[SPRING BOOT] JAVA 스프링부트 배치(Spring Batch 개발을 위해 개발자가 알아둬야할 내용 정리

SpringBatch를 개발해볼 기회가 생겼다. 이번기회에 알아야 하는 내용을 기록해둔다.
스프링 배치 개발환경 설정은 공통팀(AA)에서 해주기 때문에 개발자는 배치개발 템플릿을 토대로 개발만 해주면된다. 프로젝트에 공통팀이 있으니 너무 편하네.
스프링배치 전체 프로세스
SpringBatch의 Tasklet, Chunk는 아래 이미지와 같은 과정을 거친다.
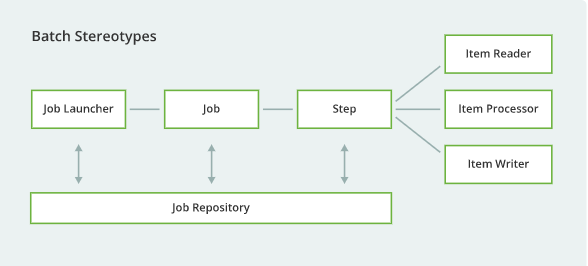
1. Job Launcher로 Job을 실행한다.
2. Job은 Step으로 구성되는데 “배치 처리의 최상위 단위“로 실제 배치처리를 수행한다.
3. Step에서는 읽어오고(Item Reader) → 처리하고(Item Processor) → 저장(Item Writer)을 수행한다.
하나의 작업으로 처리할 때는 Tasklet 단위로 개발하면 되는데, 참고로 스프링배치는 Chunk 지향이다.
Job 수행과정
1. 기본 : Job > JobInstance > JobExecution
2. JobParameters가 포함된 경우 : Job > JobInstance를 수행시 JobParameters 대입 > JobExecution
배치 메타 테이블
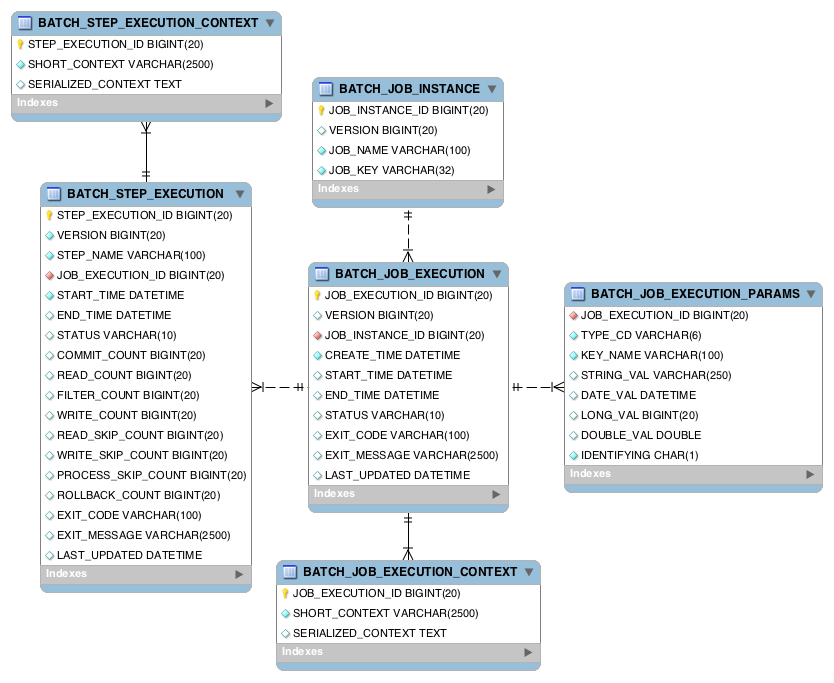
SpringBatch에서 Job을 실행하면” JobRepository” 가 배치관련 데이터들을 위 6개의 Batch Meta Table에 기록해준다.
스프링배치 개발 방법 2가지 (Tasklet , Chunk)
1.Task 기반 : 하나의 작업만 실행. Tasklet을 이용한 Task 기반 처리 방식이다. 단일 작업을 처리하기 때문에 작업이 끝날 때까지 대기해야 한다.그렇기에 대용량 데이터 처리에는 적합하지 않다.
2.Chunk 기반 : 하나의 큰 작업을 n개씩 나눠서 chunk 단위로 묶어서 실행하는데 chunk 단위로 commit과 rollback이 이루어진다.
예를 들어, 파일을 읽어들여 데이터를 처리하는 작업이나 DB에서 데이터를 조회하여 처리하는 작업 등이 있다.
Chunk는 데이터를 처리할때 커밋되는 데이터 덩어리이다. 데이터를 일정한 크기로 나눈 데이터 셋을 의미한다.
스프링 부트 배치 Chunk 방식은 데이터 처리를 여러 개의 작은 청크(Chunk)로 나누어 처리하는 방식이다. 이 방식은 대량의 데이터 처리 시 성능 향상과 오류 발생 시 손실 최소화에 효과적이다.
다음은 Chunk 방식 기본 구성 요소와 샘플 코드입니다.
1. 구성 요소
ItemReader: 데이터 소스로부터 데이터를 읽어 청크 단위로 반환한다.
ItemProcessor: 읽은 데이터를 가공하거나 변환한다. (선택 사항)
ItemWriter: 가공된 데이터를 대상 시스템에 저장한다.
Step: Reader, Processor, Writer를 연결하고, 청크 크기, 커밋 간격 등을 설정한다.
Job: 여러 Step들을 순차적으로 또는 병렬적으로 실행하도록 설정한다.
Chunk 구성 스탭
Chunk는 다음 3개의 Step으로 구성된다.
ItemReader 필수
ItemWriter 필수
ItemProcessor(필수 아님)
Reader, Writer에서는 데이터가 1건씩 처리되고
Writer에서 Chunk 단위로 처리된다.
Chunk 방식에서는 ‘Reader-Processor-Writer 방식’을 이용한다.
이러한 처리 방식은 대용량 처리를 위해서 사용하며 ‘Reader’는 데이터를 읽어 들이는 역할을 하며 ‘Processor’는 읽어 들인 데이터를 가공하거나 필터링하는 역할을 한다. ‘Writer’는 가공된 데이터를 저장하는 역할을 수행한다.
예로,
1. 데이터 베이스에서 데이터를 읽어온다 (Item Reader)
2. 읽어온 데이터를 처리한다.(Item Processor)
3. 데이터를 저장한다(Item Writer)
Tasklet, Chunk 처리방식의 비교
| 구분 | Tasklet | Chunk |
| 실행 시점 | STEP 실행 중 | STEP 실행 전 |
| 실행 방식 | ‘작은 단위’로 분할하여 실행 | ‘하나의 큰 덩어리’로 실행 |
| 커밋 방식 | ‘Tasklet’ 단위로 처리 후 커밋 | ‘Chunk’ 단위로 처리 후 커밋 |
| 배치 성능 | ‘작은 단위’의 데이터 처리 시 유리 | ‘대량의 데이터’ 처리 시 유리 |
| 재시작 | 실패한 태스크릿만 다시 실행 | 실패 시 청크 전체 다시 실행 |
| 가독성 | 코드가 분할되어 가독성 향상 | 코드가 길어져 가독성 저하 |
| 유지보수 | 수정이 용이 | 수정이 어려움 |
Chunk 방식은 대량 데이터 처리 시 효과적이지만, 데이터 크기가 작거나 처리 속도가 중요하지 않은 경우에는 Tasklet 방식을 사용하는 것이 더 적합할 수 있다.
스프링 배치 주요 용어
1. JobLauncher
배치 Job을 실행하는 런쳐이다. ( 잡을 실행하는 인터페이스를 의미함)
Job과 Parameter를 받아서 실행하고 JobExecution를 반환합니다.
Spring Batch는 SimpleJobLauncher 라는 단일 JobLauncher 만 제공한다. 배치 잡이 실행되면 JobInstance가 생성된다.
2. Job
정해진 Step을 실행시킬 작업을 의미로,
Job configuration과 대응되는 단위이다. ‘배치 처리의 최상위 단위’를 의미한다.
3. Step
실제로 배치 처리를 ‘수행’하는 단위를 의미한다. Spring Batch Job안에는 한 개 이상의 Step으로 구성되어 있다.
Job > 여러 Step (2종류: Tasklet, Chunk)
4. JobParameter
Spring Batch는 외부 혹은 내부에서 파라미터를 받아 여러 Batch 컴포넌트에서 사용할 수 있게해주는 Job 실행시 필요한 파라미터를 의미한다.
Job Parameter를 사용하기 위해선 항상 Spring Batch 전용 Scope를 선언해야 한다.
크게 @StepScope와 @JobScope 2가지가 있다.
5. JobRepository
JobLauncher, Job, Step의 CRUD 오퍼레이션을 지원하는 메커니즘이다.
6. ItemReader
외부로부터 데이터를 읽어오는 개체 (데이터를 읽어오는 인터페이스를 의미)
7. ItemProcessor
읽어온 데이터를 가공 및 처리하는 개체(인터페이스)
8. ItemWriter
처리된 데이터를 외부로 출력하는 개체(인터페이스)
9. JobInstance
Job이 실행되었을 때, 논리적인 실행 단위 ( Job 실행을 나타내는 “인스턴스”를 의미)
10. JobExecutionListener
Job 실행 전후로 수행할 작업을 정의하는 인터페이스를 의미.
11. ExecutionContext
Step 실행 중 필요한 컨텍스트 정보를 의미
12. StepExecution
Step 실행 정보를 나타내는 인스턴스를 의미
13. StepExecutionListener
Step 실행 전후로 수행할 작업을 정의하는 인터페이스를 의미
스프링배치시 사용되는 어노테이션
@Slf4j
@Slf4j는 롬복(Lombok) 어노테이션 중 하나로, SLF4J(Logger Facade for Java)를 사용하기 위한 로거를 자동으로 생성한다.
SLF4J는 Java 어플리케이션에서 로깅을 위한 추상화를 제공하며, 실제로 사용할 로깅 구현은 클래스패스에 존재하는 로깅 프레임워크에 의해 결정된다.
[refernece]
Baeldung: Spring Boot With Spring Batch
Baeldung: Introduction to Spring Batch
