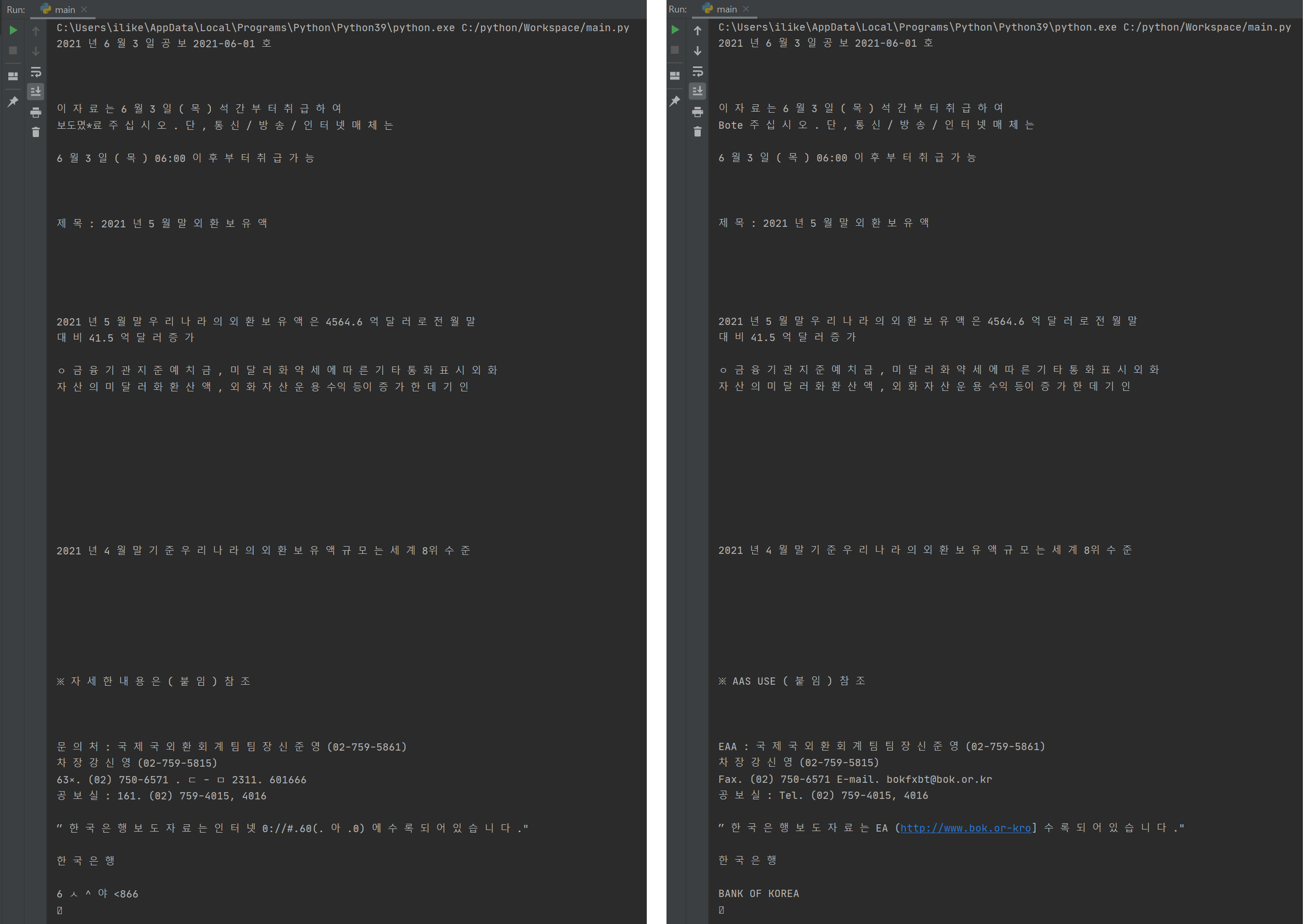
영어와 한글 등 여러개의 언어를 동시에 인식하게 하여 추출할 경우 lang 파라미터 값에 추출하고자 하는 언어를 "+"기호를 사용하여 추가해줍니다.
from PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = R'C:Program FilesTesseract-OCRtesseract'
str = pytesseract.image_to_string(Image.open('c:/python/ocr/news.jpg'), lang='kor+eng')
print(str)
[실행결과]
왼쪽은 한글만 오른쪽은 한글+영어의 결과 입니다.
OCR 인식률 개선을 위한 이미지 전처리 방법
이미지에서 텍스트에 대한 인식률을 높이기 위해 OpenCV 라이브러리를 사용해봅니다.
opencv라이브러리 사용을 위해서는 pip install opencv-python 명령어를 실행하여 모듈을 설치합니다.
C:>pip install opencv-python
Collecting opencv-python
Downloading opencv_python-4.5.2.54-cp39-cp39-win_amd64.whl (34.7 MB)
|████████████████████████████████| 34.7 MB 6.4 MB/s
Requirement already satisfied: numpy>=1.19.3 in c:usersilikeappdatalocalprogramspythonpython39libsite-packages (from opencv-python) (1.19.3)
Installing collected packages: opencv-python
Successfully installed opencv-python-4.5.2.54
원본 이미지의 그레이 처리 작업 후 문자열 추출 테스트
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd = R'C:Program FilesTesseract-OCRtesseract'
imPath = 'c:/python/ocr/lotto.jpg'
# Define config parameters.
# '-l eng' for using the English language
# '--oem 1' sets the OCR Engine Mode to LSTM only.
#config = ('-l kor --oem 1 --psm 3')
config = ('-l kor+eng --oem 3 --psm 4')
# Read image from disk
#img = cv2.imread(imPath, cv2.IMREAD_COLOR)
img = cv2.imread(imPath, 1)
cv2.imshow("orignal", img)
text = pytesseract.image_to_string(img, config=config)
print(text)
print('이미지 그레이처리')
img_gray = cv2.imread(imPath, cv2.COLOR_BGR2GRAY)
img_gray = cv2.imread(imPath, cv2.IMREAD_GRAYSCALE)
cv2.imshow("grayscale", img_gray)
print(pytesseract.image_to_string(img_gray, config=config))
cv2.waitKey(0)
cv2.destroyAllWindows()[실행결과]
배달의민족에서 제공하는 폰트를 사용한 텍스트의 인식률은 거의 0%에 가깝습니다.
| 원본 이미지 문자열 추출결과 | 이미지 전처리 작업(그레이 스케일) 후 추출결과 |
| Hos 선 택 하 세 요 .
aaa] * 반 자 동 번 호 MA! ' 고 급 번 호 생 성 ',
|
번 호 를 선 택 하 세 요 .
시 2 벽 ee = ㅣ
* 반 자 동 번 호 YA ' 고 급 번 호 생 성 ', |

어떤 경우에는 한글(config = ('-l kor --oem 3 --psm 4'))만 추출하는 경우 인식률이 높은 경우도 발생했고, 한글과 영어(config = ('-l kor+eng --oem 3 --psm 4'))를 동시에 추출하는 경우에 인식률이 높은 경우도 발생했다.
더 많은 임계 처리 방법은 아래 글을 참고하세요.
이미지 임계 처리 방법
이미지 임계처리 — gramman 0.1 documentation
기본 임계처리 이진화 처리는 간단하지만, 쉽지 않은 문제를 가지고 있다. 이진화란 영상을 흑/백으로 분류하여 처리하는 것을 말합니다. 이때 기준이 되는 임계값을 어떻게 결정할 것인지가 중
opencv-python.readthedocs.io
OpenCV: Image Thresholding
Goal In this tutorial, you will learn simple thresholding, adaptive thresholding and Otsu's thresholding. You will learn the functions cv.threshold and cv.adaptiveThreshold. Simple Thresholding Here, the matter is straight-forward. For every pixel, the sam
docs.opencv.org
테서랙트 OCR 사용시 유의사항
Tesseract에서 좋은 품질의 결과물을 얻지 못하는 여러 가지 이유가 있습니다.
1. 이미지 처리(Image processing)
Tesseract는 실제 OCR을 수행하기 전에 내부적으로 다양한 이미지 처리 작업을 수행합니다.(Leptonica 라이브러리 사용). 일반적으로이 작업을 매우 잘 수행하지만 필연적으로 충분하지 않은 경우가있어 정확도가 크게 저하 될 수 있습니다.
2. 이미지 반전(Inverting images)
tesseract 버전 3.05 (및 이전)는 문제없이 반전 된 이미지 (어두운 배경 및 밝은 텍스트)를 처리하지만 4.x 버전의 경우 밝은 배경에 어두운 텍스트를 사용합니다.
3. 크기 조정(Rescaling)
Tesseract는 DPI가 300dpi 이상인 이미지에서 가장 잘 작동하므로 이미지 크기를 조정하는 것이 좋습니다.
4. 이진화(Binarisation)

이미지를 흑백으로 변환하는 것입니다. Tesseract는이를 내부적으로 수행하지만 (Otsu 알고리즘), 특히 페이지 배경이 고르지 않은 어두움 인 경우 결과가 차선이 될 수 있습니다.
5. 노이즈 제거(Noise Removal)

노이즈는 이미지의 밝기 또는 색상의 무작위 변화로 이미지의 텍스트를 읽기 어렵게 만들 수 있습니다. 특정 유형의 노이즈는 이진화 단계에서 Tesseract에 의해 제거 될 수 없으므로 정확도 비율이 떨어질 수 있습니다.
6. 팽창과 침식(Dilation and Erosion)
굵은 문자 또는 얇은 문자 (특히 Serif가 있는 문자 )는 세부 사항 인식에 영향을 미치고 인식 정확도를 떨어 뜨릴 수 있습니다. 많은 이미지 처리 프로그램을 사용 하면 공통 배경에 대한 문자 가장자리의 확장 및 침식 을 통해 크기를 확장하거나 (확장) 축소 (침식) 할 수 있습니다.
과거 문서에서 번지는 잉크 번짐은 Erosion 기술을 사용하여 보정 할 수 있습니다. 침식은 문자를 정상적인 글리프 구조로 축소하는 데 사용할 수 있습니다.
예를 들어 김프의 Value Propagate 필터는 Lower threshold 값을 줄임으로써 추가로 굵은 역사적 글꼴의 침식을 만들 수 있습니다.
실물:
적용되는 부식 :
7. 회전 / 기울기 보정 (Rotation / Deskewing)

기울어 진 이미지는 페이지가 똑 바르지 않은 상태에서 스캔 된 경우입니다. Tesseract의 선 분할 품질은 페이지가 너무 왜곡되어 OCR의 품질에 심각한 영향을 미치는 경우 크게 감소합니다. 이 문제를 해결하려면 텍스트 줄이 수평이되도록 페이지 이미지를 회전합니다.
8. 스캔 테두리 제거(Scanning border Removal)

스캔 한 페이지에는 종종 주변에 어두운 테두리가 있습니다. 특히 모양과 그라데이션이 다른 경우 추가 문자로 잘못 선택 될 수 있습니다.
9. 누락 된 테두리(Missing borders)
테두리가없는 텍스트 영역 만 OCR하면 tesseract에 문제가있을 수 있습니다
10. 투명도 / 알파 채널(Transparency / Alpha channel)
일부 이미지 형식 (예 : png) 에는 투명 기능을 제공하기위한 알파 채널이 있을 수 있습니다.
| 알파 채널이란? |
| 알파 채널은 색상 (즉, 빨강, 녹색 및 파랑 채널)의 투명도 (또는 불투명도)를 나타내는 색상 구성 요소입니다. 픽셀이 다른 픽셀과 혼합 될 때 렌더링되는 방식을 결정하는 데 사용됩니다.
알파 채널은 색상의 투명도 또는 불투명도를 제어합니다. 그 값은 실제 값, 백분율 또는 정수로 나타낼 수 있습니다. 전체 투명도는 0.0, 0 % 또는 0이고 전체 불투명도는 각각 1.0, 100 % 또는 255입니다. 색상 (소스)이 다른 색상 (배경)과 혼합 될 때, 예를 들어 이미지가 다른 이미지에 오버레이 될 때 소스 색상의 알파 값이 결과 색상을 결정하는 데 사용됩니다. 알파 값이 불투명하면 소스 색상이 대상 색상을 덮어 씁니다. 투명하면 소스 색상이 보이지 않아 배경색이 비쳐 보일 수 있습니다. 값이 그 사이에 있으면 결과 색상은 다양한 정도의 투명도 / 불투명도를 가지므로 반투명 효과가 생성됩니다. 알파 채널은 주로 알파 블렌딩 및 알파 합성에 사용됩니다. |
11. 사전, 단어 목록 및 패턴(Dictionaries, word lists, and patterns)
기본적으로 Tesseract는 단어 문장을 인식하도록 최적화되어 있습니다. 대부분의 텍스트가 사전 단어가 아닌 경우 Tesseract에서 사용하는 사전을 비활성화하면 인식률이 높아집니다. load_system_dawg 와 load_freq_dawg 변수를 false 로 설정하여 비활성화 할 수 있습니다.
12. 테이블 인식(Tables recognitions)
tesseract는 사용자 정의 분할 / 레이아웃 분석없이 테이블에서 텍스트 / 데이터를 인식하는 데 문제가있는 것으로 알려져 있습니다
인식률에 여전히 문제가 있을때(Still having problems?)
위의 방법을 시도했지만 여전히 정확도가 낮은 결과가 나오면 포럼에서 도움을 요청하세요. 도움 요청시 테스트했던 예제 이미지를 함께 게시하는 것이 좋습니다.
[REFERENCE]
https://tesseract-ocr.github.io/tessdoc/
https://tesseract-ocr.github.io/tessdoc/ImproveQuality.html#rescaling
https://tesseract-ocr.github.io/tessdoc/Data-Files.html
https://www.techopedia.com/definition/1945/alpha-channel
https://stackoverflow.com/questions/14800730/tesseract-running-error
https://learnopencv.com/deep-learning-based-text-recognition-ocr-using-tesseract-and-opencv/
https://pypi.org/project/cv2-tools/
#Tesseract 한글 인식률, #Tesseract OCR,#Tesseract 한글 인식률 높이기, #Pytesseract, #Tesseract 인식률 높이기, #Tesseract 숫자 인식, #테서렉트 ocr 학습, #Tesseract-OCR 다운로드, #Import cv2 오류, #pip install opencv-python error, #Opencv-python 예제, #이미지에서 텍스트 추출, #파이썬 이미지 숫자 추출, #파이썬 OCR, #파이썬 이미지 인식, #pdf 텍스트 추출



