[Python] 파이썬 판다스(pandas)를 사용하여 엑셀(xlsx, csv)파일로 저장하는 방법 : numpy, openpyxl, to_excel(), to_csv()
판다스(pandas)는 데이터 분석을 위해 많이 사용되는 모듈입니다. xlsx, csv파일을 읽어와서 DataFrame으로 가져올 수 있습니다. 또다른 방법은 웹 크롤링을 하여 가져올 수 있습니다. 판다스(pandas)를 사용하여 엑셀파일(xlsx, csv)로 데이터를 저장하려면 openpyxl 라이브러리(모듈)를 사용해야합니다. 그리고 하나 더 numpy모듈이 필요합니다. numpy모듈이 설치되어 있지만 버전이 안맞는 경우 런타임오류가 발생합니다. csv나 xlsx파일로 저장을 하려고 할때 런타임 오류가 발생하는 경우 아래 글을 확인하세요.
[Python] 파이썬 오류처리 RuntimeError: The current Numpy installation…fails to pass a sanity check due to a bug in the
웹크롤링을 통하여 얻은 데이터를 엑셀파일로 저장하기위해 판다스(pandas) 모듈을 설치 후 엑셀로 출력하는 코드를 실행하였습니다. 그런데 기대했던 것과 달리 오류가 발생했어요. pandas 모듈을
playground.naragara.com
엑셀로 저장하려면 to_excel()함수를 사용합니다.
import pandas
import openpyxl
pandas.__version__
df = pandas.DataFrame(data_lst, columns=['뉴스제목', "기사 날짜", "URL", "이미지 URL"])
# writer = pandas.ExcelWriter("뉴스타파_기사.xlsx", engine="openpyxl")
#df.to_excel("뉴스.xlsx", index=False, sheet_name="첫번째탭")
with pandas.ExcelWriter("./뉴스.xlsx") as writer:
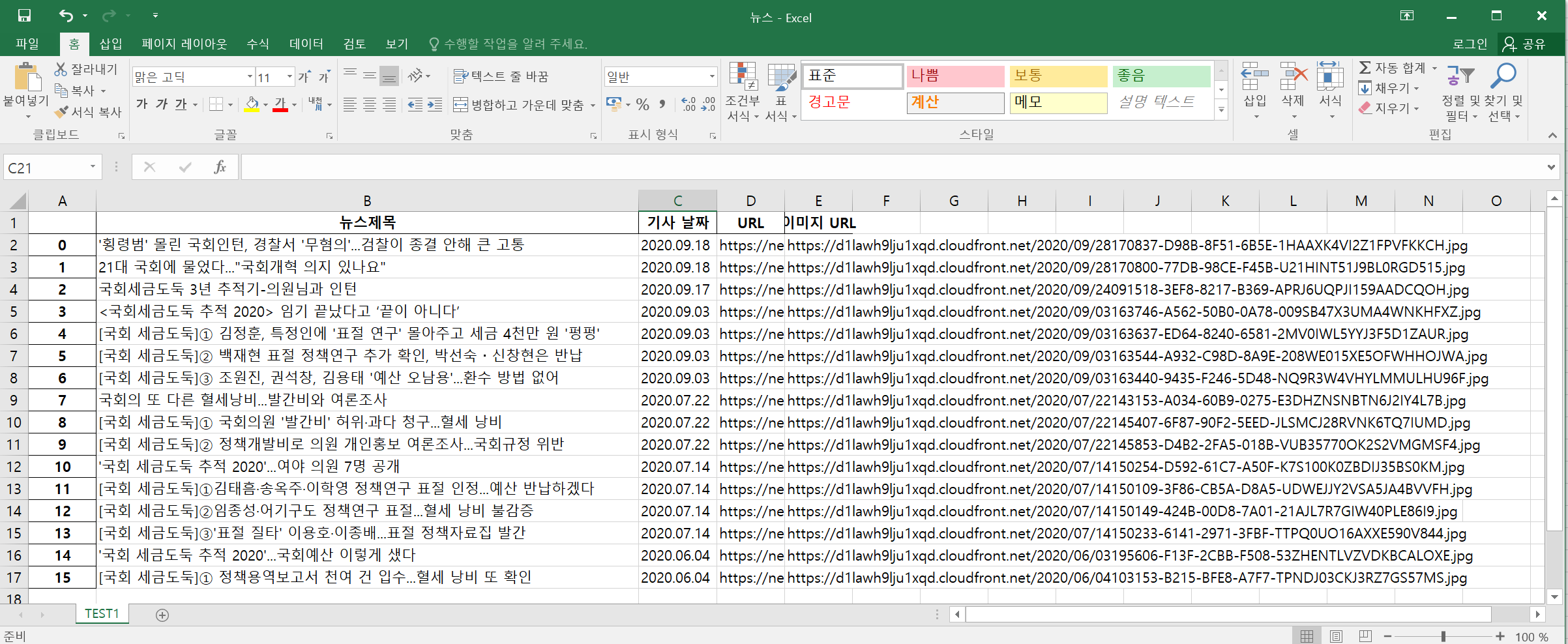
df.to_excel(writer, sheet_name="TEST1")openpyxl 모듈을 사용할 수 없는 경우 오류가 발생합니다. 설치가 시급합니다.
16
Traceback (most recent call last):
File "C:pythonWorkspacemain.py", line 59, in <module>
with pandas.ExcelWriter("./뉴스.xlsx") as writer:
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespandasioexcel_openpyxl.py", line 18, in __init__
from openpyxl.workbook import Workbook
ModuleNotFoundError: No module named 'openpyxl'
Process finished with exit code 1
저는 개발툴(IDE)로 파이참을 사용하고 있어요. 설치가 되지않은 모듈을 import 하게되면 빨간줄로 표시가되요.
마우스 커서를 위로 올리면 바로 설치할 수 있어요. (단축키 : Alt + Shift + Enter)

openpyxl 모듈을 설치하고 나면 이제 정상적으로 저장할 수 있습니다.
csv로 저장하기위해 to_csv()함수를 사용합니다. 혹시, csv파일을 열었을 때 한글이 깨지는 경우가 있음으로 encoding을 utf-8-sig로 해주세요. csv파일로 저장하는 경우에는 openpyxl 라이브러리를 import 할 필요 없습니다.
import pandas
df = pandas.DataFrame(data_lst, columns=['뉴스제목', "기사 날짜", "URL", "이미지 URL"])
df.to_csv("test2.csv", index=False, encoding="utf-8-sig") #utf-8 , ms949data_lst 변수의 값이 필요하신경우 아래 링크를 참고하세요.
[Python] 파이썬 웹 크롤링 BeautifulSoup모듈을 사용하여 뉴스 긁어오기: HTML파싱(뉴스 제목, 날짜, 링크,이미지URL)
[Python] 파이썬 웹 크롤링 BeautifulSoup모듈을 사용하여 뉴스 긁어오기: HTML파싱(뉴스 제목, 날짜, 링
뉴스타파 사이트의 “세금도둑추적2020” 뉴스 크롤링을 시도해봅니다. 뉴스부분의 HTML을 파싱하기위해서 크롬 브라우저를 열고 newstapa.org 사이트를 열어요. 그리고 난 후 F12키를 눌러 개발자 도구
playground.naragara.com
■리스트(list) 데이터를 엑셀파일에 저장하기
import pandas
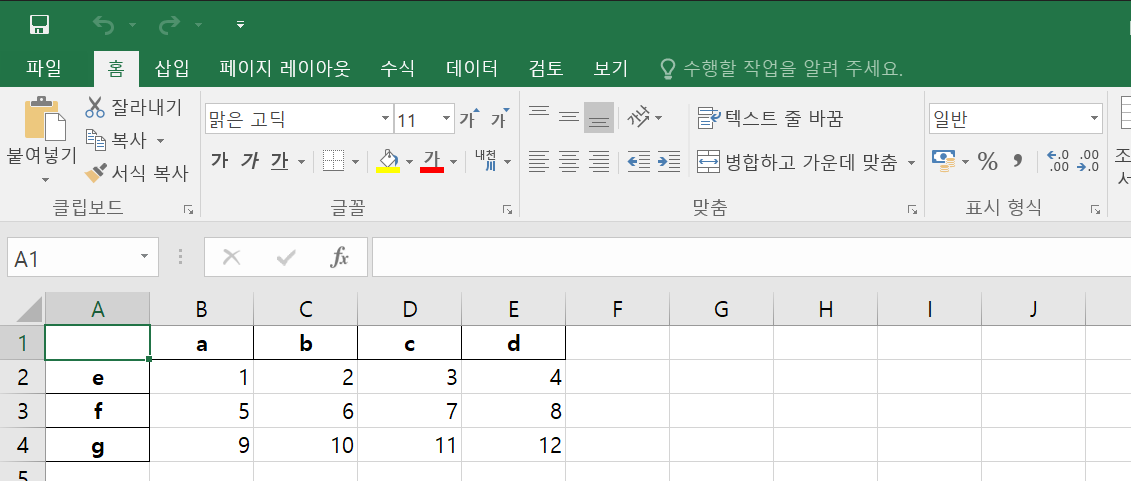
list = [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
column_name = ['a', 'b', 'c', 'd']
index_name = ['e', 'f', 'g']
df = pandas.DataFrame(list, index=index_name, columns=column_name)
print(df)
df.to_excel("C:/python/Workspace/list_export.xlsx", sheet_name="sample1")
#실행결과
C:UsersilikeAppDataLocalProgramsPythonPython39python.exe C:/python/Workspace/main.py
a b c d
e 1 2 3 4
f 5 6 7 8
g 9 10 11 12
Process finished with exit code 0
엑셀파일을 열어서 확인해봅니다.
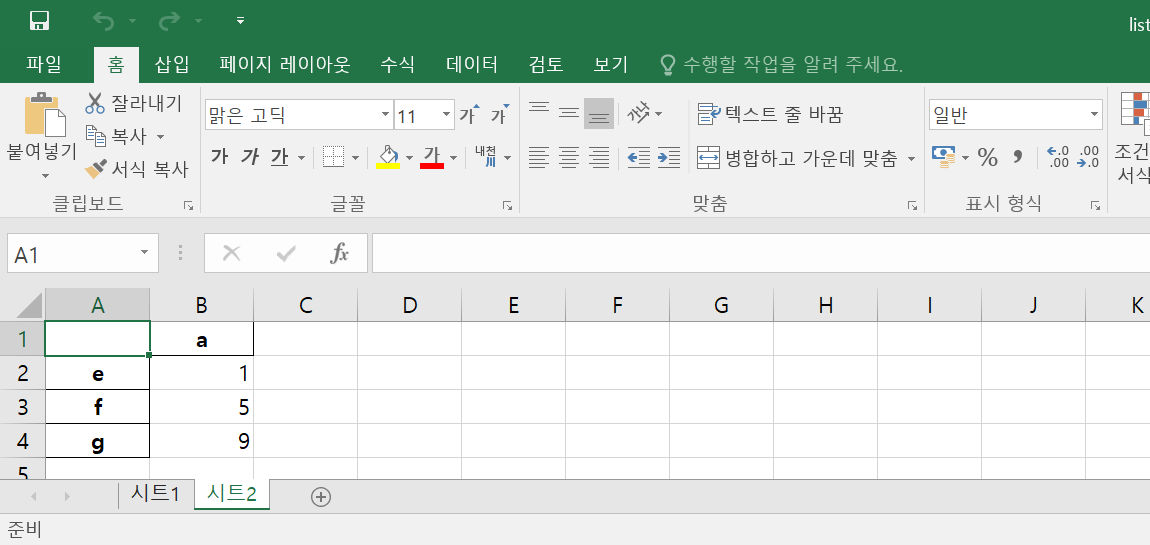
■엑셀 파일로 저장시 여러개의 sheet로 저장하는 방법
pandas.ExcelWriter()함수를 사용하여 여러개의 시트로 저장할 수 있습니다. with문으로 처리하는 경우 wirter.save()와 writer.close()함수를 호출하지 않아도 되는 장점이 생기죠.
import pandas
list = [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
column_name = ['a', 'b', 'c', 'd']
index_name = ['e', 'f', 'g']
df = pandas.DataFrame(list, index=index_name, columns=column_name)
print(df)
list2 = [[1], [5], [9]]
column_name2 = ['a']
index_name2 = ['e', 'f', 'g']
print(f'-'*30)
print(df2)
with pandas.ExcelWriter("C:/python/Workspace/list_export.xlsx") as excel_writer:
df.to_excel(excel_writer, sheet_name="시트1")
df2.to_excel(excel_writer, sheet_name="시트2")
#실행결과
a b c d
e 1 2 3 4
f 5 6 7 8
g 9 10 11 12
------------------------------
a
e 1
f 5
g 9
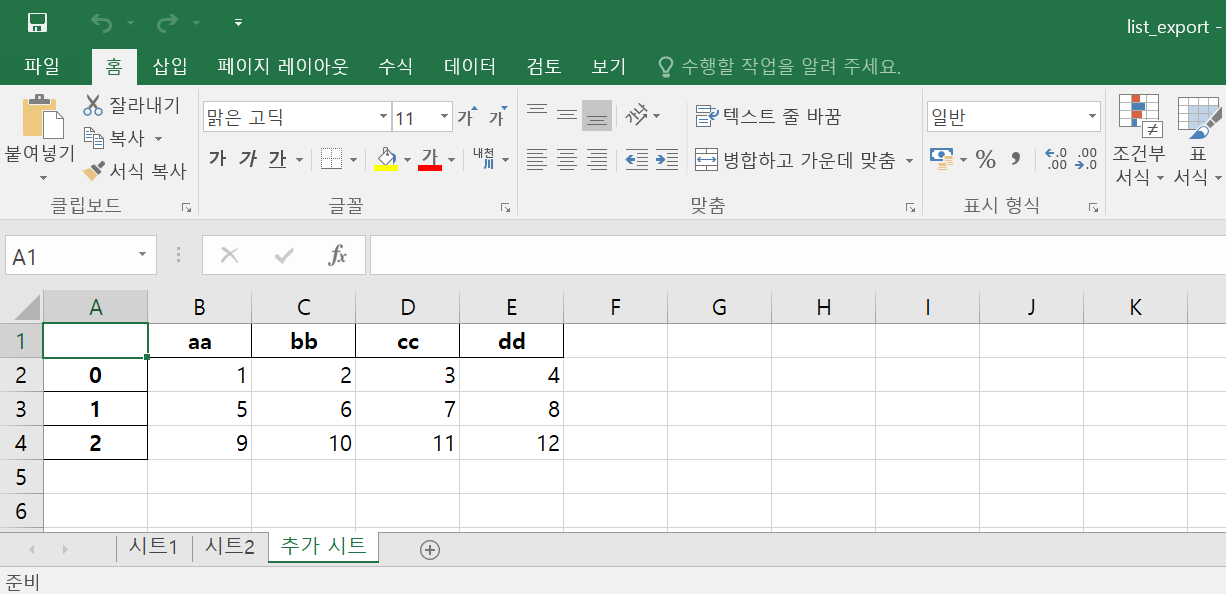
■기존 엑셀파일에 시트를 추가하는 방법
openpyxl모듈을 사용하여 excel_writer의 속성값 중에 book속성에 load_workbook()함수를 설정하여 파일을 읽어와서 추가할 수 있습니다.
import pandas
import openpyxl
list = [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
column_name = ['aa', 'bb', 'cc', 'dd']
df = pandas.DataFrame(list, columns=column_name)
print(df)
with pandas.ExcelWriter("C:/python/Workspace/list_export.xlsx") as excel_writer:
excel_writer.book = openpyxl.load_workbook("C:/python/Workspace/list_export.xlsx")
df.to_excel(excel_writer, sheet_name="추가 시트")
#실행결과
aa bb cc dd
0 1 2 3 4
1 5 6 7 8
2 9 10 11 12
■엑셀파일(xlsx) 읽어오기
read_excel()함수를 사용합니다. 그리고 하나 더 xlrd모듈이 필요합니다.
import pandas
import xlrd
excel_dataFrame = pandas.read_excel("./뉴스.xlsx")
#df = pandas.ExcelFile('뉴스.xlsx').parse('Sheet1')
#excel_dataFrame = pandas.read_html("./뉴스.xlsx") #import lxml 필요
print(f'excel_dataFrame 자료형: {type(excel_dataFrame)}')
print(excel_dataFrame)xlrd모듈을 불러올 수 없는 경우 아래와 같은 오류가 발생하게 됩니다. ImportError: Missing optional dependency 'xlrd'. Install xlrd
C:UsersilikeAppDataLocalProgramsPythonPython39python.exe C:/python/Workspace/main.py
Traceback (most recent call last):
File "C:pythonWorkspacemain.py", line 3, in <module>
excel_dataFrame = pandas.read_excel("C:pythonWorkspace뉴스.xlsx")
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespandasutil_decorators.py", line 296, in wrapper
return func(*args, **kwargs)
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespandasioexcel_base.py", line 304, in read_excel
io = ExcelFile(io, engine=engine)
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespandasioexcel_base.py", line 867, in __init__
self._reader = self._engines[engine](self._io)
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespandasioexcel_xlrd.py", line 21, in __init__
import_optional_dependency("xlrd", extra=err_msg)
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespandascompat_optional.py", line 110, in import_optional_dependency
raise ImportError(msg) from None
ImportError: Missing optional dependency 'xlrd'. Install xlrd >= 1.0.0 for Excel support Use pip or conda to install xlrd.저런, 또 다른 xlrd.biffh.XLRDError Excel xlsx file; not supported 오류가 발생합니다. 불러오려고 하는 엑세파일은 to_excel()함수를 사용하여 생성한 파일입니다.
C:UsersilikeAppDataLocalProgramsPythonPython39python.exe C:/python/Workspace/main.py
Traceback (most recent call last):
File "C:pythonWorkspacemain.py", line 4, in <module>
excel_dataFrame = pandas.read_excel("./뉴스.xlsx")
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespandasutil_decorators.py", line 296, in wrapper
return func(*args, **kwargs)
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespandasioexcel_base.py", line 304, in read_excel
io = ExcelFile(io, engine=engine)
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespandasioexcel_base.py", line 867, in __init__
self._reader = self._engines[engine](self._io)
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespandasioexcel_xlrd.py", line 22, in __init__
super().__init__(filepath_or_buffer)
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespandasioexcel_base.py", line 353, in __init__
self.book = self.load_workbook(filepath_or_buffer)
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagespandasioexcel_xlrd.py", line 37, in load_workbook
return open_workbook(filepath_or_buffer)
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagesxlrd__init__.py", line 170, in open_workbook
raise XLRDError(FILE_FORMAT_DESCRIPTIONS[file_format]+'; not supported')
xlrd.biffh.XLRDError: Excel xlsx file; not supportedxlrd.open_workbook()함수를 사용하여 실행하였습니다. 그러나 동일한 오류가 발생하였습니다.
wb = xlrd.open_workbook("./뉴스.xlsx")xlrd.biffh.XLRDError : Excel xlsx file; not supported
C:UsersilikeAppDataLocalProgramsPythonPython39python.exe C:/python/Workspace/main.py
Traceback (most recent call last):
File "C:pythonWorkspacemain.py", line 8, in <module>
wb = xlrd.open_workbook("./뉴스.xlsx")
File "C:UsersilikeAppDataLocalProgramsPythonPython39libsite-packagesxlrd__init__.py", line 170, in open_workbook
raise XLRDError(FILE_FORMAT_DESCRIPTIONS[file_format]+'; not supported')
xlrd.biffh.XLRDError: Excel xlsx file; not supported
Process finished with exit code 1
xlsx파일은 지원하지 않나봐요???? 네 검색을 해보니 더 이상 지원하지 않는다고 합니다. 그렇기 때문에 xlsx파일을 읽어오려면 engine="openpyxl" 인자값을 설정해주어야합니다.
import pandas
import xlrd
excel_dataFrame = pandas.read_excel("./뉴스.xlsx", engine="openpyxl")
#df = pandas.ExcelFile('뉴스.xlsx').parse('Sheet1')
#excel_dataFrame = pandas.read_html("./뉴스.xlsx") #import lxml 필요
print(f'excel_dataFrame 자료형: {type(excel_dataFrame)}')
print(excel_dataFrame)
#실행결과
excel_dataFrame 자료형: <class 'pandas.core.frame.DataFrame'>
Unnamed: 0 ... 이미지 URL
0 0 ... https://d1lawh9lju1xqd.cloudfront.net/2020/09/...
1 1 ... https://d1lawh9lju1xqd.cloudfront.net/2020/09/...
2 2 ... https://d1lawh9lju1xqd.cloudfront.net/2020/09/...
3 3 ... https://d1lawh9lju1xqd.cloudfront.net/2020/09/...
4 4 ... https://d1lawh9lju1xqd.cloudfront.net/2020/09/...
5 5 ... https://d1lawh9lju1xqd.cloudfront.net/2020/09/...
6 6 ... https://d1lawh9lju1xqd.cloudfront.net/2020/09/...
7 7 ... https://d1lawh9lju1xqd.cloudfront.net/2020/07/...
8 8 ... https://d1lawh9lju1xqd.cloudfront.net/2020/07/...
9 9 ... https://d1lawh9lju1xqd.cloudfront.net/2020/07/...
10 10 ... https://d1lawh9lju1xqd.cloudfront.net/2020/07/...
11 11 ... https://d1lawh9lju1xqd.cloudfront.net/2020/07/...
12 12 ... https://d1lawh9lju1xqd.cloudfront.net/2020/07/...
13 13 ... https://d1lawh9lju1xqd.cloudfront.net/2020/07/...
14 14 ... https://d1lawh9lju1xqd.cloudfront.net/2020/06/...
15 15 ... https://d1lawh9lju1xqd.cloudfront.net/2020/06/...
[16 rows x 5 columns]
read_excel()함수의 인자값을 살펴보면 많은 인자값을 받아서 처리할 수 있습니다. 기본값이 지정되어 있음으로 별도로 설정하지 않으면 기본값이 인자로 넘어감으로 코딩시 편하네요. 내가 원하는 조건에 맞게 엑셀의 데이터를 가져올 경우 설정하면 유용합니다.
def read_excel(
io,
sheet_name=0,
header=0,
names=None,
index_col=None,
usecols=None,
squeeze=False,
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skiprows=None,
nrows=None,
na_values=None,
keep_default_na=True,
na_filter=True,
verbose=False,
parse_dates=False,
date_parser=None,
thousands=None,
comment=None,
skipfooter=0,
convert_float=True,
mangle_dupe_cols=True,
):
read_excel()함수의 인자(파라미터) 정리
| 인자값 | 내용 |
| sheet_name | 0 : 첫번째 시트, 1 : 두번째 시트 문자열 sheet_name = "sheet1" |
| header | 칼럼명칭 행을 제외하고 싶은 경우 1로 설정 |
| names | 칼럼명칭 변경하고자 할때 설정 ["칼럼1", "칼럼2"] |
| index_col | 열을 제외하고 싶은경우 설정 1을 설정하면 2번째 열이 제외됨 |
| usecols | 불러오고자 하는 열을 지정 "A,B, C:F" |
| dtype | 열의 데이터 타입을 지정 |
| skiprows | 엑셀을 읽어올때 제외할 마지막 행 3을 지정하면 0부터 3행까지 제외하고 가져옴 |
| nrow | skiprows와 반대 개념 |
| na_values | 값이 없을때 기본값으로 지정할때 사용 |
| thousands | 천단위 구분자 설정 숫자, 금액 등의 값을 가져올때 1000단위 마다 구분자 추가 |
| skipfooter | 엑셀시트의 마지막행 기준으로 제외할 행 지정 3으로 지정하면 마지막행 포함하여 위쪽 행의 3개를 제외하고 가져옴 |
usecols예제 : 엑셀에서 원하는 열만 가져오는 방법 : A,B,C 열 데이터만 가져오도록 처리, usecols="A,B:C" 또는 usecols="[0,1,2]"로 설정하여 가져 올 수 있습니다.
import pandas
import xlrd
excel_dataFrame = pandas.read_excel("./뉴스.xlsx", engine="openpyxl"
, sheet_name="TEST1"
, usecols="A,B:C")
print(excel_dataFrame)
#실행결과
Unnamed: 0 뉴스제목 기사 날짜
0 0 '횡령범' 몰린 국회인턴, 경찰서 '무혐의'...검찰이 종결 안해 큰 고통 2020.09.18
1 1 21대 국회에 물었다..."국회개혁 의지 있나요" 2020.09.18
2 2 국회세금도둑 3년 추적기-의원님과 인턴 2020.09.17
3 3 <국회세금도둑 추적 2020> 임기 끝났다고 ‘끝이 아니다’ 2020.09.03
4 4 [국회 세금도둑]① 김정훈, 특정인에 '표절 연구' 몰아주고 세금 4천만 원 '펑펑' 2020.09.03
5 5 [국회 세금도둑]② 백재현 표절 정책연구 추가 확인, 박선숙・신창현은 반납 2020.09.03
6 6 [국회 세금도둑]③ 조원진, 권석창, 김용태 '예산 오남용'...환수 방법 없어 2020.09.03
7 7 국회의 또 다른 혈세낭비...발간비와 여론조사 2020.07.22
8 8 [국회 세금도둑]① 국회의원 '발간비' 허위·과다 청구...혈세 낭비 2020.07.22
9 9 [국회 세금도둑]② 정책개발비로 의원 개인홍보 여론조사...국회규정 위반 2020.07.22
10 10 '국회 세금도둑 추적 2020'...여야 의원 7명 공개 2020.07.14
11 11 [국회 세금도둑]①김태흠·송옥주·이학영 정책연구 표절 인정...예산 반납하겠다 2020.07.14
12 12 [국회 세금도둑]②임종성·어기구도 정책연구 표절...혈세 낭비 불감증 2020.07.14
13 13 [국회 세금도둑]③'표절 질타' 이용호·이종배...표절 정책자료집 발간 2020.07.14
14 14 '국회 세금도둑 추적 2020'...국회예산 이렇게 샜다 2020.06.04
15 15 [국회 세금도둑]① 정책용역보고서 천여 건 입수...혈세 낭비 또 확인 2020.06.04
Process finished with exit code 0
■특정 문자열 찾기
엑셀 파일을 읽어왔으니, 작업을 해볼까요?
내가 원하는 주제를 찾아봅니다. 뉴스제목 칼럼에서 "예산"이라는 단어가 들어간 뉴스를 찾아보는 샘플코드 입니다.
값이 존재하면 True값을 반환하고, 그렇지 않으면 False를 반환합니다. str.contains()함수의 인자값으로 case 값을 False로 지정하면 대소문자를 구분하지 않고 찾을 수 있습니다.
import pandas
excel_dataFrame = pandas.read_excel("./뉴스.xlsx", engine="openpyxl"
, sheet_name="TEST1"
, usecols="A,B:C")
print(type(excel_dataFrame))
tmp_df = excel_dataFrame["뉴스제목"].str.contains("예산")
#tmp_df = excel_dataFrame["뉴스제목"].str.contains("예산", case=False)
print(tmp_df)
#실행결과
<class 'pandas.core.frame.DataFrame'>
0 False
1 False
2 False
3 False
4 False
5 False
6 True
7 False
8 False
9 False
10 False
11 True
12 False
13 False
14 True
15 False
Name: 뉴스제목, dtype: boolTrue, False가 아닌 값을 표기해 봅니다.
import pandas
excel_dataFrame = pandas.read_excel("./뉴스.xlsx", engine="openpyxl"
, sheet_name="TEST1"
, usecols="A,B:C")
#print(type(excel_dataFrame))
tmp_df = excel_dataFrame["뉴스제목"].str.contains("예산")
tmp_df2 = excel_dataFrame[tmp_df]
print(tmp_df2)
#실행결과
Unnamed: 0 뉴스제목 기사 날짜
6 6 [국회 세금도둑]③ 조원진, 권석창, 김용태 '예산 오남용'...환수 방법 없어 2020.09.03
11 11 [국회 세금도둑]①김태흠·송옥주·이학영 정책연구 표절 인정...예산 반납하겠다 2020.07.14
14 14 '국회 세금도둑 추적 2020'...국회예산 이렇게 샜다 2020.06.04
Process finished with exit code 0
데이터 삭제하기 : drop()
drop()함수를 사용하여 데이터를 삭제할 수 있습니다.
인자값으로 inplace=False를 설정하는 경우, 원본 데이터의 값을 변경하지 않고 새로 생성하는 데이터프레임(DataFrame)의 경우에만 적용됩니다. inplace=True로 설정하는 경우 원본 데이터의 변경이 발생합니다.
import pandas
excel_dataFrame = pandas.read_excel("./뉴스.xlsx", engine="openpyxl"
, sheet_name="TEST1"
, usecols="A,B:C")
tmp_df = excel_dataFrame.drop([2, 4, 6, 8, 10, 12], inplace=False)
#print(tmp_df)
#원본 데이터 변경
excel_dataFrame.drop([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12], inplace=True)
print('-'*30)
print(excel_dataFrame)
#실행결과
------------------------------
Unnamed: 0 뉴스제목 기사 날짜
0 0 '횡령범' 몰린 국회인턴, 경찰서 '무혐의'...검찰이 종결 안해 큰 고통 2020.09.18
13 13 [국회 세금도둑]③'표절 질타' 이용호·이종배...표절 정책자료집 발간 2020.07.14
14 14 '국회 세금도둑 추적 2020'...국회예산 이렇게 샜다 2020.06.04
15 15 [국회 세금도둑]① 정책용역보고서 천여 건 입수...혈세 낭비 또 확인 2020.06.04
엑셀의 헤더값(칼럼 제목)으로 일괄 삭제할 수 도 있습니다. drop()함수의 인자값으로 헤더명을 써주고 , axis=1을 설정합니다. axis=0은 기본값으로 1로 설정하지 않으면 삭제되지않습니다.
import pandas
excel_dataFrame = pandas.read_excel("./뉴스.xlsx", engine="openpyxl"
, sheet_name="TEST1"
, usecols="A,B:C")
print(excel_dataFrame.drop("기사 날짜", axis=0))
[REFERENCE]
stackoverflow.com/questions/22149584/what-does-axis-in-pandas-mean
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html
blog.naver.com/passionisall/222043627367
stackoverflow.com/questions/16504975/error-unsupported-format-or-corrupt-file-expected-bof-record
Error: Unsupported format, or corrupt file: Expected BOF record
I am trying to open a xlsx file and just print the contents of it. I keep running into this error: import xlrd book = xlrd.open_workbook("file.xlsx") print "The number of worksheets is", book.nshe...
stackoverflow.com
xlrd reading xls XLRDError: Unsupported format, or corrupt file: Expected BOF record; found 'rn'
This is the code: xls = open_workbook('data.xls') In return: File "/home/woles/P2/fin/fin/apps/data_container/importer.py", line 16, in import_data xls = open_workbook('data.xlsx') File "/home...
stackoverflow.com
github.com/equinor/fmu-tools/issues/88
[연관자료]
pypi.org/project/xlrd/#history



