C언어 기초 및 함수 총정리
이번에 새롭게 시작하는 프로젝트가 있는데 PRO*C , 턱시도(미들웨어), 오라클로 이전 시스템이 구성이 되어 있다고 한다. 이 녀석을 분석해서 스프링부트, 넥사크로, 알티베이스(?) 기반으로 시스템을 다시 개발 하는 프로젝트이다.
이번 프로젝트는 모든게 다 처음인 것들 투성이라 기록해둔다.
sprintf 와 snprintf 의 차이점 (문자열 처리)
패킷 통신을 할때 주로 char 배열 형태의 버프로 패킷을 주고 받는다. 이때 패킷을 만들어서 보낼땐 sprintf 나 snrpintf 를 사용하고, 받은 패킷을 파싱할땐 snrpintf 를 사용 한다. 둘다 똑같이 문자열을 붙여주는데 왜 하나로 통일해서 쓰지 않는 것일까? 두 함수에 엄청난 차이점이 있기 때문이다.
buf 라는 변수에 아래와 같이 값이 있다고 할때.
| buf 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| a | b | c | d | e | f | g | h | i | NULL |
"abc" 가져오고 싶을 때 sprintf(abc, "%-*s", 3, buf); snrpintf(abc, 4, "%-*s", 3, buf); 위와 같이 abc 라는 배열안에 값을 복사 해올수 있다. 값을 찍어보면 sprintf 와 snprintf 의 차이를 명확히 알수 있게된다.
sprintf의 결과
abc 안의 값이 buf의 값과 동일하게 나오게 된다. "abcdefghi" 까지 모두 출력된다. abc 의 사이즈는 겨우 4칸인데도 10자리를 가진 buf 의 값을 모두 갖고 오게된다. 다른 변수의 메모리 영역까지 침범을 할수 있는 무서운 부분이다.
반면 snprintf 는 정상적으로 "abc" 의 값만 출력된다.
왜 이런 현상이 발생하는가?
snprintf 는 사용자가 두번째 인자값으로 넘긴 만큼만 갖고오면서, 마지막 주소지엔 알아서 널값을 채워주기 때문에 내가 원하는 3개의 값이 출력 되는것이다. 반면 sprintf 는 그런 인자값이 없기 때문에 Null 값이 있는부분까지 가져오게된다.
%-3s 를 해서 3자리만 가져오겠지라는 생각이 들수도 있는데, %-3s 는 좌측 정렬을 하고 혹시 비는공간이 있으면 최대 3자리 까지 스페이스바 처리를 해주는 방법이지, 3자리만 갖고오겠단 뜻이 아니므로 %s 의 규칙인 "시작지부터 Null 까지~" 를 통해 죄다 복사가 된다.
정확하게 자리수가 딱딱 들어맞는 것들을 패킷으로 만들때가 아니라면, snprintf 를 활용하는게 더 좋다고 본다.
자주 사용되는 함수 정리
strcpy 함수
문자열 복사함수이다.
#define _CRT_SECURE_NO_WARNINGS // strcpy 보안 경고로 인한 컴파일 에러 방지
#include <stdio.h>
#include <string.h> // strcpy 함수가 선언된 헤더 파일
int main()
{
char s1[10] = "Hello"; // 크기가 10인 char형 배열을 선언하고 문자열 할당
char s2[10]; // 크기가 10인 char형 배열을 선언
strcpy(s2, s1); // s1의 문자열을 s2로 복사
printf("%s\n", s2); // Hello
return 0;
}문자열 포인터에 복사하면 어떻게 될까? s2에 저장된 메모리 주소는 복사할 공간도 없을뿐더러 읽기만 할 수 있고, 쓰기가 막혀있기 때문이다.(읽기 전용 메모리에는 문자열을 복사할 수 없음)
#define _CRT_SECURE_NO_WARNINGS // strcpy 보안 경고로 인한 컴파일 에러 방지
#include <stdio.h>
#include <string.h> // strcpy 함수가 선언된 헤더 파일
int main()
{
char *s1 = "Hello"; // 문자열 포인터
char *s2 = ""; // 문자열 포인터
strcpy(s2, s1); // 실행 에러
printf("%s\n", s2);
return 0;
}
[실행결과]
0xC0000005: 0x013A585D 위치를 기록하는 동안 액세스 위반이 발생했습니다.문자열 포인터에 문자열을 복사하려면 문자열이 들어갈 공간을 따로 마련해야 됩니다. 따라서 다음과 같이 malloc 함수로 메모리를 할당한 뒤 문자열을 복사합니다.
#define _CRT_SECURE_NO_WARNINGS // strcpy 보안 경고로 인한 컴파일 에러 방지
#include <stdio.h>
#include <string.h> // strcpy 함수가 정의된 헤더 파일
#include <stdlib.h> // malloc, free 함수가 선언된 헤더 파일
int main()
{
char *s1 = "hello"; // 문자열 포인터
char *s2 = malloc(sizeof(char) * 10); // char 10개 크기만큼 동적 메모리 할당
strcpy(s2, s1); // s1의 문자열을 s2로 복사
printf("%s\n", s2); // Hello
free(s2); // 동적 메모리 해제
return 0;
}strncpy 함수.
strncpy(char* dest, const char* origin, size_t n); origin에 있는 문자열을 dest로 복사를 하는데, n 만큼만 복사하는 함수 입니다.
//[C언어/C++] strncpy example. :BlockDMask:
#include<stdio.h> //C++ <iostream> or <cstdio>
#include<string.h> //C++ <cstring>
int main(void)
{
char origin[] = "BlockDMask"; //"BlockDMask\0" 이므로 size = 11;
char dest1[20];
char dest2[] = "abcdefghijklmnop"; //size = 17;
char dest3[] = "STRNCPY_EXAMPLE"; //size = 16;
char dest4[10];
//case1 : 빈 배열에 전체를 복사할때
strncpy(dest1, origin, sizeof(origin));
//case2 : 꽉 차있는 배열에 전체를 복사할때
strncpy(dest2, origin, sizeof(origin));
//case3 : 꽉 차있는 배열에 일부만 복사할때
strncpy(dest3, origin, 4); // 오!
//case4 : 빈 배열에 일부만 복사할때
strncpy(dest4, origin, 4); // 그럼이건?
printf("case1 : %s\n", dest1);
printf("case2 : %s\n", dest2);
printf("case3 : %s\n", dest3);
printf("case4 : %s\n", dest4);
return 0;
}strcpy는 문자열 끝(= '\0') 까지 복사를 한다.
char origin[] = "BlockDMask";
char dest3[] = "STRCPY_EXAMPLE";
strcpy(dest3, origin);
printf(" case3 before : %s\n", dest3);
dest3[10] = 'y'; //'\0' -> 'y'
printf(" case3 after : %s\n", dest3);
[실행결과]
case3 before : BlockDMask
case3 after : BlockDMaskyPLE
"BlockDMask\0PLE\0" 상태의 문자열에서 처음 나타나는 '\0' 를 'y'로 바꾸어 봤습니다.
y로 바뀌니까 PLE 까지 나오는것 보이시죠?
꼭 기억해!! strcpy로 복사를 하면 문자열의 끝을 알리는 '\0'까지 복사가 된다.
strncpy로 복사했을경우 n의 길이를 주의해야 한다. strncpy(dest, origin, n) n의 크기는 sizeof(origin)보다 작거나 같아야 합니다. (휴먼에러 발생할 수 있음) 또한, dest의 길이보다 n은 작거나 같아야합니다. (런타임 에러) 1. n <= sizeof(origin) 2. n <= sizeof(dest)
char origin[] = "BlockDMask";
char dest2_1[] = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaa";
char dest2_2[] = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaa";
strncpy(dest2_1, origin, sizeof(origin));
strncpy(dest2_2, origin, sizeof(origin) - 1);
printf(" case2_1 : %s\n", dest2_1);
printf(" case2_2 : %s\n", dest2_2);
[실행결과]
case2_1: BlockDMask
case2_2: BlockDMaskaaaaaaaaaaaaaaaaaa
: case2_2 처럼 문자열을 연결하고 싶다면, sizeof(origin) - 1을 하여서 문자열의 끝에있는 '\0' 이것을 빼고 복사 하면 됩니다.
fopen 함수.
fopen 함수는 파일을 오픈하는 함수로 두개의 인자값을 받아간다.
첫번째 인자값엔 오픈하고자 하는 파일명을 입력하면 된다.( 확장자도 입력. )
두번째 인자값엔 내가 파일을 오픈할때 어떤 형식으로 오픈을 할것인지에 대한 값을 입력해야 한다.
오픈 형식 옵션.
r : 읽기 모드. 파일이 없으면 NULL 을 리턴해준다.
w :쓰기 모드. 파일이 없으면 새로 생성하고 파일이 있다면 덮어쓴다 ( 기존파일 내용 날아간다)
a : append모드. 파일이 없다면 새로 생성하고 이미 파일이 존재하면 기존파일의 내용 끝부분에 file pointer가 위치해 fprintf 등을 통해 새로 쓰기 작업을 할경우 해당 위치부터 출력 된다.
r+ : 읽기 + 쓰기 모드. 파일이 없으면 NULL 을 리턴해준다.
w+ : 읽고 쓰기 모드. 파일이 없으면 새로 만들고 있으면 기존 파일을 덮어쓴다 ( 기존파일 내용 날아간다).
a+ : 읽고 쓰는 append 모드 파일에 출력을 할땐 a 모드로 열었을때와 동일하게 동작하며, 파일안의 내용을 읽어올수도 있다.
fscanf 함수.
fscanf 함수는 scanf 함수와 똑같다고 보시면 된다.
다만 다른점은 scanf 함수는 사용자로부터 키보드를 통해 입력된 값을 받아오지만,
fscanf 함수는 파일안에 있는 값을 받아온다는 것이다.
fprintf 함수.
fprintf 함수도 printf 함수와 똑같다고 보시면 되며, 사용자가 바로 출력물을 볼수있도록 화면에 출력을 해주는 printf 함수와 다르게, 파일안에 해당 내용을 출력해준다는 점이 다르다.
fscanf, fprintf 두개의 함수 모두 첫번째 인자값에 파일포인터가 들어간다는 것 외에는 scanf, printf 함수와 사용법이 동일 하다.
strtok 함수.
strtok 함수는 문자열에서 내가 정해준 구분자를 기준으로 토큰으로 분리할 때 사용한다.
strtok 함수 문자열 검색
다음 예제는 문자열에서 “내일” 이라는 단어가 몇번째에 들어가 있는지를 알려주는 기능을 구현한 예제이다.
#include <stdio.h>
#include <string.h>
int main()
{
char str[100] = "나 스무살 적에 하루를 견디고 불안한 잠자리에 누울때면 내일 뭐하지 내일 뭐하지 걱정을 했지";
// 기본 문자열.
char *token;
// 토큰의 주소를 받을 char 포인터 변수.
int count = 1;
// 카운트를 기록할 변수.
token = strtok(str, " ");
// strtok 함수에 인자 전달 및 토큰 받아오는 부분.
/* strtok 함수엔 두개의 인자값을 보내는데.
첫번째는 검색하고자 하는 문자열의 첫 주소지.
두번째는 구분자 입니다. 위와 같이 " " 이렇게 할 경우 띄어쓰기를 구분자로, 토큰화 하며
" .,_" 이런 방법으로 여러개의 구분자를 동시에 사용할 수 도 있다. */
while(token != NULL) {
if(!strcmp(token , "내일"))
// strtok 함수에서 return 해준 주소지의 값과 내가 찾고자 하는 단어 "내일"이 같은지 확인.
{
printf("내일은 %d번째 단어 이다.\n", count);
}
token = strtok(NULL, " ");
/* strtok 함수에 위와 같이 첫번째 인자값에 NULL 을 보내게 되면,
기존의 포인터(주소지)에서 그대로 검색을 진행. */
count++;
}
return 0;
}
[출력결과]
내일은 9번째 단어 이다.
내일은 11번째 단어 이다.문자열 비교 함수 strcmp, strncmp 알아보기
두 문자열의 비교를 통해 같다, 다르다 를 알수있고 어떤 문자열이 더 크고작은지도 알 수 있다. 여기서 말하는 문자열이 크다/작다고 표현하는건 아스키코드값의 우열을 말한다.
#include <stdio.h>
#include <string.h>
void print_result(int result)
{
// 결과값이 0 이라면 두 문자열이 같다는 결과코드 입니다.
if(result == 0)
printf("같다.\n");
// 결과값이 0 보다 큰 경우엔 좌측의 문자열이 더 크다는 뜻 입니다.
else if(result > 0)
printf("좌측이 더 크다.\n");
// 결과값이 0 보다 작은 경우엔 우측의 문자열이 더 크다는 뜻 입니다.
else // result < 0
printf("우측이 더 크다.\n");
}
int main()
{
int result = 0;
// 동일한 문자열 비교.
result = strcmp("TEST STRING", "TEST STRING");
// 비교하고자 하는 문자열 두개를 전달하면 끝.
print_result(result);
// 아스키코드의 합산이 우측 문자열이 더 큰 경우 비교.
result = strcmp("TEST STRING", "tEST STRING");
print_result(result);
// 아스키코드의 합산이 좌측 문자열이 더 큰 경우 비교.
result = strcmp("tEST STRING", "TEST STRING");
print_result(result);
// 앞 4자리가 동일한 문자열 비교.
result = strncmp("TEST 111", "TEST 222", 4);
/* 비교할 문자열을 인자값으로 사용하는 strcmp 함수와 다르게,
strncmp 함수는 주소지의 첫번째 주소부터 3번째 인자값으로 전달해준
값의 길이만큼만 검사를해서 위와 같이 4를 보냈을 경우 0번 주소지부터 3번 주소지 까지
총 4자리의 주소지만을 비교해서 결과값을 돌려줍니다.
앞 4자리가 "TEST" 이니 동일한 문자열이라는 결과가 나오겠죠 ? */
print_result(result);
return 0;
}
[실행결과]
같다.
우측이 더 크다.
좌측이 더 크다.
같다.CHAR 타입을 INT 형으로 변환 해주는 함수 (atoi)
atoi 함수를 호출할때 “1234” 와 같이 숫자가 들어있는 문자열의 주소를 넘겨주면 그안에 담겨있는 숫자를 int 형으로 변환해서 그 값을 리턴해 줍니다.
#include
int main()
{
char str1[10], str2[10];
memset(str1, 0x00, sizeof(str1));
memset(str2, 0x00, sizeof(str2));
int n1 = 0, n2 = 0;
printf("두개의 정수를 입력 하세요 : ");
scanf("%s %s", str1, str2);
n1 = atoi(str1); // atoi 함수를 이용해 str1 , str2 에 들어있는 숫자를 int 형으로 변환해 n1, n2 에 저장
n2 = atoi(str2);
printf("입력받은 두수의 합은 %d 입니다.\n", n1+n2);
return 0;
}
구구단 출력
#include
int main()
{
int i, j; // 다중 for문에 사용될 변수 i, j
for(i = 2; i < 10; i+=4 ){ // i 는 2부터 9까지. 4씩 증가.
for(j = 1; j < 10; j++){ // j 는 1부터 9까지. 1씩 증가.
printf("%2d * %2d = %2d \t", i, j, i*j);
printf("%2d * %2d = %2d \t", i+1, j, (i+1)*j);
printf("%2d * %2d = %2d \t", i+2, j, (i+2)*j);
printf("%2d * %2d = %2d \t", i+3, j, (i+3)*j);
printf("\n");
}
printf("\n");
}
return 0;
}
[실행결과]
2 * 1 = 2 3 * 1 = 3 4 * 1 = 4 5 * 1 = 5
...... 생략
6* 1 = 6 7 * 1 = 7 .....생략문자열의 한글, 알파벳, 특수문자, 줏자에 대한 카운트 구하기
한글 같은 경우는 아스키코드표가 아닌 KS5601 문서를 보면 0xB0 부터 시작된다는걸 알수 있다. 한글은 알파벳과 달리 한글자에 2자리의 공간을 잡아 먹으니 알파벳이나 숫자와 달리 한칸씩 더 지나가게 해줘야 한다.
아스키코드표
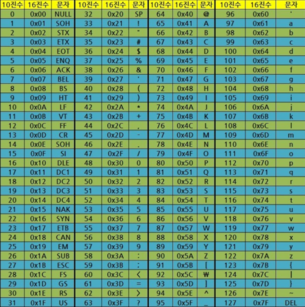
KS5601 및 유니코드 표
#include
#include
int main()
{
char buf[100] = "TEST123#TE스트1테스T2*";
unsigned char bit;
int len = 0;
int i = 0;
int n_cnt = 0, e_cnt = 0, k_cnt = 0, g_cnt = 0;
len = strlen(buf);
for(i = 0; i < len; i++)
{
bit = buf[i];
if(bit == 32) // ' '
continue;
else if(bit > 47 && bit < 58) // 숫자.
n_cnt++;
else if((bit > 64 && bit < 91) || (bit > 97 && bit < 123)) // 영어. 소문자, 대문자.
e_cnt++;
else if(bit > 0xb0) // 한글.
{
i++;
k_cnt++;
}
else // 특문.
g_cnt++;
}
printf("숫자 : [%d]\n", n_cnt);
printf("한글 : [%d]\n", k_cnt);
printf("영어 : [%d]\n", e_cnt);
printf("특문 : [%d]\n", g_cnt);
return 0;
} 포인터를 이용해 두개의 변수 값을 바꾸기( SWAP )
포인터를 배우기 시작할때 한번쯤은 해보는 단골손님으로 main 함수에서 입력받은 두개의 값이 담긴 변수를 swap 함수에게 전달해 swap 함수에서 각각의 변수에 담긴 값을 바꿔주고~ main 함수에서 해당 결과를 출력해보는 예제
#include
void swap(int n1, int n2);
int main()
{
int n1 = 0, n2 = 0;
printf("Input 2 Num : ");
scanf("%d %d", &n1, &n2);
printf("Input n1[%d] n2[%d]\n", n1, n2); // 입력 받은 값을 확인차 출력을 해요.
swap(n1, n2); // swap 함수를 호출해서 값을 넘겨요~
printf("Swap n1[%d] n2[%d]\n", n1, n2); // swap 함수를 다녀온뒤의 변수들의 값은?
return 0;
}
void swap(int n1, int n2) // 함수를 호출할때 전달해준 값을 n1, n2 에 채워준다는 뜻
{
int temp; // 임시 저장공간 !! n1 과 n2 의 값을 서로 맞바꾸기 위해 선언
temp = n1; // 먼저 temp 에 n1 을 대입하고~
n1 = n2; // n1 은 temp 에 있으니 이제 안심하고 n1 에 n2를 대입 !
n2 = temp; // n2 의 값도 n1 로 이동 됐으니 이제 n2 에 temp에 저장되있는 n1 의 값을 대입 !!
printf("!!!!! n1[%d] n2[%d]\n", n1, n2); // 서로 맞바꾼 값을 확인차 출력 !!
}[실행결과]
Input 2 Num : 1 2
Input n1[1] n2[2]
!!!!!!! n1[2] n2[1]
Swap n1[1] n2[2]!!!!!!! 부분은 swap 함수 안에서 n1 과 n2 의 값을 맞바꾼뒤 출력 했다. 값이 바뀐게 확인이 된다. 하지만 swap 함수를 빠져나와서 다시 main 에서 출력을 하니 값이 다시 원래대로 돌아왔다.
이유가 뭘까?
이건 swap 함수에 있는 n1, n2 와 main 함수에 있는 n1, n2 와 서로 다른 변수이기 때문이다.
좀더 다르게 말하자면 main 함수에서 swap 함수를 호출하면서 전달한건
n1, n2 가 갖고 있는 1과 2라는 값만 보내준 것이기 때문에 swap 함수에서 변경을 하든 말든 main 함수에 있는 n1 과 n2 라는 변수가 갖고 있던 1 과 2라는 값에는 전혀~ 변경이 되지 않는 것이다.swap 함수에서 변경한 것들을 main 에서도 똑같이 적용이 되게 하려면 포인터를 사용해야한다.
#include
void swap(int *n1, int *n2);
/* 변수에 *선언해주면 포인터 변수 라는 뜻 주소값을 저장하는 변수라는 뜻이다. */
int main()
{
int n1 = 0, n2 = 0;
printf("Input 2 Num : ");
scanf("%d %d", &n1, &n2);
printf("Input n1[%d] n2[%d]\n", n1, n2);
swap(&n1, &n2);
/* 여기도 보시면 위에 있던 소스랑 조금 다르죠 ?
& 의 의미는 scanf 함수를 배우면 알게되는데
변수 앞에 & 이 붙으면 그건 해당 변수가 가진 값을 의미하는게 아니라
해당 변수의 주소지를 의미 하게 된다.
함수를 호출할때 &n1 을 했으니 n1이 갖고 있는 값이 아닌 n1의 주소가
전달된다. */
printf("Swap n1[%d] n2[%d]\n", n1, n2);
return 0;
}
void swap(int *n1, int *n2)
{
int temp;
/* 자 이제 main 함수에서 n1 과 n2 의 주소지를 넘겨 줬으니
swap 함수의 역할을 수행하기 위해 값을 변경 해야겠죠 ?
변수를 선언할때 별딱지( * ) 를 붙이면 이건 포인터 변수다 라는 뜻이지만
이렇게 아래 처럼 대입을 하는 부분에서 포인터 변수 앞에 *를 붙이게되면
요건 해당 포인터 변수가 갖고 있는 값을 나타낸다. */
temp = *n1;
*n1 = *n2;
*n2 = temp;
printf("!!!!! n1[%d] n2[%d]\n", *n1, *n2);
// 여기서도 우린 서로 바뀐 값을 출력하고 싶은거니까 주소지가 아닌 값이라는 뜻으로 *를 붙여준다.
}실행결과
Input 2 Num : 1 2
Input n1[1] n2[2]
!!!!!!! n1[2] n2[1]
Swap n1[2] n2[1]sprintf 함수의 사용 방법
sprintf 의 기능을 좀더 쉽게 생각하자면 scanf 함수나 fprintf 함수와 비슷하다고 보면 된다.
sprintf 의 기능을 좀더 쉽게 생각하자면 scanf 함수나 fprintf 함수와 비슷하다고 보면 된다.
scanf 함수를 통해 사용자로부터 입력 받은 값을 데이터에 저장을 하기도 하고 fprintf 함수를 통해 내가 출력하고자 하는 내용을 파일안에 출력을 해주듯이 sprintf 함수를 통해 각 변수안의 있는 내용을 원하는 저장공간( char 배열 )에 그대로~ 저장( 출력 )을 할수가 있다.
그리고 해당 데이터들은 모두 char 배열 안에 문자의 형태로 저장이 된다.
sprintf 는 주로 파싱을 할때 쓰이기도 하고, 다양한 내용을 한번에 출력해서 보여주고자 할때
편의를 위해 사용하기도 하며 비슷한 함수로는 snprintf 함수가 있다.
인자값은 크게 3가지.
첫번째 !! 저장할 문자열 변수의 주소지. ( 데이터를 저장하고싶은 char 배열의 주소지 )
두번째 !! 저장하고자 하는 데이터의 형식.
세번째 !! 자신이 입력한 형식에 들어갈 변수명.
sprintf 함수를 이용해 정수, 실수, 문자, 문자열등의 데이터를 하나로 연결해보자.
#include
#include
// os 마다 특성이 조금씩 달라서 추가하지 않아도 됨( string.h )
int main()
{
char str[50]; // 다양한 데이터 형식을 하나로 연결할때 사용할 문자열 str 선언.
int n = 100; // 정수형 데이터
char c = '1'; // 문자 데이터
char ch[5] = "50"; // 문자열 데이터
double d = 1.5; // 실수형 데이터
memset(str, 0x00, sizeof(str)); // str 이라는 변수안의 값을 모두 0x00( 널 ) 으로 초기화
sprintf(str, "%d %c %s %.2lf", n, c, ch, d);
/* sprintf 함수를 통한 정수, 문자, 문자열, 실수 형태의 데이터를 공백 문자 하나씩을 띄어주며
하나로 연결 */
printf("[%s]\n", str); // 출력
return 0;
}
출력 결과 : [100 1 50 1.50]파일 입출력을 이용해 연산결과 저장
#include
int main()
{
FILE *fp1; // input.txt 를 위한 파일포인터 선언.
FILE *fp2; // output.txt 를 위한 파일 포인터 선언.
int n1 = 0, n2 = 0; // input.txt 에서 읽어올 숫자를 저장할 변수 선언 및 0으로 초기화.
int result = 0; // 덧셈 연산의 결과를 저장할 변수 선언 및 초기화.
// fopen 함수를 통해 fp1 에 input.txt 파일을 읽기 모드로 오픈.
fp1 = fopen("input.txt", "r");
// fp1 이 NULL 과 같다면 이건 파일이 정상적으로 오픈되지 않음. ( 파일이 없거나 비정상적인 파일일경우 여기에 해당 )
if(fp1 == NULL)
{
printf("input.txt File Open Error!!\n");
return 1;
}
fscanf(fp1, "%d %d", &n1, &n2);
// fscanf 함수를 통해 파일에 입력된 값 을 각각 n1, n2 변수에 저장.
fclose(fp1); // 사용을 완료한 파일 닫기.
result = n1 + n2; // 덧셈 연산 결과 저장.
// 쓰기모드로 output.txt 파일 오픈
fp2 = fopen("output.txt", "w");
if(fp2 == NULL)
{
printf("output.txt File Open Error!!\n");
return 1;
}
fprintf(fp2, "%d + %d = %d\n", n1, n2, result);
// fprintf 함수를 이용해 쓰기 형식으로 오픈한 파일에 내가 원하는 내용( n1 + n2 = result ) 을 출력.
fclose(fp2); // 파일 닫기.
printf("End..\n");
return 0;
}SWITCH 문을 이용한 계산기 만들기
#include
int main()
{
double n1 = 0, n2 = 0;
// 실수형태의 값을 입력할수도 있기 때문에 int 형이 아닌 double 형으로 선언
char c = 0;
printf("ex> 1 + 2\n");
printf("연산 입력 : ");
scanf("%lf %c %lf", &n1, &c, &n2);
// 사용자로부터 연산을 입력 받는 부분.
// 사용자가 10.2 + 20 을 입력할경우 순서대로 n1 = 10.2 / c = '+' / n2 = 20 대입됨.
switch(c) // 변수 c 안의 값을 이용한 switch 문 시작.
{
case '+':
printf("%.1f + %.1f = %.2f\n", n1, n2, n1+n2);
// %.1f 의 뜻은 소수점 1자리까지만 출력하겠다는 뜻
// %.2f 는 소수점 2번째 자리까지만 출력
// 만약 소수점 3번째 자리까지 값이 있을때 .2f 를 통해 소수점 2자리만 출력을 하게되면
// 3번째 자리수를 반올림해서 소수점 두자리까지만 출력( 10.009 -> 10.01 )
break;
case '-':
printf("%.1f - %.1f = %.2f\n", n1, n2, n1-n2);
break;
case '/':
printf("%.1f / %.1f = %.2f\n", n1, n2, n1/(double)n2);
break;
case '*':
printf("%.1f * %.1f = %.2f\n", n1, n2, n1*n2);
break;
default: // +, -, *, / 모두 아닐때
printf("잘못 입력 하셨어요..\n");
break;
}
return 0;
}RAND 함수와 반복문을 이용한 야구 게임 만들기
#include
#include
#include
int main()
{
int i = 0, j = 0;
int user[3] = {0,} , computer[3] = {0,};
int strike = 0, ball = 0;
// srand 를 이용해 난수의 발생을 렌덤으로 하게끔 사용.
srand((unsigned int)time(NULL));
for(i = 0; i < 3; i++) // for 반복문을 이용해 3회 반복.
{
computer[i] = (rand() % 9) + 1; // rand 함수를 이용해 숫자가 나오면 그걸 9 로 나눔
// 렌덤으로 나온 숫자를 9 로 나눠주면 나머지는 무조건 ! 0 ~ 8 이 나오게 되겠죠 ?
// 여기서 +1 을 해주면 내가 원하는 1 ~ 9 까지의 수를 얻을수 있음.
for(j = 0; j < i; j++) // for 반복문을 이용해 j 가 i 보다 작을때 까지만 반복~ 3회 반복하겠다는거죠~?
{
if(computer[i] == computer[j]) // computer 에 저장한 난수 3개중 동일한 값이 있을경우 다시 난수를 발생 시키기 위한 조건식!!
{
i--; // 다시 난수를 발생 해야하니 i 값을 -1 해줍시다. ( i가 3이 되면 반복문에서 빠져나오게 되있기 때문에 -1을 해주는겁니다. )
break; // 안쪽 for 문 빠져나가기.
}
}
}
while(strike != 3) // strike 의 값이 3이 아닐때 까지만 반복.
{
printf("3개의 정수를 1~9 사이로 입력하세요. \n");
//scanf("%d %d %d", &user[0], &user[1], &user[2]);
for(i = 0; i < 3; i++) // 정수 3번 반복 입력을 받기 위한 for 문
scanf("%d", &user[i]); // 사용자로부터 정수 입력 받고 저장.
// 한번에 3개의 정수를 모두 받아올수도 있고 반복문을 이용해 하나씩 받아올수도 있습니다.
strike = 0;
ball = 0;
// strike, ball 의 값 0으로 초기화.
for(i = 0; i < 3; i++) // 사용자가 고른 숫자와 컴퓨터가 고른 숫자를 대조하기 위한 반복문 시작.
{
for(j = 0; j < 3; j++)
{
if(user[j] == computer[i]) // user가 입력한 값과 computer이 입력한 값이 같은지 확인.
{
if(i == j) // 자리 까지 같으면 strike 값 증가.
strike++;
else
ball++; // 숫자만 동일하고 자리가 다르면 ball 증가.
}
}
}
if(strike == 0 && ball == 0)
printf("아웃 입니다 !!\n");
else
printf("%d 스트라이크 %d 볼입니다.\n", strike, ball); // 출력.
}
return 0;
}stat 함수를 이용한 FILE SIZE 가져오기
#include <stdio.h>
#include <sys/stat.h>
int main()
{
int ret = 0;
// stat 함수의 return 값을 받아올 변수 선언.
struct stat buf;
// 파일의 관한 정보를 받아올 stat 구조체 변수 선언.
// 해당 구조체는 sys/stat.h 파일 안에 있습니다.
ret= stat("test.txt", &buf);
// stat 함수엔 두개의 인자 값이 들어가는데, 파일명과 아까 선언해준 stat 구조체의 주소다.
// test.txt 파일의 FILE 포인터가 아닌 파일의 이름이라는 점
if(ret < 0) // stat 함수에서 돌려준 결과값이 0이 아니라면 ERROR 이므로 예외 처리.
{
printf("ERROR\n");
return 0;
}
printf("RET[%d] SIZE[%d]\n", ret, buf.st_size);
// 리턴값 및 SIZE 를 출력.
// buf.st_size 에 담겨 있는 값이 파일의 사이즈이다.
// stat 구조체 안에는 파일 사이즈 말고도 파일의
// 사용자 식별번호, 그룹 식별번호, 변경시간등 다양한 정보가 담겨 있다.
return 0;
// 예제 종료.
}정수 나눗셈의 결과를 소수점 표기 방법
#include <stdio.h>
int main()
{
int n1 = 0, n2 = 0;
double ave = 0;
printf("두개의 정수를 입력 하세요 : ");
scanf("%d %d", &n1, &n2);
// 정수/정수
ave = (n1+n2)/2;
printf("입력받은 두수의 평균 : %.2lf\n\n", ave);
// 형변환을 통한 소수/정수
ave = 0;
ave = (double)(n1+n2)/2;
printf("입력받은 두수의 평균 : %.2lf\n\n", ave);
// 꼼수를 이용한 정수/소수
ave = 0;
ave = (n1+n2)/2.0;
printf("입력받은 두수의 평균 : %.2lf\n\n", ave);
return 0;
}출력문 색상입히기
한가지 주의 할점은 한번 색상을 입히면 그뒤로 출력되는 모든 출력문들의 색상이 동일하게 적용이 되니, 원하는 색상의 출력이 끝나면 꼭 노멀 값으로 다시 변경해주어야 한다.
#include
#define C_NRML "\033[0m"
#define C_BLCK "\033[30m"
#define C_RED "\033[31m"
#define C_GREN "\033[32m"
#define C_YLLW "\033[33m"
#define C_BLUE "\033[34m"
#define C_PRPL "\033[35m"
#define C_AQUA "\033[36m"
int main()
{
printf("%s C_NRML\n", C_NRML);
printf("%s C_BLCK\n", C_BLCK);
printf("%s C_RED\n", C_RED);
printf("%s C_GREN\n", C_GREN);
printf("%s C_YLLW\n", C_YLLW);
printf("%s C_BLUE\n", C_BLUE);
printf("%s C_PRPL\n", C_PRPL);
printf("%s C_AQUA\n", C_AQUA);
printf(" TEST End Color ~\n");
printf("%s Test End Color...\n", C_NRML);
printf(" Good Bye ~ \n");
return 0;
}소문자 혹은 대문자를 입력받아 변환 (아스키코드값을 활용한 예)
#include
#include
int main()
{
char str[100];
char bit;
int len = 0;
int i = 0;
int select = 0;
memset(str, 0x00, sizeof(str));
printf("문자를 입력 : ");
scanf("%s", &str);
printf("소문자 -> 대문자 : 1\n");
printf("대문자 -> 소문자 : 2\n");
scanf("%d", &select);
len = strlen(str);
for(i = 0; i < len; i++)
{
if(select == 1)
{
if(str[i] >= 'a' && str[i] <= 'z')
str[i] = str[i] - 32;
}
else if(select == 2)
{
if(str[i] >= 'A' && str[i] <= 'Z')
str[i] = str[i] + 32;
}
// -32 혹은 +32 를 해주는 이유는 대문자의 아스키코드값이 32가 차이나기 때문.
}
printf("변환후 : %s\n", str);
return 0;
}for 문 예제
#include
int main()
{
int n[5][5] = {0,};
int i, j;
int k = 1;
for(i = 0; i < 5; i++)
for(j = 0; j < 5; j++)
n[i][j] = k++;
for(i = 0; i < 5; i++)
{
for(j = 0; j < 5; j++)
printf("%3d", n[i][j]);
printf("\n");
}
return 0;
}
[실행결과]
1 2 3 4 5
6 7 8 9 10
.....#include
int main()
{
int n[5][5] = {0,};
int i, j;
int k = 1;
// 우측 아래 부터 대입을 해야하니 i 와 j 모두 4부터 한개씩 줄여 나가야 겠죠 ?
for(i = 4; i >= 0; i--)
for(j = 4; j >= 0; j--)
n[i][j] = k++;
for(i = 0; i < 5; i++)
{
for(j = 0; j < 5; j++)
printf("%4d", n[i][j]);
printf("\n");
}
return 0;
}
[실행결과]
25 24 23 22 21
20 19 18 17 16
.....
5 4 3 2 1
#include
int main()
{
int n[5][5] = {0,};
int i, j;
int k = 1;
for(i = 0; i < 5; i++)
for(j = 0; j < 5; j++)
n[j][i] = k++;
// 세로 순서로 출력을 해야하니 값을 대입할때 n[0][0], n[1][0], n[2][0].....n[4][0] 이렇게 가야겠죠 ?
for(i = 0; i < 5; i++)
{
for(j = 0; j < 5; j++)
printf("%4d", n[i][j]);
printf("\n");
}
return 0;
}
[실행결과]
1 6 11 16 21
2 7 12 ...
3 8 13
4 9 14
5 10 15#include
int main()
{
int n[5][5] = {0,};
int i, j;
int k = 1;
// 3번과 동일한데 한가지 다른점이 우측에서 좌측으로 출력을 해야하니 i 값을 배열의 끝자리인 4부터 하나씩 내린다
// 그러면~ n[0][4], n[1][4], n[2][4]....n[4][4], n[0][3] ... 이런식으로 순서대로 대입이 되겠죠 ?
for(i = 4; i >= 0; i--)
for(j = 0; j < 5; j++)
n[j][i] = k++;
for(i = 0; i < 5; i++)
{
for(j = 0; j < 5; j++)
printf("%4d", n[i][j]);
printf("\n");
}
return 0;
}
[실행결과]
21 16 6 1
22 17
23 18
24 19
25 20 ....#include
int main()
{
int n[5][5] = {0,};
int i, j;
int k = 1;
// 4번에선 i 값을 하나씩 줄여나갔지만 이번엔 j 값을 하나씪 줄여줘야 한다.
// n[0][4], n[0][3].....n[0][0] .. n[1][4]... 이런식으로 값을 대입할수 있도록~
for(i = 0; i < 5; i++)
for(j = 4; j >= 0; j--)
n[j][i] = k++;
for(i = 0; i < 5; i++)
{
for(j = 0; j < 5; j++)
printf("%4d", n[i][j]);
printf("\n");
}
return 0;
}
[실행결과]
5 10 15 20 25
4 9 14
3 8 ...
2 7
1 6
캐리지 리턴(CR)과 라인 피드(LF)
캐리지 리턴(CR)과 라인 피드(LF)는 느린 프린터의 유산입니다.
CR은 현재 위치를 나타내는 커서를 맨 앞으로 이동시킨다는 뜻이고, LF는 커서의 위치를 아랫줄로 이동시킨다는 뜻입니다. 이 두 동작을 합치면 뉴라인(‘\n’)과 동일한 동작을 하게 됩니다.
굳이 두 동작으로 나눈 이유는 과거의 느린 프린터가 물리적인 동작을 취하는데 충분한 시간을 확보해주기 위해서 신호를 두개로 나누어 보내주었기 때문이라고 알고 있습니다.
하지만 현재는 둘 중 하나만 있어도 뉴라인으로 간주합니다. 그리고 LF로 뉴라인을 나타내는지 CR+LF로 뉴라인을 나타내는지는 언어의 차이가 아니라 시스템의 차이입니다.
Unix-like 시스템에서는 LF로, Windows에서는 CR+LF로 표현합니다.



