Oracle PRO*C 기초
이번에 새롭게 시작하는 프로젝트가 있는데 PRO*C , 턱시도(미들웨어), 오라클로 이전 시스템이 구성이 되어 있다고 한다. 프로시는 들어봤으나 턱시도는 처음 들어보았네….이러한 AS-IS 환경의 소스코드를 분석하여 스프링부트, 넥사크로, 알티베이스(?) 기반으로 시스템을 다시 개발 하는 프로젝트이다.
이번 프로젝트는 모든게 다 처음인 것들 투성이라 기록해둔다.
Pro*C는 Oracle의 Embedded SQL을 C로 구현하는 솔루션입니다. 이 Pro*C의 프리컴파일러(.pc 파일을 .c 파일로 바꾸어주는)가 바로 proc 입니다.
C 프로그램을 작성해서 기동할 때의 통상의 작업 순서는 다음과 같다.
1. C 프로그램을 작성한다.
2. 프로그램을 컴파일해서 오브젝트 파일을 작성한다.
3. 오브젝트 파일을 링크해서 실행 가능한 파일을 작성한다.
4. 프로그램을 실행한다.
프로그래머가 소스프로그램에 Pro*C 문을 짜넣는 경우는, 위에서 기술한 순서에
한가지 처리가 더 추가된다.
1. Pro*C 프로그램을 작성한다.
2. Pro*C를 이용해서 프로그램을 프리컴파일 한다.
3. 프로그램를 컴파일해서 오브젝트 파일을 작성한다.
4. 오브젝트 파일을 링크해서 실행 가능한 파일을 작성한다.
5. 프로그램을 실행한다.
Pro*C 란? - Pro*C는 오라클 데이터베이스와 연동할 수 있는 C 프로그램이다. 미들웨어 프로그램(Tuxedo, Tmax, Entera) - 오라클에서 제공하는 전처리 컴파일러 : Pre-Compiler > C프로그램에 포함된 SQL 문장 -> C함수 호출로 변환한다. - 오라클 Pro*C의 특징 > 전처리 컴파일러 > C 프로그램 코드 안에 "SQL 명령어"의 사용을 가능하게 한다. > Pro*C로 작성된 프로그램의 확장자 : .pc > .pc 프로그램의 기본 문법은 C언어 문법을 따른다. Pro*C를 사용하는 이유 > 비교적 쉽게 데이터베이스 연동 프로그램의 작성이 가능하다. > SQL과 가장 가까운 형태의 코드를 사용하여 프로그램이 가능하다. > C를 이용하여 데이터 베이스 기능을 "직접" 호출하는 것 보다 쉽다. Pro*C 를 이용한 프로그램 개발 과정 ① .pc 소스 코드 작성 : C언어 + SQL 명령어 ② Pro*C 전처리 컴파일러를 사용하여 컴파일 -> .c 파일 생성 ③ C컴파일러를 사용하여 컴파일 -> .o 오브젝트 파일 생성 ④ .o 파일을 오라클 라이브러리와 함께 링크 -> 실행파일 생성
컴파일과정 fileName.pc → fileName.c → fileName.o > fileName* (생성된 오브젝트 파일을 링크해서 실행파일을 만드는 과정) [파일명].pc파일 생성 후 pc파일이 있는 디렉토리에서 procmake [파일명] 실행. bin 폴더에 [파일명]* →파일 생성됨.
PRO*C를 이용해 오라클 DB로 프로세스를 개발 하기전에 알아둬야할 소스파일 생성 및 컴파일 방법
1. 소스파일 생성 일반적인 C 의 파일은 .c 확장자를 가지지만 PRO*C 는 .pc 확장자를 가지므로최초 소스파일을 생성해 코딩을 할때 .pc 확장자를 줘야 한다.( 오라클 : .pc / 알티베이스 : .sc 그외는 개발해보질 않아서 잘 모르겠네요.. )
2. 컴파일 방법. C 언어등으로 개발을 하면 gcc 를 통해 바로 컴파일을 끝내지만 PRO*C 를 이용해 개발을 진행하게 되면 두번의 컴파일 과정을 진행해야 합니다. 일반 : .c -> 실행파일 / .c -> .o -> 실행파일 PRO*C : .pc -> c -> 실행파일 / .pc -> .c -> .o -> 실행파일 .pc 파일을 .c 로 컴파일 해주면 그뒤로는 c언어로 개발한 소스를 컴파일 하듯이 동일하게 해주면 됩니다. .pc 파일 컴파일 명령어 .proc sqlcheck=full userid=아이디/패스워드 DBMS=v7 iname=소스파일이름.pc 위와 같이 컴파일 명령을 내리면 .pc 확장자를 가진 파일이 .c 파일로 생성이 됩니다.( 컴파일된 .c 파일을 열어보면 내가 작성한것과 다르게 마구마구 복잡하게 수정되 있는 소스가 나옴..싱기방기 )이제 .c 파일을 ~ gcc 명령어를 통해 다시 재컴파일해 실행파일로 만들면 끝~
Pro*C 프로씨 컴파일 환경 구축
Pro*C :프로씨 개발을 하려면 두 가지 설치과정이 필요하다.
1. C 컴파일러
2. 오라클 & 오라클에 포함된 Pro*C Pre 컴파일러
※ 오라클 배포판 중에서도 Pro*C 컴파일러를 포함하는 버전을 설치해야 한다.
Pro*C는 오라클 SE이상 버전에만 내장되어 있어요.
| 1. gcc 컴파일러 설치 & 버전 확인 |
1) 설치
# sudo yum gcc
2) 확인
# gcc -v
| 2. 오라클 & Pro*C 컴파일러 설치 |
– Pro*C는 오라클 SE이상 버전에만 내장되어 있어요.
– XE를 설치했다면 Pro*C 모듈을 따로 설치하고 오라클 연동설정을 해줘야되요.
– 저는 오라클 SE로 설치했어요.
1) 리눅스 오라클 SE 설치하기
– http://www.oracle.com/technetwork/database/enterprise-edition/downloads/index.html
– GUI 모드에서 편하게 진행 > NEXT > NEXT > NEXT > FINISH
2) 설치 후 환경설정 등록
– 리눅스는 계정마다 환경설정 파일(.bash_profile)이 있어요
– 오라클용 계정의 .bash_profile이라는 파일에 오라클 설치 경로를 설정해줘야되요
[test@localhost ~]$ cd ~
[test@localhost ~]$ pwd
home/test
[test@localhost ~]$ ls -al | grep profile
-rwxr-xr-x 1 test smbgrp 313 Aug 11 03:45 .bash_profile
[test@localhost ~]$ vi ./.bash_profile
export ORACLE_HOME=/home/bong/app/test/product/12.1.0/dbhome_1
export ORACLE_SID=SE
export PATH=$PATH:$ORACLE_HOME/bin
– 설치 경로가 아래와 같을 경우 위와 같이 적어줘요.
– bin은 실행파일 디렉토리. 오라클 실행파일들을 실행하기 위해 PATH를 등록해주는 것
3) 확인
– 오라클
[bong@localhost dbhome_1]$ sqlplus
– 프로씨
[bong@localhost ~]$ proc
make 유틸리티 :
“makefile” 이라는 특수한 형식에 저장되어 있는 일련의 의존규칙들에 근거하여 화일을 최신 버전으로 개정하는 유틸리티이다 .
-f 옵션은 만들고자 하는 화일 이름을 명시할 수 있게 한다 . 만일 이름이 명시되지 않으면 , “makefile” 로 간주한다 . ProC 의 makefile 은 $ORACLE_HOEM/precom/demo/proc 에 존재하는 proc.mk 를 자신의 작업 디렉토리에 copy 하여 변경하여 작성하면 된다 . proc.mk 화일은 ProC 프로그램을 컴파일하여 실행화일을 생성하는 일련의 작업들을 기술해 놓은 것이다 .
위의 명령은 proc.mk 라는 makefile 을 이용하여 makefile 안에 있는 sample1 이란 lable 의 구성대로 실행한다 . sample1 이라는 lable 에는 proc 를 구동시키고 , cc 를 구동시키는 부분을 정의한다.
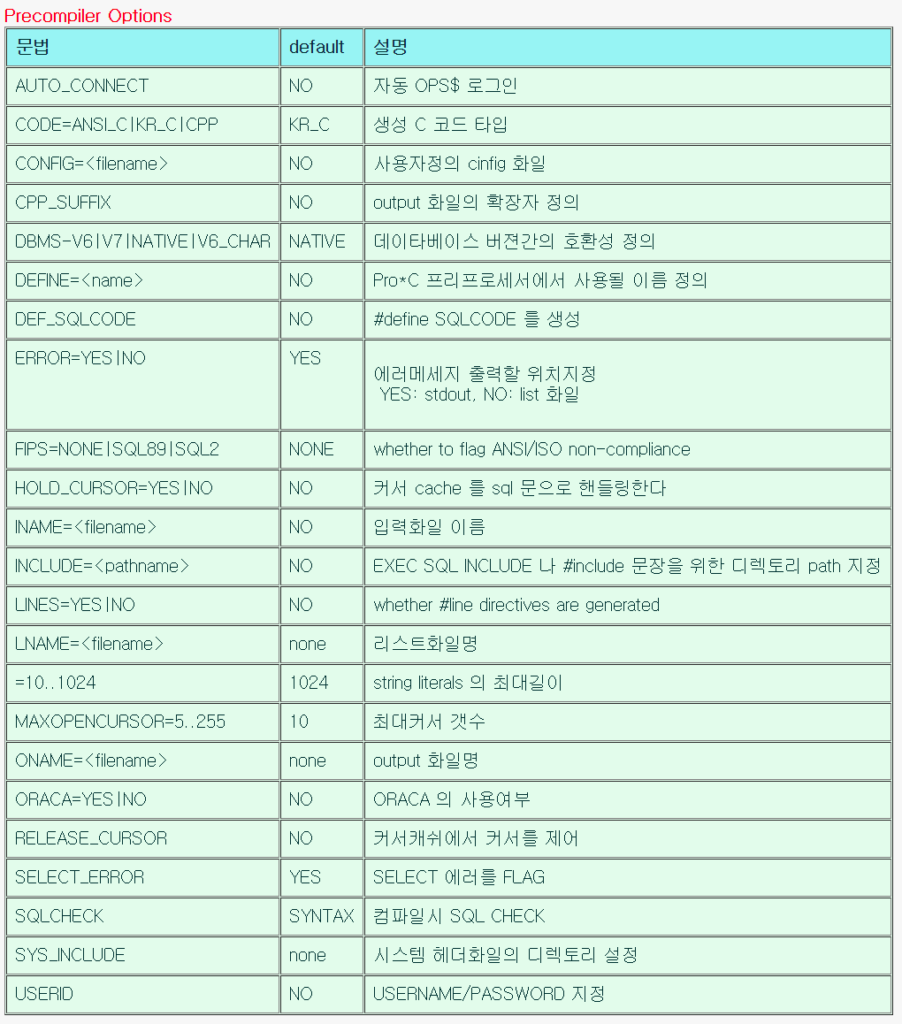
Precompiler Options
| 문법 | default | 설명 |
| AUTO_CONNECT | NO | 자동 OPS$ 로그인 |
| CODE=ANSI_C|KR_C|CPP | KR_C | 생성 C 코드 타입 |
| CONFIG=<filename> | NO | 사용자정의 cinfig 화일 |
| CPP_SUFFIX | NO | output 화일의 확장자 정의 |
| DBMS-V6|V7|NATIVE|V6_CHAR | NATIVE | 데이타베이스 버젼간의 호환성 정의 |
| DEFINE=<name> | NO | Pro*C 프리프로세서에서 사용될 이름 정의 |
| DEF_SQLCODE | NO | #define SQLCODE 를 생성 |
| ERROR=YES|NO | YES | 에러메세지 출력할 위치지정 YES: stdout, NO: list 화일 |
| FIPS=NONE|SQL89|SQL2 | NONE | whether to flag ANSI/ISO non-compliance |
| HOLD_CURSOR=YES|NO | NO | 커서 cache 를 sql 문으로 핸들링한다 |
| INAME=<filename> | NO | 입력화일 이름 |
| INCLUDE=<pathname> | NO | EXEC SQL INCLUDE 나 #include 문장을 위한 디렉토리 path 지정 |
| LINES=YES|NO | NO | whether #line directives are generated |
| LNAME=<filename> | none | 리스트화일명 |
| =10..1024 | 1024 | string literals 의 최대길이 |
| MAXOPENCURSOR=5..255 | 10 | 최대커서 갯수 |
| ONAME=<filename> | none | output 화일명 |
| ORACA=YES|NO | NO | ORACA 의 사용여부 |
| RELEASE_CURSOR | NO | 커서캐쉬에서 커서를 제어 |
| SELECT_ERROR | YES | SELECT 에러를 FLAG |
| SQLCHECK | SYNTAX | 컴파일시 SQL CHECK |
| SYS_INCLUDE | none | 시스템 헤더화일의 디렉토리 설정 |
| USERID | NO | USERNAME/PASSWORD 지정 |
프리컴파일 옵션의 영향 범위
위의 옵션들은 하나의 C 소스 프로그램에서만 유효하다 . 만약 A 라는 UNIT 에 프리컴파일러 옵션인 HOLD_SURDOR=YES 그리고 RELEASE_CURSOR=YES 가 정의되어 있고 , B UNIT 에는 없다면 A 는 옵션의 영향을 받고 B 는 DEFAulT 값의 영향을 받는다.
프리컴파일 옵션의 사용
프리컴파일 옵션은 명령행에서도 사용가능하고 또 SOURCE 에 포함할 수도 있다.
명령행에서의 사용은
[OPTION_NAME=value] [OPTION_NAME=value] ...
로 사용하고 각각의 옵션사이는 공백으로 구분한다 .
예를 들어
CODE=ANSI_C MODE=ANSI
또 인라인으로 SOURCE 내에 삽입하여 사용가능한데 , 이때는 "EXEC ORACLE" 이라는
문구를 사용하여 삽입한다.
EXEC ORACLE OPTION (OPTION_NAME=value);
예를 들어
EXEC ORACLE OPTION (RELEASE_CURSOR=yes);
SOURCE 파일에 포함되어진 옵션들도 명령행이나 CONFIGURATION 화일에 중복하여
사용할 수 있다.
이 "EXEC ORACLE" 구문은 특히 프리컴파일 도중에 옵션을 변경할 때 유용하다.
EXEC ORACLE 의 유효범위는 SOURCE 화일내에 같은 옵션으로 EXEC ORACLE 이
사용된 이전까지 유효하다.
AUTO_CONNECT: 자동으로 OPS$ 계정으로 connect 한다.
YES 이면 어플리케이션 프로그램이 첫 SQL 문장을 실행할 시점에서 OPT$ 계정으로
CONNECT를 시도한다. NO 이면 자동 CONNECT 는 되지 않고 SOURCE 화일내에 CONNECT
문장이 존재해야 한다.
CODE : C 함수의 어떤 프로토타입을 생성시키는 지정한다.
ANSI_C 는 X3.159-1989 에서 제공한 표준을 제공한다 . ANSI_C 표준으로 생성한다.
extern void(sqlora(long *, void *);
CODE=KR_C 이면
extern void sqlora(/*_ long *, void * */);
CODE=CPP 이면 C++ 에 맞는 SOURCE CODE 를 생성시킨다 .
CONFIG : 사용자 지정 CONFIGURATION 화일을 지정한다.
각 라인마다 한개의 옵션이 들어가게 화일을 생성해 이름을 지정한다.
CPP_SUFFIX: C++ 옵션으로 SOURCE 화일의 확장자를
지정한다.
DBMS : 문법을 정의한다 .
NATIVE : 접속되는 데이타 베이스에 SETTING 된 테이블에 따른다 .
DEF_SQLCODE:#define SQLCODE sqlca.sqlcode
DEFINE : 프리프로세서의 매크로를 컴파일 시점에서 선언한다.
SOURCE 화일에 아래와 같이 정의 되어 있다면
#ifdef XYZZY
....
#else
...
#endif
proc my_prog DEFINE=XYZZY EXEC ORACLE IFDEF XYZZY;
...
EXEC ORACLE ELSE;
...
EXEC ORACLE ENDIF;
로 프리컴파일하면
#define XYZZY 를 SOURCE 에 포함시킨것과 같다.
도 같은 효과를 나타낸다.
ERRORS: 에러를 터미널로 보낼 것인지 (NO), 리스트 화일로 보낼 건지를 (YES) 결정
HOLD_CURSOR : SQL 문이나 PL/SQL 블럭을 커서 캐쉬안에서 보관시킬 건지를 결정한다.
INAME: SOURCE 화일명을 명시한다.
proc sample MODE=ANSI
proc INAME=sample1 MODE=ANSI
INCLUDE : 컴파일시 포함되어져야 할 화일의 디렉토리명을 명시한다.
#include 나 EXEC SQL INCLUDE 문에서 명시된 화일들이 위치한 곳을 명시한다.
컴파일시 헤더 화일을 찾는 순서는
1. SYS_INCLUDE 로 지정되어진 디렉토리
2. 현재 디렉토리
3. standard 헤더 화일의 디렉토리
4. INCLUDE 옵션으로 지정된 디렉토리
IRECLEN : SOURCE 화일의 한 라인의 길이를 정한다.
default 로 80 으로 지정되어 있다 .
LNAME:리스트 화일의 이름을 명시한다 .
LRECLEN:리스트 화일의 한 라인의 길이를 나타낸다 .( 기본값 :132)
LTYPE:생성될 리스트 화일의 타입을 설정한다 .( 기본값:LONG)
MAXLITERAL (8~1024) 사이의 값으로 문자 LITERAL 의 최대길이를 설정한다.
( 기본값 1024)
MAXOPENCURSORS:동시에 OPEN 할 수 있는 최대 커서의 갯수를 설정한다.
(5~255) 기본값:10
ONAME:OUTPUT 화일명을 명시한다. proc iname=my_test
proc iname=my_test oname=my_test_1.c
기본적으로 INAME 의 뒤에 CPP_SUFFIX 를 붇여 출력한다 .
ORACA:ORACA 의 사용여부를 설정한다 .
ORACA=YES 면 SOURCE 프로그램내에 EXEC SQL INCLUDE ORACA.H 나
#include oraca.h 를 포함해야만 한다.
ORECLEN:OUTPUT 화일의 한 라인의 길이를 설정 ( 기본값 80), (80~255)
PAGELEN:리스트화일의 PAGE 길이를 설정 ( 기본값 없음 )(30~255)
RELEASE CURSOR:커서의 보관을 취소한다.
SQLCHECK:SQL 문의 검사를 설정한다.
SQLCHECK=SEMANTICS
데이타조작문 , PL/SQL 블럭 , 호스트변수의 데이타 타입을 검사
SQLCHECK=FULL
SQL 문장 및 데이타베이스에 접속해 현재의 SQL 문장의 유효성을 검사한다.
USERID 가 정의되어 있어야 한다.
SQLCHECK=SYNTAX
SQL 문장의 문법적인 오류만 검사
SQLCHECK=SYMANTICS
PL/SQL 블럭이 SOURCE 내에 포함되어 있으면 USERID 와 함께 이 옵션을 써야 한다.
SYS_INCLUDE:시스템 헤더 화일의 디렉토리를 설정한다.
USERID:오라클 USERID 와 PASSWORD 를 명시한다.
USERID=username/password
간단한 proc 프로그램 예제
다음은 zipcode 테이블에 총몇개의 자료가 들어있는지 알아오는 간단한 프로그램이다.
예제 : zipcode.pc
#include <stdio.h>
#include <unistd.h>
/* SQLCA 를 선언한다 */
EXEC SQL INCLUDE SQLCA;
int main(int argc, char **argv)
{
/* 선언부 */
EXEC SQL BEGIN DECLARE SECTION;
int count = 0;
char userid[40]= "system/manager@ORACLE";
EXEC SQL END DECLARE SECTION;
/* DB 연결 */
EXEC SQL CONNECT :userid;
/* 에러 처리 */
if (sqlca.sqlcode < 0)
{
printf("%s\n", sqlca.sqlerrm.sqlerrmc);
EXEC SQL ROLLBACK WORK RELEASE;
exit(0);
}
/* 쿼리 */
EXEC SQL SELECT count(*)
INTO: count
FROM zipcode;
/* 쿼리 결과에 대한 에러처리 */
if (sqlca.sqlcode != 0)
{
EXEC SQL COMMIT WORK RELEASE;
return 0;
}
printf("우편주소 데이타 : %d 개\n", count);
/* DB 연결 종료 */
EXEC SQL COMMIT WORK RELEASE;
}
오라클 proc 파일에서의 주석은 /* */ 만 사용 가능하다. // 사용하면 오류가 발생한다.
[컴파일 하기] 우선 zipcode.pc 파일을 proc 선행 컴파일러를 이용해서 zipcode.c 파일을 얻어낸다음 gcc를 이용해서 object 파일을 만들고 링크과정을 거쳐서 실행파일을 만들어야 한다. 다음은 이러한 일련의 과정이다. [oracle@localhost proc]$ proc zipcode INCLUDE=include/ \ > include=/usr/u01/product/8.1.7/precomp/public/ \ > include=/usr/u01/product/8.1.7/rdbms/demo/ \ > include=/usr/u01/product/8.1.7/rdbms/public/ \ > include=/usr/u01/product/8.1.7/network/public/ \ > PARSE=NONE RELEASE_CURSOR=YES MODE=ANSI Pro*C/C++: Release 8.1.7.0.0 - Production on Thu Oct 31 00:29:15 2002 (c) Copyright 2000 Oracle Corporation. All rights reserved. System default option values taken from: /usr/u01/product/8.1.7/precomp/admin/pcscfg.cfg [oracle@localhost proc]$ gcc -c -o zipcode.o zipcode.c -I$ORACLE_HOME/precomp/public \ > -I$ORACLE_HOME/rdbms/demo -I$ORACLE_HOME/rdbms/public \ > -I$ORACLE_HOME/network/public [oracle@localhost proc]$ gcc -o zipcode zipcode.o -L$ORACLE_HOME/lib -lclntsh 이 프로그램을 실행시키면 다음과 같은 결과값을 보여줄 것이다. [oracle@localhost proc]$ ./zipcode 우편주소 데이타 : 43476 개 4.2절. 컴파일 과정을 Makefile 로 관리하기하지만 위의 방법대로 수동으로 코드를 컴파일 하는건 비 생산적인 방법이다. 그러므로 Makefile 을 만들어서 관리하도록 하자. [Makefile] TARGET = zipcode CC = gcc PROC = proc LIB = -L$(ORACLE_HOME)/lib -lclntsh MYINC = include/ PROCINC = include=$(ORACLE_HOME)/precomp/public/ include=$(ORACLE_HOME)/rdbms/demo/ \ include=$(ORACLE_HOME)/rdbms/public/ \ include=$(ORACLE_HOME)/network/public/ CINC = -I$(ORACLE_HOME)/precomp/public/ -I$(ORACLE_HOME)/rdbms/demo/ \ -I$(ORACLE_HOME)/rdbms/public/ -I$(ORACLE_HOME)/network/public/ ORA_OPT = PARSE=NONE RELEASE_CURSOR=YES MODE=ANSI CC_OPT = OBJECT = zipcode.o ORA_GARBAGE = *.dcl *.cod *.cud *.lis ######## implicit rules .SUFFIXES: .pc .c .pc.c: $(PROC) $* INCLUDE=$(MYINC) $(PROCINC) $(ORA_OPT) .c.o: $(CC) -c -o $*.o $*.c -I $(MYINC) $(CINC) ####### build rules all: $(TARGET) $(TARGET): $(OBJECT) $(CC) -o $(TARGET) $(OBJECT) $(LIB) zipcode.c: zipcode.pc zipcode.o: zipcode.c clean: rm -f $(TARGET) $(OBJECT) $(ORA_GARBAGE)
Pro*C에서 프로그램 작성 방식
Pro*C에서 프로그램 작성 방식은 두 가지로 나누어지며, 하나는 내장 SQL 방식이고, 다른 하나는 OCI(Oracle Call Interface) 방식이다.
내장 SQL 방식
C 프로그램 내부에서 ‘EXEC SQL’이라는 접두사 뒤에 SQL 문장을 직접 기술하는 방식입니다. 내장 SQL 방식은 통상적으로 가장 많이 사용됩니다 .
일반 SQL 문장뿐만 아니라 오라클을 이용한 다양한 형식의 내부 문장을 사용할 수 있으며, 미리 생성되어 있는 Stored Procedure, Package 또는 개발자가 임의로 작성한 PL/SQL도 사용할 수 있습니다. 즉, 오라클 데이터베이스에서 사용하는 모든 문장, 즉 DML, DDL, DCL, PL/SQL, 일반 SQL 문장을 내장 SQL 문장에 사용할 수 있습니다.
내장 SQL 문장 구문 방식의 프로그램 구문
| 명령어 | 설명 |
| ARRAYLEN | PL/SQL에서 호스트 array를 사용한다. |
| BEGIN DECLARE SECTION END DECLARE SECTION | ANSI 모드에서 호스트 변수를 사용한다. |
| DECLARE | 내부 오브젝트를 선언한다. |
| INCLUDE | 외부 *.h를 참조한다. |
| TYPE | 임의 데이터 타입을 설정한다. |
| VAR | 변수의 동일화 |
| WHENEVER | runtime 에러 핸들링 문장 |
| ALLOCATE | CURSOR 변수에 영역을 할당한다 |
| ALTER | 오라클의 정의 |
| ANALYZE AUDIT COMMENT CONNECT CREATE DROP GRANT NOAUDIT RENAMERE VOKE TRUNCATE CLOSE | 오라클에 접속 제어 오브젝트 변경 문장 |
| DELETE FETCH INSERT LOCK TABLE OPEN SELECT UPDATE EXPLAIN PLAN | 데이터 조작 및 데이터 추출문 |
| COMMIT ROLLBACK SAVEPOINT SET TRANSACTION | 트랜잭션 제어 문 |
| DESCRIBE EXECUTEPREPARE | Dynamic SQL 사용을 위한 문 |
| ALTER SESSION SET ROLE | 세션 제어 문 |
(2) OCI 방식
OCI(Oracle Call Interface) 라이브러리를 통해서 오라클 SQL 문장을 직접 호출하여 사용하는 방식이다. 내장 SQL 프로그램에 비해 복잡하기 때문에 개발자의 숙련도가 요구된다는 단점이 있다.
| 내장 SQL 방식 | OCI 방식 |
| SQL 연산을 쉽고 명료하게 처리하기 위해 3GL 어플리케이션 개발 | 데이터베이스를 최대한 제어하면서 3GL 어플리케이션 개발 |
| 간결한 코드 작성 | 길고 복잡한 코드 작성 |
| 컴파일 전에 소스 코드 선행 컴파일 | 선행 컴파일 단계 없이 코드 컴파일 |
| 선행 컴파일러를 별도로 구매 | 오라클 데이터베이스와 함께 OCI 라이브러리 획득 |
| ANSI 표준 준수(X3.168-1992) | 독점 비 표준 절차적 호출 인터페이스 사용 |
| 다중 행 질의만을 위해 명시적 커서 선언 | 모든 데이터베이스 연산을 처리하기 위한 명시적 커서 선언 |
| 선행 컴파일 시에 SQL 구문 확인 | 실행 시간에 SQL 구문 확인 |
PRO*C 개요
1.2.1 C 커맨드 및 SQL 문의 혼합
올바른 SQL 문이면 C 프로그램에서 실행할 수 있다. Pro*C 프로그램에서는 필수의 구성요소나 문장이 몇 개정도 있는 것 외에 기본적인 “지정순서”가 있지만, C 프로그램내의 어디에 배치해도 좋다
1.2.2 커맨드의 접두사 EXEC SQL
SQL 문을 호스트 언어에 포함시킴으로써, 발생할 수 있는 언어상의 장애를 최소화하기 위해서, 모든 SQL 문에는 EXEC SQL 이라고 하는 접두사를 붙인다.
1.2.3 커맨드의 접두사 EXEC ORACLE
대부분의 Pro*C 문에는 EXEC SQL 이라는 접두사를 붙이지만 EXEC ORACLE 이라는 접두사를 붙인문도 있다. 이들의 문은 SQL과는 호환성이 없고, ORACLE 프리컴파일러 특유의 것이다.
1.2.4 SQL 실행문 및 선언문
Pro*C 프로그램에 포함되어 있는 SQL 문은, 실행문 혹은 선언문중의 하나로 분류할 수 있다. 실행문 혹은 선언문에 관계없이 문에는 모두 EXEC SQL 이라는 접두사가 붙는다.
실행문
실제로 데이터베이스에 대한 콜을 행성하는 SQL 문이다. 데이터조작문(DML), 데이터정의문(DDL), 데이터제어문(DCL) 등이 있다. SQL 실행문을 실행한 후, SQLCA(SQL 통신영역)에는 일련의 리턴코드가 저장된다.
논리적인 작업단위는, 최초의 SQL 실행문을 실행함으로써 시작된다. 그러므로 CONNECT, COMMIT, ROLLBACK WORK 문의 다음에 첫 번째로 나타나는 SQL 실행문부터 논리적인 작업단위가 새롭게 시작된다.
선언문
코드를 생성하지 않기 때문에 논리적인 작업단위에 영향은 없다.
1.2.5 Pro*C 프로그램의 구성
Pro*C 프로그램은 2개의 부분으로 구성되어 있고, Pro*C의 처리에는 양자가 모두 필요하다.
어플리케이션 프롤로그
변수를 정의하고, Pro*C 프로그램을 위한 일반적인 준비를 수행한다.
어플리케이션 본체
ORACLE 데이터를 조작하기 위한 INSERT나 UPDATE 등의 SQL 문을 포함한다. Pro*C가 처리시 필요로 하는 코드의 전후에 어떠한 C 코드를 지정해도 상관없다.
2.1 어플리케이션 프롤로그
** 선언절
** INCLUDE SQLCA 문
** CONNECT 문
2.1.1 선언절 ( 2.0 버젼 이후 없어도 상관 없음 )
C 프로그램내에서 사용된 모든 호스트 변수를 선언한다. 선언절은 아래의 문으로 시작한다.
EXEC SQL BEGIN DECLARE SECTION;
아래의 문으로 종료한다.
EXEC SQL END DECLARE SECTION;
위 두 개의 문 사이에 허용되는 문은 호스트 변수 또는 표지 변수를 선언하는 문 뿐이다.
**호스트 변수
SQL 문 및 프로그램 문의 양쪽으로부터 참조되는 모든 값에 대해서 선언해야 한다. 호스트 변수의 데이터타입은 선언절에서 호스트 언어를 사용해서 선언해야 하며, 이 때 이 데이터타입은 테이블을 정의할 때에 사용되는 ORACLE 데이터타입과 일치할 필요는 없다.
EXEC SQL BEGIN DECLARE SECTION;
int pempno; /* 사번 */
char pname[11]; /* 성명 */
int pdeptno; /* 부서 */
EXEC SQL END DECLARE SECTION;
EXEC SQL SELECT deptno, ename
INTO :pdeptno, :pname
FROM emp
WHERE empno = :pempno;
호스트 변수의 조건
~선언절에서 명시적으로 선언한다.
~선언한 대로 영어 대문자/소문자의 포맷을 사용한다.
~SQL 문에서는 앞에 콜론(:)을 붙인다.
~C 문에서는 앞에 콜론을 붙이지 않는다.
~SQL의 예약어를 사용해서는 안된다.
~상수를 사용할 수 있는 곳에서만 사용한다.
~표지 변수가 붙어 있어도 상관없다.
**표지 변수
선언절에서 선언된 호스트 변수에 1대 1로 대응되는 임의 선택 변수이다. 표지 변수는 주로 널 값을 취급하는데 유효하다
표지 변수의 조건
~선언한 대로 영어 대문자/소문자의 포맷을 사용한다.
~2바이트 정수로써 선언해야 한다.
~SQL 문에서는 앞에 콜론(:)을 붙인다.
~C 문에서는 앞에 콜론을 붙이지 않는다.
~SQL의 예약어를 사용해서는 안된다.
~SQL 문 내에서는 대응하는 입력 호스트 변수를 앞에 붙여 사용한다.
호스트 변수로서의 포인터 선언
포인터 변수는 C에서 통상적으로 행하는 방법으로 선언함으로써, 선언절내에서 사용할 수 있다.
EXEC SQL BEGIN DECLARE SECTION;
int I, j, *intptr;
char *cp;
EXEC SQL END DECLARE SECTION;
SQL 문에서 사용하는 경우는 별표가 아닌 콜론(:)을 변수명 앞에 붙인다.
SELECT intfield INTO :intptr FROM…;
VARCHAR 의사타입의 선언
Proc*C에서는 VARCHAR 의사타입을 사용할 수 있으므로, 가변 길이의 문자열을 처리할 수 있다. VARCHAR 의사타입은 선언절에서 참조할 뿐이고, 확장된 C 타입 또는 사전에 선언된 구조라고 생각할 수 있다.
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR jobDesc[40];
EXEC SQL END DECLARE SECTION;
이 선언은 다음의 구조체로 확장할 수 있다.
struct {
unsigned short int len;
unsigned char arr[40];
} jobDesc;
2.1.2 SQL 통신영역의 선언
어플리케이션 프로롤로그내에서 SQL 통신영역(SQLCA)에 대한 참조를 포함시킴으로써 각 Pro*C 프로그램에서 발생하는 상황처리를 가능하게 하는데, 유저는 다음의 문을 지정하면 된다.
EXEC SQL INCLUDE SQLCA;
Pro*C는 프리컴파일시에 SQLCA 파일의 위치를 알아야 한다. 때문에 유저는 다음의 3가지중 하나를 선택해야 한다.
~~”INCLUDE = ” 커맨드 라인 옵션을 사용한다.
~~Pro*C가 파일을 SYS$ORACLE:SQLCA(VMS의 경우)처럼 공동의 OS영역에서 발견할 수 있도록 파일의 정식 명칭을 지정한다.
~~PCC를 호출할 디렉토리 또는 디스크에 SQLCA를 카피한다.
SQLCA는 다음과 같은 정보를 포함하고 있다.
경고 플래그와 처리상황에 관한 정보
에러 코드
진단 정보
디폴드 값으로서, Pro*C는 가능한한 에러를 무시하고 처리를 속행시킨다. SQLCA내에 포함된 변수를 사용함으로써, 프로그래머는 각각의 환경에서 실행해야 할 처리를 제어할 수 있다.
2.1.3 ORACA(SQLCA에 대한 확장)
ORACA를 사용하기 위해서는 EXEC SQL INCLUDE을 사용해서 ORACA의 정의를 참조하거나 커맨드라인 옵션 또는 EXEC ORACLE OPTION에서 ORACA = YES 옵션을 선택하여야 한다.
2.1.4 ORACA 내의 정보
현재의 SQL 문의 텍스트(orastxt)
ORACLE RDBMS가 해석한 문의 내용을 조사할 수 있다. (CONNECT, FETCH, COMMIT등 은 제외)
~에러가 있는 파일의 이름(orasfnm)
~에러가 있는 행의 번호(oraslnr)
~SQL 문 보존 플래그(orastxtf)
이 플래그를 설정함으로써 어느 조건으로 문을 보존할 지를 선택할 수 있다.
0. 디폴트값. SQL 문을 보존하지 않는다.
1. SQLERROR가 있는 SQL 문 만을 보존한다.
2. SQLERROR 및 SQLWARN이 있는 문을 보존한다.
3. SQL 문을 전부 보존한다.
~DEBUG 처리의 사용 허가 플래그
이 플래그는 0이나 1을 설정할 수 있다.
1을 설정한 경우는 모든 DEBUG 처리를 사용할 수 있다.
커서 캐쉬 검사(orahchf)
2.1.5 ORACLE에의 접속
EXEC SQL CONNECT :oracleid IDENTIFIED BY :oraclepassword;
CONNECT 문은 Pro*C 프로그램 내에서 실행된 최초의 SQL 실행문이어야 한다. 선언문과 C 코드만을 논리적으로 CONNECT 문 앞에 놓을 수 있다. 패스워드를 따로 지정하는 경우는 ORACLE의 유정명과 ORACLE의 패스워드의 양쪽에 대해 호스트 변수를 사용해야 한다.
양쪽의 호스트 변수를 고정길이 문자열 또는 가변길이 문자열 중의 하나로 선언해야 한다.
CONNECT 문을 수행하기 전에 양쪽의 호스트 변수를 초기화켜 놓아야 한다.
CONNECT는 프로그램의 최초의 실행문이지만 논리적인 작업단위의 시작은 아니다.
2.2 어플리케이션 본체
어플리케이션 본체에는 ORACLE 데이터베이스 내에 보존된 데이터를 쿼리하고 조작하기 위한 SQL 문이 들어 있다. 이러한 문은 데이터 조작문이라고 한다. 또한 어플리케이션 본체에는 데이터 정의문이 포함되며 이것은 테이블, 뷰, 인덱스등의 데이터 구조를 작성하거나 정의하기 위해 사용한다.
~DECLARE STATEMENT 문
~DECLARE DATABASE 문
~EXEC ORACLE 옵션
2.3 Pro*C 예제 프로그램
/* 예제 #1 */
ORACLE의 로그온과 로그오프
#include
/***************************************************************
This is sample Pro*C program which will log onto a database as
scott/tiger.
***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
void main(void)
{
/* log into ORACLE */
strcpy(uid.arr, "SCOTT"); /* copy the user name */
uid.len = strlen(uid.arr);
strcpy(pwd.arr, "TIGER"); /* copy the password */
pwd.len = strlen(pwd.arr);
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
printf("Connected to ORACLE user : %s\n", uid.arr);
EXEC SQL COMMIT WORK RELEASE; /* log off database */
exit(0);
}
/* 예제 #2 */
테이블의 작성
#include
/***************************************************************
This is is a sample Pro*C program which will create a table.
***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
void main(void)
{
/* log into ORACLE */
strcpy(uid.arr, "SCOTT"); /* copy the user name */
uid.len = strlen(uid.arr);
strcpy(pwd.arr, "TIGER"); /* copy the password */
pwd.len = strlen(pwd.arr);
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
printf("Connected to ORACLE user : %s\n", uid.arr);
EXEC SQL CREATE TABLE Emp_TEST
(empno number
,ename char(15)
,job char(10)
,mgr number
,hiredate date
,sal number
,deptno number);
printf("Table emp_test created. \n");
EXEC SQL COMMIT WORK RELEASE;
exit(0);
}
/* 예제 #3 */
행을 삽입하기 위한 값의 입력지시
#include
/***************************************************************
This is is a sample Pro*C program which will insert records
into the EMP table by prompting the user for values to be entered.
***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
int empno;
VARCHAR ename[15];
VARCHAR job[10];
float sal;
int deptno;
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
void main(void)
{
int sret; /* return code from scanf */
/* log into ORACLE */
strcpy(uid.arr, "SCOTT"); /* copy the user name */
uid.len = strlen(uid.arr);
strcpy(pwd.arr, "TIGER"); /* copy the password */
pwd.len = strlen(pwd.arr);
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
printf("Connected to ORACLE user : %s\n\n\n", uid.arr);
while(1)
{
printf("Enter employee number(or 0 to end) : ");
sret = scanf("%d", &empno);
if( sret == EOF !! sret == 0 !! empno == 0 )
break; /* terminate loop */
printf("Enter employee name : ");
scanf("%s", ename.arr);
ename.len = strlen(ename.arr); /* set the name size */
printf("Enter employee's job : ");
scanf("%s", job.arr);
job.len = strlen(job.arr); /* set the job size */
printf("Enter employee salary : ");
scanf("%f", &sal);
printf("Enter employee deptno : ");
scanf("%d", &deptno);
EXEC SQL INSERT INTO EMP
(empno
,ename
,job
,sal
,deptno)
VALUES (:empno
,:ename
,:job
,:sal
,:deptno);
EXEC SQl COMMIT WORK;
printf("Employee %s added. \n\n", ename.arr);
}
EXEC SQL COMMIT WORK RELEASE; /* log off database */
exit(0);
}
/* 예제 #4 */
배열을 이용한 삽입
#include
/***************************************************************
This is is a sample Pro*C program which uses the FOR option
by inserting records into the EMP table.
***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
int empno[100];
VARCHAR ename[100][15];
VARCHAR job[100][10];
VARCHAR hiredate[100][9];
float sal[100];
int deptno[100];
int loop;
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
FILE *fp;
void main(void)
{
int i;
int fsret;
/* log into ORACLE */
strcpy(uid.arr, "SCOTT"); /* copy the user name */
uid.len = strlen(uid.arr);
strcpy(pwd.arr, "TIGER"); /* copy the password */
pwd.len = strlen(pwd.arr);
EXEC SQL WHENEVER SQLERROR GOTO errrpt;
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
printf("Connected to ORACLE user : %s\n\n\n", uid.arr);
if((fp = fopen("test.dat", "r")) == NULL)
{
printf("Error opening file test.dat \n");
exit(1);
}
while(1)
{
for(i = 0; i < 100 ; i++)
{
fsret = fscanf(fp, "%d %s %s %s %f %d",
&empno[i ], ename[i ].arr, job[i ].arr, hiredate[i ].arr,
&sal[i ], &deptno[i ]);
if(fsret == EOF)
break;
if(fsret == 0)
{
printf("Incompatible field on the line. \n");
exit(1);
}
ename[i ].len = strlen(ename[i ].arr);
job[i ].len = strlen(job[i ].arr);
hiredate[i ].len = strlen(hiredate[i ].arr);
}
loop = i;
EXEC SQL FOR :loop
INSERT INTO EMP(empno, ename, job, hiredate, sal, deptno)
VALUES(:empno, :ename, :job, :hiredate, :sal, :deptno);
EXEC SQL COMMIT WORK;
printf("%d rows inserted. \n", sqlca.sqlerrd[2]);
if(loop < 100)
break;
}
printf("File test.dat loaded. \n");
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL COMMIT work RELEASE;
exit(0);
errrpt:
printf("\n %70s \n", sqlca.sqlerrm.sqlerrmc);
EXEC SQL ROLLBACK WORK RELEASE;
exit(1);
}
/* 예제 #5 */
갱신에 사용하기 위한 값의 입력지시
#include
/***************************************************************
This is is a sample Pro*C program which will prompt the user
for an employee name and will display thr current sal and comm
fields for that employee.
***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
int empno[10];
float sal, comm;
short sali, commi;
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
void main(void)
{
int sret;
/* log into ORACLE */
strcpy(uid.arr, "SCOTT"); /* copy the user name */
uid.len = strlen(uid.arr);
strcpy(pwd.arr, "TIGER"); /* copy the password */
pwd.len = strlen(pwd.arr);
EXEC SQL WHENEVER SQLERROR STOP;
EXEC SQL WHENEVER NOT FOUND STOP;
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
printf("Connected to ORACLE user : %s\n", uid.arr);
printf("Enter employee name to update : ");
scanf("%s", ename.arr);
ename.len = strlen(ename.arr);
EXEC SQL SELECT SAL, COMM
INTO :sal, :comm
FROM EMP
WHERE ENAME = :ename;
printf("Employee : %s sal : %6.2f comm : %6.2f \n", ename.arr, sal,
comm);
printf("Enter new salary : ");
sret = scanf("%f", &sal);
sali = 0;
if(sret == EOF !! sret == 0) sali = 0;
printf("Enter new commision : ");
sret = scanf("%f", &comm);
commi = 0;
if(sret == EOF !! sret == 0) commi = -1;
EXEC SQL UPDATE EMP
SET SAL = :sal:sali,
COMM = :comm:commi
WHERE ENAME = :ename;
printf("Employee %s updateed. \n", ename.arr);
EXEC SQL COMMIT WORK RELEASE;
exit(0);
}
/* 예제 #6 */
배열을 이용한 갱신
#include
/***************************************************************
This is is a sample Pro*C program which updates using host
variable arrays. The arrays will be loaded with values
from operator input.
***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
int empno[100];
float sal[100];
int loop;
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
void main(void)
{
int i, sret;
/* log into ORACLE */
strcpy(uid.arr, "SCOTT"); /* copy the user name */
uid.len = strlen(uid.arr);
strcpy(pwd.arr, "TIGER"); /* copy the password */
pwd.len = strlen(pwd.arr);
EXEC SQL WHENEVER SQLERROR GOTO errrpt;
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
printf("Connected to ORACLE user : %s\n", uid.arr);
while(1)
{
for(i = 0; i < 100; i++)
{
printf("Enter employee number (or 0 to end loop) : ");
sret = scanf("%d", &empno[i ]);
if(sret == EOF !! sret == 0 !! empno[i ] == 0) break;
printf("Enter updated salary : ");
sret = scanf("%f", &sal[i ]);
if(sret == EOF !! sret == 0)
{
printf("Error in entry; terminating at this empno. \n");
break;
}
}
if(i == 0) break;
loop = i;
EXEC SQL FOR :loop
UPDATE EMP SET SAL = :sal
WHERE EMPNO = :empno;
EXEC SQL COMMIT WORK;
printf("%d rows updated. \n", sqlca.sqlerrd[2]);
}
printf("Update program complete. \n");
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL COMMIT WORK RELEASE;
exit(0);
errrpt:
printf("\n %70s \n", sqlca.sqlerrm.sqlerrmc);
EXEC SQL ROLLBACK WORK RELEASE;
exit(1);
}
/* 예제 #7 */
배열을 이용한 선택
#include
/***************************************************************
This is is a sample Pro*C program which selects using host
variable arrays.
***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
int empno[100];
VARCHAR ename[100][15];
float sal[100];
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
void main(void)
{
long num_ret;
/* log into ORACLE */
strcpy(uid.arr, "SCOTT"); /* copy the user name */
uid.len = strlen(uid.arr);
strcpy(pwd.arr, "TIGER"); /* copy the password */
pwd.len = strlen(pwd.arr);
EXEC SQL WHENEVER SQLERROR GOTO errrpt;
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
printf("Connected to ORACLE user : %s\n", uid.arr);
EXEC SQL DECLARE C1 CURSOR FOR
SELECT EMPNO, ENAME, SAL
FROM EMP;
EXEC SQL OPEN C1;
EXEC SQL WHENEVER NOT FOUND GOTO endloop;
num_ret = 0;
while(1)
{
EXEC SQL FETCH C1 INTO : empno, :ename, :sal;
print_rows(sqlca.sqlerrd[2] - num_ret);
num_ret = sqlca.sqlerrd[2];
}
endloop:
if(sqlca.sqlerrd[2] - num_ret > 0)
print_rows(sqlca.sqlerrd[2] - num_ret);
printf("\n\nProgram complete. \n");
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL COMMIT WORK RELEASE;
exit(0);
errrpt:
printf("\n %70s \n", sqlca.sqlerrrm.sqlerrmc);
EXEC SQL ROLLBACK WORK RELEASE;
exit(1);
}
int print_rows(long n)
{
long i;
printf("\n\nEmployee number\tEmployee Name\tSalary\n");
printf("\n\n---------------\t-------------\t------\n");
for(i = 1; i < n; i++)
printf("%15d\t%13s\t%6.2f\n", empno[i ], ename[i ].arr, sal - i);
return 0;
}
/* 예제 #8 */
기존의 테이블로부터 행의 삭제
#include
/***************************************************************
This is is a sample Pro*C program which will delete a row
from the emp table by prompting for an employee number.
***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
int empno;
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
void main(void)
{
/* log into ORACLE */
strcpy(uid.arr, "SCOTT"); /* copy the user name */
uid.len = strlen(uid.arr);
strcpy(pwd.arr, "TIGER"); /* copy the password */
pwd.len = strlen(pwd.arr);
EXEC SQL WHENEVER SQLERROR STOP;
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
printf("Connected to ORACLE user : %s\n", uid.arr);
scanf("%d", &empno);
EXEC SQL DELETE FROM EMP WHERE EMPNO = :empno;
EXEC SQL COMMIT WORK RELEASE;
printf("Employee number %d dropped. \n", empno);
exit(0);
}
3.1 쿼리의 구성
Pro*C를 사용해서 작성하는 쿼리에는 다음에 나타낸 구를 지정한 어떠한 SELECT 문도 사용할 수 있다.
SELECT
INTO
FROM
WHERE
CONNECT
UNION
INTERSECT
MINUS
GROUP BY
HAVING
ORDER BY
3.1.1 입력 호스트 변수
WHERE 구 내의 호스트 변수는 입력 호스트 변수라고 부른다.
3.1.2 출력 호스트 변수
INTO 구 내의 호스트 변수는 출력 호스트 변수라고 부른다.
3.2 1개의 행 만을 리턴하는 쿼리
쿼리가 오직 1개의 행 만을 리턴하는 것을 알고 있는 경우는, SELECT 리스트 내의 항목과 같은 수의 출력 호스트 변수를 지정한 INTO 구를 사용한다.
3.3 복수의 행을 리턴하는 쿼리(커서의 사용법)
쿼리가 복수의 행을 리턴하는 경우, 혹은 몇 개의 행이 리턴됐는지 모를 경우는, SELECT 문과 함께 커서를 사용해야 한다.
커서는 ORACLE 및 Pro*C가 사용하는 작업 영역이고, 이 속에 쿼리의 결과가 포함된다. 커서는 1개의 SELECT문에 대응하고, 쿼리가 변화할 때마다 반복해서 실행된다. 커서는 선언되어야 하며, 데이터의 처리를 위해서 커서를 사용할 때는 아래의 4개의 커서 커맨드를 사용한다.
DECLARE CURSOR
OPEN CURSOR
FETCH
CLOSE CURSOR
커서를 “OPEN” 한 후 그 커서를 사용해서, 그것에 대응한 쿼리의 결과로서 얻어진 여러 행을 검색 할 수 있다. 쿼리 기준을 만족한 행은 모두 집합의 형식을 취하고, 이것을 커서의 실효집합이라고 부른다. 쿼리가 종료하면 커서를 “CLOSE” 한다.
3.3.1 DECLARE CURSOR 문
DECLARE CURSOR 문에서는 커서를 정의한다.
EXEC SQL DECLARE cursor_name CURSOR FOR
SELECT … FROM …
이 구문은 실제로 다음과 같이 사용한다.
EXEC SQL DECLARE C1 CURSOR FOR
SELECT ename, empno, job, sal
FROM emp
WHERE deptno = :deptno;
커서를 참조한는 SQL 문을 사용하기 전에 반드시 이커서에 대응하는 DECLARE CURSOR 문을 실행해야 하며, Pro*C는 선언되지 않은 커서에 대한 참조를 해석할 수 없다.
프로그램 내에는 복수의 커서를 사용할 수 있으며 동일 프로그램 내에서 같은 이름의 커서를 지정해서는 안된다.
3.3.2 OPEN CURSOR
커서를 OPEN 함으로써 쿼리가 판정되고, 행의 실효집합이 식별된다.
EXEC SQL OPEN cursor_name;
커서는 OPEN 상태에서 실효집합 최초의 행 직전에 위치된다. 그러나, 실제로 이 시점에서는 아직 어느 행의 검색도 행하지 않는다.
커서를 일단 OPEN 하면 다시 OPEN 하지 않는한, 이 커서의 입력 호스트 변수는 새로이 체크되지 않는다.
3.3.3 실효집합의 행의 검색(FETCH 문)
FETCH 문에서는 실효집합의 행을 읽어 들이고, 결과를 얻을 출력 호스트 변수의 이름을 지정한다.
EXEC SQL FETCH cursor_name INTO :hostvar1, :hostvat2 …;
이 구문은 실제로 다음과 같이 사용된다.
EXEC SQL FETCH C1 INTO :pename, :pempno, :pjob, :psal;
처음으로 커서를 실행하면, 커서는 실효집합의 이전 위치에서 실효집합의 첫째 행으로 이동하며 이 행이 현재의 행이 된다. 커서는 실효집합의 다음행으로만 진행하며 앞에 검색한 행으로 되돌아 가기 위해서는 커서를 CLOSE 하고 다시 오픈해야 한다.
3.3.4 CLOSE CURSOR 문
실효집합 행의 검색을 종료한 후 커서를 CLOSE 함으로써, 커서의 OPEN 상태를 유지하기 위해서 사용된 자원을 해제한다.
EXEC SQL CLOSE cursor_name;
CLOSE 한 커서에 대해서는 검색을 행할 수 없다.
3.4 예제 프로그램
/* 예제 #9 */
WHERE 구에 의한 쿼리
#include
/***************************************************************
This is is a sample Pro*C program which will display all the
salesman in the employee table.
***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
float sal, comm;
char ename[11];
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
void main(void)
{
/* log into ORACLE */
strcpy(uid.arr, "SCOTT"); /* copy the user name */
uid.len = strlen(uid.arr);
strcpy(pwd.arr, "TIGER"); /* copy the password */
pwd.len = strlen(pwd.arr);
EXEC SQL WHENEVER SQLERROR STOP;
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
printf("Connected to ORACLE user : %s\n", uid.arr);
EXEC SQL DECLARE C1 CURSOR FOR
SELECT ENAME, SAL, COMM
FROM EMP
WHERE JOB = 'SALESMAN';
EXEC OPEN C1;
EXEC SQL WHENEVER NOT FOUND STOP;
printf("SALESMAN NAME\t\tSALARY\t\tCOMMISSION\n\n");
for( ; ; )
{
EXEC SQL FETCH C1 INTO :ename, :sal, :comm;
printf("%-10s\t\t%6.2f\t\t%6.2f \n", ename, sal, comm);
}
EXEC SQL CLOSE C1;
EXEC SQL WHENEVER SQLERROR CONTINUE; /* don't trap errors */
EXEC SQL COMMIT WORK RELEASE;
exit(0);
}
————————————————————————————
ORACLE의 기능에 의하여, 유저의 작업 모두가 실행하면 바로 COMMIT되는 것이 아니다. 다시말해서 ORACLE에서는 COMMIT 을 행하기 전에 모든 트랜잭션이 완료되어 있는지를 유저 자신이 확인하도록 되어 있다.
ORACLE은 BEFORE 이미지 파일을 사용하여, 데이터베이스의 일관성을 보호하고 있다. BEFORE 이미지 파일에는 트랜잭션이 시작하기 전의 상태로 데이터베이스의 블록이 보존된다. 상황에 따라 이들의 블록이 데이터베이스 파일에 다시 기록되어, 트랜잭션에 의해 변경된 부분이 변경 전의 상태로 되돌려 진다. 이 같은 처리는 다음과 같은 경우 발생한다.
유저에 의한 ROLLBACK WORK 유저 프로세스 내의 ORACLE로부터의 이상 종료 프로세스간의 데드록 시스템 장애(H/W OR S/W)
4.1 COMMIT WORK
COMMIT WORK 문은 현재 진행 중인 논리적인 작업단위를 종료하게 하고, 이 작업단위 내에서 행해진 변경을 모두 확정한다.
EXEC SQL COMMIT WORK [RELEASE];
RELEASE 옵션 파라미터는 프로그램이 소유하고 있는 자원을 모두 리턴하고, 데이터베이스에서 로그로프한다.
4.2 ROLLBACK WORK
ROLLBACK WORK 문은 현재 진행 중인 논리적인 작업단위를 종료하게 하고, 이 작업단위에서 행한 변경을 취소한다.
EXEC SQL ROLLBACK WORK [RELEASE];
유저는 RELEASE 옵션을 사용해서 최후의 작업단위를 반드시 명시적으로 COMMIT 또는 ROLLBACK해야 한다.
5.1 표지 변수에 리턴된 값의 사용
어느 호스트 변수에도 임의 선택 변수인 표지 변수를 대응시킬 수 있다. 이 표지 변수를 사용하면 각각의 필드 값이 어떤 경우인지 알 수 있다.
값 의미
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
0 리턴되는 값은 호스트 변수에 보존된다. 이것은 널도 아니고,
절사도 되지 않는다.
-1 리턴된 값은 널이다. 호스트 변수의 값은 정의되지 않는다.
20 리턴된 값은 절사되어 있다. 호스트 변수의 폭이 충분하지 않다.
표지 변수에 설정된 값은 절사되기 전의 폭이다
5.2 SQLCA의 구조
SQLCA 는 프로그램의 실행에 관한 정보를 교환하기 위해, 모든 Pro*C 프로그램에서 사용한다. SQLCA는 각각의 트랜잭션에 대해서 널 값의 무시여부, 쿼리를 시작하고 나서 데이터의 변경 여부등을 표시하므로, 프로그래머는 각각의 데이터 상태를 확인할 수 있다.
5.2.1 SQLCA를 참조하는 타이밍
SQLCA는 각 SQL 실행문의 실행 때마다 갱신된다. 따라서 프로그래머는 각 실행문 뒤에서 SQLCA를 검색해야 한다. 특히 각 DML 문 뒤에서는 SQLCA를 검색할 필요가 있다. 이는 테이블 속의 일부의 행만을 처리한 뒤에 INSERT 및 UPDATE 문이 실패한다면, 유저는 데이터베이스을 어떤 일관성 있는 상태로 회복하기 위해 ROLLBACK WORK 커맨드를 실행해야 하기 때문이다.
WHENEVER 문을 사용하면 이상 상태를 검출하고 그 상태에 따라 적절히 동작을 지정할 수 있다. 다음은 WHENEVER 문의 디폴트 값이다.
EXEC SQL WHENEVER anyerror CONTINUE;
5.2.2 SQLCA의 각 요소의 의미
struct sqlca {
char sqlcaid[8];
long sqlcabc;
long sqlcode;
struct {
unsigned short sqlerrml;
char sqlerrmc[70];
} sqlerrm;
char sqlerrp[8];
long sqlerrd[6];
char sqlwarn[8];
char sqlext[8];
};
struct sqlca sqlca;
*sqlca.sqlcode 4바이트 2진 정수이고, SQL 문의 실행결과를 나타낸다.
0 실행이 정상 종료
1403 NOT FOUND
음수 프로그램 또는 시스템 장애
*sqlca.sqlerrm.sqlerrml sqlca.sqlerrm.sqlerrmc의 텍스트의 길이
*sqlca.sqlerrm.sqlerrmc 가변 길이의 문자열이고, sqlca.sqlcode 내에
표시된 에러번호에 대응하는 에러메세지
*sqlca.sqlerrd 4바이트 2진 정수 배열 ORACLE RDBMS의 내부상황을
파악하기 위해 사용. sqlca.sqlerrd[2]는 INSERT나 UPDATE
처럼 DML 처리에 대해서 몇 개의 행이 처리 됐는지를 나타냄
*sqlca.sqlwarn 프리컴파일 중에 발생한 여러가지 상황에 대한 경고
sqlca.sqlwarn[0] "W"가 설정된 경우 1개 이상의 경고가 설정되어 있음
5.3 WHENEVER 문
에러를 검출할 때 어떤 처리를 취해야 할 지를 결정한다.
EXEC SQL WHENEVER [SQLERROR | SQLWARNING | NOT FOUND]
[STOP | CONTINUE | GOTO stmt-label];
SQLERROR sqlca.sqlcode가 -1인 경우에 설정
SQLWARNING sqlca.sqlwarn[0]에 "W"가 설정되어 있는 경우에 설정
NOT FOUND sqlca.sqlcode가 1403인 경우에 설정
STOP 프로그램을 종료시키고 논리적인 작업단위는 ROLLBACK 된다.
CONTINUE sqlca의 상태를 무시하고 프로그램을 계속 진행한다.
GOTO 지정한 라벨이 붙은 문으로 제어를 옮긴다.
6. 동적 정의문
6.1 동적 정의문의 정의
동적 정의문이란, 컴파일시에 정의되지 않는 SQL 문이다. 다시 말해서, 동적 정의문은 각각의 실행 때마다 변경이 가능하고, 실제로 많은 경우에 변경된다.
6.2 동적 정의문의 종류
방법 1 : EXECUTE IMMEDIATE 문의 사용 모든 SQL 문(SELECT 문 제외)을 프리컴파일해서 이것을 실행한다. SQL 문은 상수 또는 호스트 변수 중 어느 것이라도 상관없다. SQL 문에는 호스트 변수를 포함하지 않는다. 방법 2 : PREPARE 문 및 EXECUTE 문의 사용 모든 SQL 문(SELECT 문 제외)을 받아들여 이것을 수행한다. SQL 문 중에 호스트 변수를 포함할 수 있다. 방법 3 : PREPARE 문 및 FETCH 문의 사용 선택을 행할 수 있다. SQL 문 중에 호스트 변수를 포함할 수 있다. 이 방법은 PREPARE, DECLARE, OPEN, FETCH의 순서로 행한다. 방법 4 : 바인드 및 정의 기술자의 사용 1행의 SELECT 및 여러 행의 SELECT를 포함하는 모든 SQL 문을 사용할 수 있다.
6.3 EXECUTE IMMEDIATE 의 사용
/* 예제 #10 */
#include
/***************************************************************
This is is a sample Pro*C program which will prompt for a
WHERE clause to be used in an update statement. This is to be
used with EXECUTE IMMEDIATE.
***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
char select[132];
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
void main(void)
{
char where[80];
int scode;
/* log into ORACLE */
strcpy(uid.arr, "SCOTT"); /* copy the user name */
uid.len = strlen(uid.arr);
strcpy(pwd.arr, "TIGER"); /* copy the password */
pwd.len = strlen(pwd.arr);
EXEC SQL WHENEVER SQLERROR STOP;
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
printf("Connected to ORACLE user : %s\n", uid.arr);
strcpy(select, "UPDATE EMP SET COMM = 100 WHERE");
printf("Please enter where clause for the following : \n");
printf("%s", select);
scode = scanf("%s", where);
if(scode == EOF !! scode == 0)
{
printf("Invalid entry. \n");
exit(1);
}
strcat(select, where);
EXEC SQL EXECUTE IMMEDIATE :select;
printf("%d records updated. \n", sqlca.sqlerrd[2]);
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL COMMIT WORK RELEASE;
exit(0);
}
6.4 PREPARE 및 EXECUTE 의 사용
/* 예제 #11 */
#include
/***************************************************************
This is is a sample Pro*C program which will prompt for a
WHERE clause to be used in an update statement. This is to be
used with PREPARE and EXECUTE.
***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
float comm;
char select[132];
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
void main(void)
{
char where[80];
int scode;
/* log into ORACLE */
strcpy(uid.arr, "SCOTT"); /* copy the user name */
uid.len = strlen(uid.arr);
strcpy(pwd.arr, "TIGER"); /* copy the password */
pwd.len = strlen(pwd.arr);
EXEC SQL WHENEVER SQLERROR GOTO errrpt;
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
printf("Connected to ORACLE user : %s\n", uid.arr);
strcpy(select, "UPDATE EMP SET COMM = :comm WHERE");
printf("Please enter where clause for the follwing : \n");
printf("%s", select);
scode = scanf("%s", where);
if(scode == EOF !! scode == 0)
{
printf("Invalid entry. \n");
exit(1);
}
strcat(select, where);
EXEC SQL PREPARE S1 FROM :select;
printf("Please enter commission : ");
scanf("%f", &comm);
EXEC SQL EXECUTE S1 USING :comm;
printf("%d records updated. \n", sqlca.sqlerrd[2]);
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL COMMIT WORK RELEASE;
exit(0);
errrpt:
printf("\n %70s \n", sqlca.sqlerrm.sqlerrmc);
EXEC SQL ROLLBACK WORK RELEASE;
exit(1);
}
6.5 PREPARE, DECLARE, OPEN, FETCH, CLOSE 의 사용
/* 예제 #12 */
#include
/***************************************************************
This is is a sample Pro*C program which will prompt for a
WHERE clause to be used in a select statement.
This sample uses PREPARE, DECLARE, OPEN, FETCH, CLOSE
since this may be a multi-row select and world require a cursor.
***************************************************************/
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
int deptno;
float sal;
char select[132];
EXEC SQL END DECLARE SECTION;
EXEC SQL INCLUDE SQLCA;
void main(void)
{
char where[80];
int i, scode;
/* log into ORACLE */
strcpy(uid.arr, "SCOTT"); /* copy the user name */
uid.len = strlen(uid.arr);
strcpy(pwd.arr, "TIGER"); /* copy the password */
pwd.len = strlen(pwd.arr);
EXEC SQL WHENEVER SQLERROR GOTO errrpt;
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
printf("Connected to ORACLE user : %s\n", uid.arr);
strcpy(select, "SELECT ENAME, SAL FROM EMP ");
printf("Please enter where clause for the following : \n");
printf("%s", select);
scode = scanf("%s", where);
if(scode == EOF !! scode == 0)
{
printf("Invalid entry. \n");
exit(1);
}
strcat(select, where);
EXEC SQL PREPARE S1 FROM :select;
EXEC SQL DECLARE C1 CURSOR FOR S1;
EXEC SQL OPEN C1;
printf("Employee \tSalary \n");
printf("--------------\t-----------\n");
EXEC SQL WHENEVER NOT FOUND GOTO endloop;
for(i = 0; ; i++)
{
EXEC SQL FETCH C1 INTO :ename, :sal;
printf("%10s\t%6.2f\n", ename, sal);
}
endloop:
printf("\n\n%d records selected.\n", i);
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL COMMIT WORK RELEASE;
exit(0);
errrpt:
printf("\n %70s \n", sqlca.sqlerrm.sqlerrmc);
EXEC SQL ROLLBACK WORK RELEASE;
exit(1);
}
7.1 STORED PROCEDURE 의 사용
/* calldemo.sql */
rem
Rem calldemo.sql -
Rem DESCRIPTION
Rem
Rem RETURNS
Rem
CREATE OR REPLACE PACKAGE calldemo AS
TYPE name_array IS TABLE OF emp.ename%type
INDEX BY BINARY_INTEGER;
TYPE job_array IS TABLE OF emp.job%type
INDEX BY BINARY_INTEGER;
TYPE sal_array IS TABLE OF emp.sal%type
INDEX BY BINARY_INTEGER;
PROCEDURE get_employees(
dept_number IN number, -- department to query
batch_size IN INTEGER, -- rows at a time
found IN OUT INTEGER, -- rows actually returned
done_fetch OUT INTEGER, -- all done flag
emp_name OUT name_array,
job OUT job_array,
sal OUT sal_array);
END calldemo;
/
CREATE OR REPLACE PACKAGE BODY calldemo AS
CURSOR get_emp (dept_number IN number) IS
SELECT ename, job, sal FROM emp
WHERE deptno = dept_number;
PROCEDURE get_employees(
dept_number IN number,
batch_size IN INTEGER,
found IN OUT INTEGER,
done_fetch OUT INTEGER,
emp_name OUT name_array,
job OUT job_array,
sal OUT sal_array) IS
BEGIN
IF NOT get_emp%ISOPEN THEN -- open the cursor if
OPEN get_emp(dept_number); -- not already open
END IF;
done_fetch := 0; -- set the done flag FALSE
found := 0;
FOR i IN 1..batch_size LOOP
FETCH get_emp INTO emp_name(i), job(i), sal(i);
IF get_emp%NOTFOUND THEN -- if no row was found
CLOSE get_emp;
done_fetch := 1; -- indicate all done
EXIT;
ELSE
found := found + 1; -- count row
END IF;
END LOOP;
END;
END;
/
/* 예제 #13 */
#include
#include
/***************************************************************
This program connects to ORACLE using the SCOTT/TIGER account.
The program declares several host arrays, then calls a PL/SQL
stored procedure (GET_EMPLOYEES in the CALLDEMO package)
that fills the table OUT parameters. The PL/SQL procedure returns
up to ASIZE values.
****************************************************************/
EXEC SQL INCLUDE sqlca.h;
typedef char asciz[20];
typedef char vc2_arr[11];
EXEC SQL BEGIN DECLARE SECTION;
/* User-defined type for null-terminated strings */
EXEC SQL TYPE asciz IS STRING(20) REFERENCE;
/* User-defined type for a VARCHAR array element. */
EXEC SQL TYPE vc2_arr IS VARCHAR2(11) REFERENCE;
asciz username;
asciz password;
int dept_no; /* which department to query? */
vc2_arr emp_name[10]; /* array of returned names */
vc2_arr job[10];
float salary[10];
int done_flag;
int array_size;
int num_ret; /* number of rows returned */
EXEC SQL END DECLARE SECTION;
long SQLCODE;
void print_rows(); /* produces program output */
void sql_error(); /* handles unrecoverable errors */
main()
{
int i;
char temp_buf[32];
/* Connect to ORACLE. */
EXEC SQL WHENEVER SQLERROR DO sql_error();
strcpy(username, "scott");
strcpy(password, "tiger");
EXEC SQL CONNECT :username IDENTIFIED BY :password;
printf("\nConnected to ORACLE as user: %s\n\n", username);
printf("Enter department number: ");
gets(temp_buf);
dept_no = atoi(temp_buf);
/* Print column headers. */
printf("\n\n");
printf("%-10.10s%-10.10s%s\n", "Employee", "Job", "Salary");
printf("%-10.10s%-10.10s%s\n", "--------", "---", "------");
/* Set the array size. */
array_size = 10;
done_flag = 0;
num_ret = 0;
/* Array fetch loop.
* The loop continues until the OUT parameter done_flag is set.
* Pass in the department number, and the array size--
* get names, jobs, and salaries back. */
for ( ; ; )
{
EXEC SQL EXECUTE
BEGIN calldemo.get_employees
(:dept_no, :array_size, :num_ret, :done_flag,
:emp_name, :job, :salary);
END;
END-EXEC;
print_rows(num_ret);
if(done_flag) break;
}
/* Disconnect from the database. */
EXEC SQL COMMIT WORK RELEASE;
exit(0);
}
void print_rows(int n)
{
int i;
if (n == 0)
{
printf("No rows retrieved.\n");
return;
}
for (i = 0; i < n; i++)
printf("%10.10s%10.10s%6.2f\n", emp_name[i ], job[i ], salary[i ]);
}
/* Handle errors. Exit on any error. */
void sql_error()
{
char msg[512];
int buf_len, msg_len;
EXEC SQL WHENEVER SQLERROR CONTINUE;
buf_len = sizeof(msg);
sqlglm(msg, &buf_len, &msg_len);
printf("\nORACLE error detected:");
printf("\n%.*s \n", msg_len, msg);
EXEC SQL ROLLBACK WORK RELEASE;
exit(1);
}
8. Pro*C/C++의 사용
8.1 디렉토리 또는 경로의 설정
OS에서 디렉토리 또는 경로를 사용하고 있는 경우 경로 또는 디렉토리의 이름이 장치의 지정과 함께 올바른 지를 확인해야 한다.
8.2 커맨드 구문
일반적인 커맨드 구문은 다음과 같다.
PCC INAME = filename {option=value (option=value …)}
8.2.1 필수 인수
필수 인수는 “INAME = 파일명” 하나뿐이다. 파일의 확장자나 파일타입을 지정하지 않는 경우 “HOST = 언어”를 인수로서 지정해야 한다.
Pro*C에서 입력파일 및 출력파일에 대한 파일타입 및 확장자의 디폴트값은 다음과 같다.
OS 입력파일타입 또는 확장자 출력파일타입 또는 확장자 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ VAX/VMS .pc .c IBM/VM/CMS csql c UNIX .pc .c
8.2.2. Pro*C의 실행시 옵션
실행시에는 복수의 옵션을 사용할 수 있다. OPTION = value · AREASIZE · ASACC · ERRORS · HOLD_CURSOR/RELEASE_CURSOR · HOST · INCLUDE · IRECLEN · LNAME · LRECLEN · LTYPE · MAXLITERAL · MAXOPENCURSOR · ONAME · ORACA · ORECLEN · PAGELEN · REBIND · SELECT_ERROR · USERID · XREF
Pro*C의 데이터 형
C 프로그램에서 사용하는 일반적인 데이터 형과 ProC에서만 사용할 수 있는 고유한 형태의 데이터 형으로 구성된다. Pro*C 역시 C 프로그램이기 때문에 C의 일반적인 데이터 형을 사용할 수 있다. 다음의 내용은 roC 프로그램에서 사용하는 데이터 형에 대한 설명이다.
기본적인 데이터 형의 일차원 배열 CHAR 데이터 형과 VARCHAR 데이터 형의 이차원 배열 출력 호스트 변수로 VARCHAR 변수를 사용할 때 오라클은 구조체의 멤버 길이를 설정하지만 배열을 NULL-terminate(\0)시키지는 않습니다. 그러므로 출력하기 전에 출력 호스트 변수를 NULL-terminate 시키십시오. CHAR은 자동 NULL-terminate입니다. 기본적인 데이터 형에 대한 포인터 사용자 정의의 typedef 구조체 배열의 구조체 구조체에 대한 포인터 구조체 배열
| C의 데이터 형 | 설명 |
| char | 단일 문자 |
| char[n] | n 바이트의 문자 배열 |
| int | 정수 |
| short short int | 작은 정수 (지시자 변수에 대한 데이터 형) |
| long long int | 긴 정수 |
| floatlong float | 부동 소수점, 단정도 |
| double | 부동 소수점, 배정도 |
| VARCHAR | 가변 길이 문자 |
오라클 데이터베이스의 데이터 형과 C 프로그램의 데이터 형은 호환된다.
| 오라클 DB의 데이터 형 | C의 데이터 형 | 설명 |
| VARCHAR2(Y) (Y: 1~2000) | char | 단일 문자 |
| CHAR(X)(X:1~255) | char[n] VARCHAR[n] int short float | n 바이트의 문자 배열 n 바이트의 가변 문자 배열 정수 작은 정수 부동 소수점 |
| NUMBER NUMBER(P, S) | int short long float double char char[n] VARCHAR[n] | 정수 작은 정수 긴 정수 부동 소수점 배정도 부동 소수점 단일 문자 n 바이트의 문자 배열 n 바이트의 가변 문자 배열 |
| DATE | char[n] VARCHAR[n] | n 바이트의 문자 배열 n 바이트의 가변 문자 배열 |
| LONG | char[n] VARCHAR[n] | n 바이트의 문자 배열 n 바이트의 가변 문자 배열 |
| RAW(X) | unsigned char[n] VARCHAR[n] | n 바이트의 문자 배열 n 바이트의 가변 문자 배열 |
| LONG LAW | unsigned char[n] VARCHAR[n] | n 바이트의 문자 배열 n 바이트의 가변 문자 배열 |
| ROWID | unsigned char[n] VARCHAR[n] | n 바이트의 문자 배열 n 바이트의 가변 문자 배열 |
| MLSLABEL | unsigned char[n] VARCHAR[n] | n 바이트의 문자 배열 n 바이트의 가변 문자 배열 |
| 주의: X : 1~255 사이의 값, 디폴트는 1 Y : 1~2000 사이의 값 P : 2~38, S: -84~127 사이의 값 | ||
오라클의 char을 C 프로그램의 char로 치환하고, number을 in, long, short로 치환해서 사용할 수 있다.
VARCHAR 형의 경우에는 데이터 형의 특성상 C 프로그램의 char 데이터 형과는 다른 특이한 형태를 가지고 있다. Pro*C 프로그램에서 VARCHAR uid[20];로 선언하면 실제로는 아래와 같은 형태로 생성된다.
struct {
unsigned short int len;
unsigned char arr[20];
} uid;
이와 같이 ProC의 VARCHAR 형도 오라클 데이터베이스의 VARCHAR2와 동일하게 가변 길이로 할당이 되어 사용된다. 그러나 ProC만의 특징이 있는데, Pro*C에서 VARCHAR로 선언하는 것은, 내부적으로는 가변적 데이터 할당이 가능한 문자형 구조체로 선언하는 것과 같다. 구조체로 선언하지 않더라도 구조체의 특성을 가지므로 변수에 값을 할당하는 방법도 일반 char 변수와 다르게 이루진다. 또한 명시적으로 포인터로 선언하지 않더라도 VARCHAR 형은 데이터를 포인터로만 전달할 수 있기 때문에 데이터 할당과 출력에 있어 일반 데이터 형과 같은 형태가 아닌 포인터의 처리 프로세스를 따른다.
// char 형으로 선언하고 할당한 예제
char uid[20];
strcpy(uid, "userid");// VARCHAR형의 경우에는 다음과 같이 선언하고 할당
VARCHAR uid[20];
strcpy((char*)uid.arr, "userid");
uid.len = (short)strlen((char *)uid.arr);
VARCHAR 형은 선언과 동시에 len과 arr이라는 멤버를 갖는 구조체로 선언된다.구조체 변수에 대한 데이터 할당을 위해서는 구조체를 이루고 있는 각 멤버에 데이터를 할당해야 합니다. 물론 경우에 따라서는 구조체에 대한 할당만으로도 각 멤버에 대한 데이터 할당이 가능하기도 합니다. 이는 내부적으로 볼 때 자동적으로 각 멤버에 대한 할당이 이루어지는 것입니다. 대표적으로 Pro*C에서 데이터 추출 시 사용하는 FETCH 구문이 이에 해당됩니다.
VARCHAR 형도 구조체입니다. 그렇기 때문에 데이터를 할당하기 위해서는 구조체를 이루고 있는 각 멤버에 데이터를 할당해야만 합니다. 뿐만 아니라 데이터 전달이 포인터로만 가능하기 때문에 데이터 형에 대한 포인터로의 형 변환(Type Cast)도 필요합니다.
저장 공간에 있어서도 차이가 있습니다. char 형은 Fixed Data Type으로 데이터 형의 길이만큼 저장 공간을 차지하고, VARCHAR 형은 데이터의 길이와 상관없이 할당받은 데이터 길이만큼의 저장 공간을 갖습니다. 사용의 편이성만 놓고 보자면 구조체로의 형변환도 안되고, 포인터로의 형번화도 필요없는 char형이 더 좋아보이지만 저장 공간, 즉 메모리 공간의 효율적 사용이라는 측면에서 본다면 VARCHAR 형은 char 형과 견주어 절대 뒤지지 않는 훌륭한 데이터형입니다.
Pro*C 프로그램에서 저장 공간과 처리 방법에 있어서 차이를 보이는 데이터 형은 char 형과 VARCHAR 형 두 개 밖에 없습니다. 다른 데이터 형은 C 프로그램에서 사용되는 일반 데이터 형과 동일합니다. 그러므로 두 데이터 형을 사용할 때는 주의하기 바랍니다.
Pro*C 오류 진단과 처리
Pro*C에서 오류를 검출하고 이를 처리함에 있어 SQLCA나 ORACA를 사용한다.
Pro*C에서는 SQL 통신 영역(SQLCA)와 오라클 통신 영역(ORACA)이라는 두 개의 특수한 데이터 구조를 지원합니다. 이는 프로그램 안에서 사용하는 SQL 문장에 대한 경고나 오류의 상태를 기술하는 구조체로서, 개발에 사용되는 컴퓨터의 오라클 홈 디렉터리 밑의 precomp 및의 public 밑에 설치되며 해당 파일을 직접 열어 확인할 수 있습니다.
$ORACLE_HOME/precomp/publicSQLCA는 Pro*C 프로그램에 있어 필수 요소이고, ORACA는 더 많은 정보를 얻기 위한 선택 요소로 사용됩니다. Pro*C에서는 SQLCA를 사용하여 모든 SQL 문장의 상태를 감지한 후에 상태 코드와 같은 정보를 제공합니다. SQLCA보다 더 많은 확장된 정보를 얻고자 할 때, 가령 응용 프로그램이 커서 캐시와 같은 오라클 자원의 사용을 모니터링 하기 위해, 또는 오류가 발생한 시점에 수행된 SQL 문의 정보를 확인하기 위해 ORACA를 사용할 수 있습니다.
| Oracle Text File | 요구사항 | 내용 |
| sqlca | 필수 | SQLCA를 위한 선언 |
| oraca | 선택 | 오라클 통신 영역을 위한 선언 |
Pro*C에서의 오류 처리는 다른 프로그램이나 오라클의 PL/SQL과 동일하게 이루어집니다. 각각의 내장 SQL 문장 뒤에 호스트 언어 문장을 사용하여 오류를 명시적으로 처리하거나, ‘WHENEVER’ 문장을 사용하여 발생 가능한 모든 오류에 대해 동일한 처리 방식이 수행되도록 처리할 수 있습니다.
SQLCA
모든 Pro*C 프로그램에서 프로그램 실행에 고나한 정보를 데이터베이스와 교환하기 위해서 SQLCA(SQL 통신 영역)를 필수로 사용합니다. SQLCA를 사용함에 있어서 별도의 필요 조건이나 방법은 필요치 않으며, C 프로그램에서 헤더 파일을 사용할 때와 같이 프로그램의 시작 부분에 헤더 파일을 첨부해서 사용할 수 있습니다.
SQLCA는 예외와 경고를 감지합니다. SQL 문 속에 변수의 수가 너무 적어서 요구된 데이터를 반환할 수 없는 경우나, 데이터 추출 시 추출하려는 데이터가 없는 경우(ORA-1403) 등 다양한 경우의 에러와 경고에 대해 SQLCA는 SQL 문장의 실행 시점에서 이를 감지하고 출력합니다.
내장 SQL 프로그램 방식을 선택하였다면, SQLCA는 Include 파일 선언 부를 통해 프로그램 내에서 필수로 선언해서 사용해야 하는 참조 파일입니다. SQLCA는 오라클 홈 디렉터리 밑의 precomp/public에 ‘sqlca.h’ 파일로 존재합니다. sqlca.h 파일은 SQLCA를 기술한 파일로서 Pro*C 프로그램에서 SQLCA를 사용하기 위해서는 일반 Include 파일의 선언과 동일한 방법으로 선언해서 사용할 수 있으며, 헤더 파일 설정 구문은 다음과 같습니다.
#include <sqlca.h>
위와 같이 C 프로그램의 고유한 방식으로 선언하여 사용할 수 있으며, Pro*C의 고유한 문법인 ‘EXEC SQL INCLUDE SQLCA;’를 통해 선언하여 사용할 수도 있습니다. EXEC SQL INCLUDE 문법을 사용할 경우에는 해당 파일의 확장자를 별도로 지정할 필요가 없습니다. 아래와 같이 헤더 파일을 설정하면 됩니다.
EXEC SQL INCLUDE SQLCA;
SQLCA는 직전의 SQL 문장의 처리 결과에 대해 SQLCA 파일에 정의되어 있는 sqlca 구조체에 정보를 저장합니다. 그러므로 개발자는 각 SQL 문장마다 SQLCA 구조체 내용을 검색하여 에러와 경고 여부에 대한 정보를 확인할 수 있습니다.
SQLCA는 다음과 같은 정보를 가지고 있습니다.
- 경고 플래그 처리 상황에 관한 정보
- 에러 코드
- 진단 정보
SQLCA 구조체의 개괄적인 구조는 아래와 같습니다.
struct {
char sqlcaid[8];
long sqlcabc;
long sqlcode;
struct {
unsigned short sqlerrml;
char sqlerrmc[70];
} sqlerrm;
char sqlerrp[8];
long sqlerrd[6];
char sqlwarn[8];
char sqlext[8];
} sqlca;
SQLCA 구조체의 각 멤버를 하나씩 살펴보겠습니다.
체의 각 멤버를 하나씩 살펴보겠습니다.
| 번호/멤버 | 설명 |
| sqlca.sqlcaid | 문자열로, 글로벌 구조로 사용하는 경우에 한해서, 할당 시에 “SQLCA”로 초기화됩니다. 이는 C가 아니라 주로 FORTRAN에 관련된 것입니다. |
| sqlca.sqlcabc | 4바이트 2진 정수로 SQLCA 구조 자신의 길이가 바이트로 설정됩니다. 이는 C가 아니라 주로 FORTRAN에 관련된 것입니다. |
| sqlca.sqlcode | 가장 최근의 문장에서 에러 또는 시스템 장애가 발생한 경우에 오라클서버는 음수 에러 코드를, 가장 최근의 문장이 아무런 행을 반환하지 않는 SELECT나 FETCH 등의 경고인 경우는 +1403(MODE = ANSI인 경우는 +100)를 가지며, 나머지의 경우는 0으로 실행이 정상으로 종료한 것을 나타냅니다. 양수는 실행 시 에러 발생을 의미합니다. |
| sqlca.sqlerrm.sqlerrml | 가장 최근에 발생한 오라클 서버 에러 메시지(sqlca.sqlerrm.sqlerrmc)의 길이를 나타내는 필드입니다. |
| sqlca.sqlerrm.sqlerrmc | 가변 길이의 문자열로, sqlca.sqlcode 안에 표시된 에러 번호에 대응하는 에러 메시지의 내용입니다. 가장 최근의 오라클 서버 에러 메시지 내용이 들어가는 필드입니다. |
| sqlca.sqlerrp | 현재는 사용하지 않습니다. |
| sqlca.sqlerrd | 4바이트 2진 정수 6개로 된 배열이고, 오라클 RDBMS의 내부 상황을 파악하기 위해 사용합니다. |
| sqlca.sqlerrd[4] | 구문 분석 오류 오프셋을 가지는 필드입니다. SQL 문 실행 때 참조된 형재 행 위치를 리턴합니다. |
| sqlca.sqlerrd[2] | INSERT, UPDATE, DELETE의 DML 처리에 대해서 몇 개의 행이 처리되었는지, SELECT 시 몇 개의 행이 추출되었는지를 나타냅니다. 해당 문장이 처리한 행의 개수가 들어갑니다. |
| sqlca.sqlwarn | 1문자의 요소 8개로 구성된 구조입니다. 이들의 요소는 프리 컴파일 중에 발생한 여러 가지 상화에 대한 경고를 나타냅니다. 예를 들면, 오라클이 평균치의 계산에서 널(null)을 무시한 경우 등에 경고가 설정됩니다. 이 경우는 대응하는 요소의 값이 “W”로 됩니다. 그렇지 않은 경우에 이 요소의 값은 널(null)입니다. 1개라도 경고가 설정되면 첫 번째 요소 [0]는 항상 “W”가 됩니다. 각 “W”는 치명적인 에러는 아니지만, 각 경고는 검사해야 할 문제나 상황이 있음을 프로그래머에게 보여줍니다. |
| sqlca.sqlwarn[0] | 어떤 임의의 경고가 1개라도 설정된 경우에는 W, 그렇지 않은 경우에는 NULL 스트링을 가지는 필드입니다. 즉, sqlwarn에 대해서 indicator 역할을 하는 필드입니다. |
| sqlca.sqlwarn[1] | SELECT나 FETCH 문장이 호스트 변수의 폭이 충분하지 않기 때문에 리턴된 문자 필드가 1개 이상 절사 되었음을 나타냅니다. 이것은 문자 데이터에만 적용됩니다. 즉, 오라클은 수치 타입 데이터에 대해서는 경고를 설정하거나, 음의 sqlca.sqlcode를 리턴하지 않고 절사를 합니다. 어느 필드가 얼마만큼 절사되었는지를 알기 위해서는, 이것에 대응하는 지시자 별수를 참조해야 합니다. 지시자 변수가 양인 경우, 이 값은 절사 전의 데이터 길이입니다. 그러므로 호스트 변수의 폭을 이것에 따라서 증가시켜야 합니다. |
| sqlca.sqlwarn[2] | 이는 반드시 에러라고 볼 수 없으며, 프로그래머에게 유용하게 사용될 수 있습니다. “W”가 설정되어 있는 경우, sqlca.sqlwarn[2]는 AVG, SUM, MIN, MAX 등의 함수 계산에서 1개 이상의 널이 무시되었음을 보여줍니다. |
| sqlca.sqlwarn[3] | SELECT나 FETCH 절에서 열의 개수가 INTO 절에서의 출력 호스트 변수의 개수와 다른 경우에는 W, 그렇지 않은 경우에는 NULL 스트링을 가지는 필드입니다. 이때 데이터는 리턴되지만, 리턴되는 항목의 수는 적은 쪽에 일치됩니다. |
| sqlca.sqlwarn[4] | UPDATE나 DELETE에서 WHERE 절이 없는 경우에는 W, 그렇지 않은 경우에는 NULL 스트링을 가지는 필드입니다. 이는 오라클이 조건없는 UPDATE 또는 DELETE 인지를 나타내서 확인시키거나, 롤백할 수 있도록 경고를 설정합니다. |
| sqlca.sqlwarn[5] | 현재는 사용되지 않습니다. |
| sqlca.sqlwarn[6] | 실행된 SQL 문에 의해 오라클이 논리적인 작업 단위의 롤백을 행한 경우에, 이 필드에는 “W”가 설정됩니다. 이 필드는 ROLLBACK WORK 문 뒤에 설정되는 것이 아니고, 묵시적인 ROLLBACK WORK에 대해서 설정되는 것에 주의하기 바랍니다. 예를 들어, Deadlock에 의해 트랜잭션이 롤백되는 경우에는 “W”기 설정됩니다. |
| sqlca.sqlwarn[7] | 행의 현재 데이터가 쿼리와는 모순되는 데이터인 경우(혹인, 행의 현재 데이터가 이 쿼리의 시작 후에 삭제된 경우)에 이 필드에는 “W”가 설정됩니다. 쿼리에서 지정하고 다시 FOR UPDATE 구에서 지정한 테이블에 포함되는 열이, 이 쿼리를 시작한 시점에서 이 행이 추출 또는 잠금 된 시점 내에 갱신된 경우에 추출 처리가 리턴된 시점에서 이 경고가 설정됩니다. 이 경고가 설정되는 조건은 이 열의 쿼리의 SELECT 리스트에 있으면서 FOR UPDATE 구에서 지정한 테이블 속에도 있어야 합니다. 이 요소는 SQL/DS나 DB2와 호환성이 없습니다. SQL/DS나 DB2에는 이와 같은 기능이 없기 때문에 사용자가 이들 시스템과의 호환성을 확보하고 싶은 경우, 이 요소를 사용해서는 안됩니다. |
| sqlca.sqlext | 현재는 사용되지 않습니다. |
실제 프로그램에서 SQLCA를 사용하려면 아래의 예제와 같은 문법을 사용해야 합니다.
EXEC SQL UPDATE EMP
SET ENAME = 'MARK';
WHERE EMPNO = '1';
IF(sql.ca.sqlcode != 0 && sqlca.sqlcode != 1403) {
printf("[ERROR] UPDATE SQLCODE : [%d] MSG : [%s].\n",
sqlca.sqlcode, sqlca.sqlerrm.sqlerrmc);
exit(0);
}
위의 예제는 EMP 테이블의 데이터를 갱신하면서 발생할 수 있는 오류에 대한 처리를 기술한 것입니다. 위 예제 프로그램은 EMP 테이블의 EMPNO가 ‘1’인 데이터에 대해 ENAME 컬럼의 값을 갱신하는 프로그램입니다. 업데이트할 데이터가 존재하지 않아 발생하는 오라클 경고 코드인 ORA-1403(NO DATA FOUND)이 아니거나, 그 외의 SQL 오류가 발생하면 화면에 에러 발생임을 알리고 에러 코드와 에러 메시지를 화면에 출력합니다.
물론 1403의 경우만 검출하여 처리하고 싶다든지, SQLCODE가 0이 아닌 모든 경우에 대해서 오류 처리를 하는 것과 같이, 모든 오라클 코드 값에 대한 사용자 정의가 가능합니다. 실제 프로그램에서도 위와 같이 사용하며, SQLCA의 다른 요소들도 위와 동일하게 사용할 수 있습니다.
ORACA
SQLCA 만으로도 많은 정보를 획득하고 필요한 작업을 처리할 수 있습니다. 실제 현업에서도 SQLCA 만을 참조하여 프로그램을 개발하는 경우가 많이 있습니다. 하지만 SQLCA 영역에서 얻는 정보보다 더 많은 정보를 획득하여 사용하고 싶다면 ORACA의 사용을 고려해 볼 수 있습니다.
ORACA는 SQLCA에서 얻을 수 있는 것보다 조금 더 많은 정보를 얻을 수 있는 데이터 구조입니다. ORACA는 실행 시 발생하는 에러뿐만이 아니라, 성능 통계에 대한 보조 정보도 제공합니다. ORACA는 필수가 아닌 선택이며 SQLCA와 동일하게 Include 부분에서 참조하여 사용할 수 있습니다. SQLCA 파일과 동일한 위치인 오라클 홈 디렉터리 밑의 precomp/public에 ‘oraca.h’ 파일이 있습니다.
ORACA 파일은 SQLCA 파일에서와 같이 다음의 두 가지 방식으로 선언 될 수 있습니다.
EXEC SQL INCLUDE ORACA; #include <oraca.h>
ORACA는 다음과 같은 정보를 가지고 있습니다.
- 현재 SQL 문의 텍스트(orastxt)
- 에러가 있는 파일의 이름(orasfrm)
- 에러가 있는 행의 번호(oraslnr)
- SQL 문 보존 플래그(orastxtf): 이 플래그를 설정함으로써 어느 조건으로 문을 보존할 것인지를 선택할 수 있습니다.
0. 디폴트 값. SQL 문을 보존하지 않습니다.
1. SQLERROR가 있는 SQL 문만을 보존합니다.
2. SQLERROR 및 SQLWARN이 있는 문을 보존합니다.
3. SQL 문을 전부 보존합니다. - DEBUG 처리의 사용 허가 플래그: 이 플래그는 0이나 1을 설정할 수 있으며, 1을 설정한 경우에는 모든 DEBUG 처리를 사용할 수 있습니다.
- 커서 캐시 검사(orahchf)
SQLCA는 프로그램의 시작 부분에 선언되므로 프로그램 안에서 전역적으로 사용될 수 있습니다. 하지만 ORACA는 선언만으로는 전역적 사용이 불가하며, 아래에 제시된 바와 같이 몇 단계의 예비 단계를 거쳐야 ORACA의 기능이 활성화되어 사용이 가능합니다.
- 단계 1: EXEC SQL INCLUDE 또는 #include를 사용하여 ORACA 선언
- 단계 2: ORACA = YES로 선행 컴파일러 옵션 설정
- 단계 3: ORACA에서 필요한 플래그 설정
SQLCA와 달리 ORACA는 선택적 사용이 가능하게 되어 있습니다. 선택적 사용이라는 것은 선언만 하고 사용하지 않을 수도 있다는 것입니다. 이러한 특징 때문에 SQLCA 처럼 선언과 동시에 SQLCA 구조체 멤버가 활성화되어 사용되는 것이 아니라, ORACA를 구성하고 있는 각 구조체에 대한 값의 설정을 통해서만 기능의 활성화가 이루어지며 사용이 가능해집니다.
ORACA 구조체가 어떻게 구성되어 있는지 살펴보겠습니다. 아래의 표를 보면 ORACA 구조체를 개괄적으로 확인할 수 있습니다.
struct {
char oracaid[8];
long oracabc;
long oracchf;
long oradbgf;
long orastxtf;
struct {
unsigned short orastxtl;
char orastxtc[70];
} orastxt;
struct {
unsigned short orasfnml;
char orasfnmc[70]
} orasfnm;
long oraslnr;
long orahoc;
long oramoc;
long oracoc;
long oranor;
long oranpr;
long oranex;
} oraca;
각 구조체의 멤버가 어떤 정보를 갖는지는 아래 표를 통해 확인 가능합니다.
| 번호/멤버 | 설명 |
| oraca.oracaid | 예약된 필드입니다. |
| oraca.oracabc | 예약된 필드입니다. |
| oraca.oracchf | 성능 통계를 수집하기 위한 플래그 픨드로 사용자에 의해 설정될 수 있습니다. 만약 이 필드의 값이 0이라면 통계 정보를 수집하지 않음을 의미하며, 항상 수집을 하도록 설정하고자 한다면 1로 설정합니다. 이는 커서 캐시의 일관성을 체크와 관련된 필드입니다. |
| oraca.oradbgf | 마스터 플래그로서 사용자에 의해 설정될 수 있습니다. 1이라면 다른 모든 ORACA 필드를 활성화하는 것이며, 그렇지 않은 경우에는 0이 설정됩니다. |
| oraca.orastxtf | 가장 최근에 실행된 SQL 문장을 저장할 시점을 보여주기 위해 플래그가 설정합니다. 이 값이 0이라면 디폴트 값으로 SQL 문을 보존하지 않으며, 1인 경우에는 에러가 있는 SQL 문만을 보존하며, 2인 경우에는 에러 및 경고가 있는 SQL문을 보존하며, 3인 경우에는 항상 SQL 문 전부를 보존합니다. |
| oraca.orastxt | 마지막 SQL 문장의 텍스트 정보를 가지는 필드로서 에러를 검출하는 경우에 특히 유효합니다. 사용자는 오라클이 해석한 문의 내용을 조사할 수 있습니다. 프리 컴파일러가 해석한 문(CONNECT, FETCH, COMMIT 등)이 ORACA 안에는 나타나지 않습니다. SQL 문의 처음부터 70문자까지 표시됩니다. SQL문의 처음부터 70문자까지 표시됩니다. SQL문의 포맷은 SQLCA의 에러 메시지 포맷과 동일합니다. |
| oraca.orastxt.orastxtl | 저장된 SQL 문장의 길이를 나타냅니다. |
| oraca.orastxt.orastxtc | 저장된 SQL 문장의 텍스트를 나타냅니다. |
| oraca.orasfnm | 하나의 어플리케이션을 위해 복수의 파일을 컴파일하는 경우, 오라클은 에러가 발생한 파일을 나타냅니다. 즉, SQL 문장을 포함하는 파일의 이름을 가지는 필드 영역입니다. |
| oraca.orasfnm.orasfnml | 저장된 SQL 문장을 포함하는 파일 이름의 길이가 들어갑니다. |
| oraca.orasfnm.orasfnmc | 파일명에 대한 실제 텍스트가 들어갑니다(xxx.pc). |
| oraca.oraslnr | 저장된 SQL 문장에 대한 파일 내에서 해당 라인 번호를 가집니다. |
| oraca.orahoc | 요청된 최대 오픈 오라클 커서 정보가 들어갑니다. |
| oraca.oramoc | 필요한 최대 오픈 오라클 커서 정보가 들어갑니다. |
| oraca.oracoc | 현재 사용 중인 오라클 커서의 수가 값으로 들어갑니다. |
| oraca.oranor | 커서 캐시 재할당의 횟수 정보가 들어갑니다. |
| oraca.oranpr | SQL 문의 “해석(parse)” 횟수 정보를 가집니다. |
| oraca.nex | SQL 문의 실행 횟수 정보를 값으로 가집니다. |
실제 프로그램에서 ORACA를 사용하려면 앞서 기술한 바와 같이 선언만으로는 충분하지 않습니다. 구조체의 각 멤버에 활성화 및 설정 단계가 필요합니다. 아래의 예제와 같은 처리 과정을 거쳐야 합니다.
#include <stdio.h>
#include <sqlca.h>
#include <oraca.h>
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
EXEC SQL END DECLARE SECTION;
/*
* ORACA = YES는 ORACA를 사용하기 위해 필히 기술해야 함.
* */
EXEC ORACLE OPTION (oraca = yes);
void main() {
/* 에러 및 경고가 발생한 SQL 문장을 저장하도록 설정 */
oraca.oradbgf = 1; /* 모든 필드 활성화 */
oraca.orastxtf = 3; /* 모든 SQL 문장 보존 */
oraca.oracchf = 1; /* 성능 정보 수집 */
/* Log on oracle */
strcpy((char *)uid.arr, "userid");
uid.len = (short) strlen((char *)uid.arr);
strcpy((char *)pwd.arr, "password");
pwd.len = (short) strlen((char *)pwd.arr);
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
if(sqlca.sqlcode != 0) {
printf("[ERROR] Connect Error SQL_MSG : [%]d\n",
sqlca.sqlerrm.sqlerrmc);
exit(0);
}
EXEC SQL SELECT empno
INTO :empno
FROM scott.emp
WHERE empno = 1;
if(sqlca.sqlcode < 0) {
printf("\nError occurred on SQL statement: %.*s",
oraca.orastxt.orastxtl, oraca.orastxt.orastxtc);
printf("\n Contained in file : %.*s",
oraca.orasfnm.orasfnml, oraca.orasfnm.orasfnmc);
printf("\n Near line number : %d", oraca.oraslnr);
printf("\n ORACLE error number : %d", sqlca.sqlcode);
printf("\n ORACLE error message : %.*s \n",
sqlca.sqlerrm.sqlerrml, sqlca.sqlerrm.sqlerrmc);
exit();
}
exit();
}
예제의 시작 부분에서 ORACA 기능을 활성화하고 데이터 수집 레벨을 정의하여 ORACA를 사용하는 프로그램입니다. 기능 정의 이후에 수행되는 SQL 문장들은 별도의 기능 재정의가 없는 한 최초에 정의된 기능을 유지합니다.
SQLCA에 비해 설정해야 할 부분이 더 많기는 하지만 조금 더 세부정보를 출력할 수 있기 때문에 더 많은 정보를 얻고자 할 때는 ORACA가 유용합니다. 다만 실제 업무에서는 에러가 발생한 부분이 별도로 기술되게 프로그램을 작성하므로, 굳이 실행 시의 SQL 문장과 같은 정보가 필요치 않은 경우가 많습니다. ORACA를 사용할 때 이러한 부분을 적절히 사용하시기 바랍니다.
오류 검출 및 처리
오류 검출과 처리 방식 2가지 : 명시적, 묵시적 오류 처리
명시적 오류 처리는 Pro*C 프로그램 안의 SQL 문장 또는 EXEC SQL 문장을 실행한 후에 매번 SQL 문장의 오류를 검사하고 이에 대한 처리를 기술하는 방식입니다.
묵시적 오류 처리는 모든 SQL 문장과 EXEC SQL 문장 실행 후에 오류 처리를 기술하는 것이 아니라, 전역적 혹은 지역적으로 오류가 발생했을 때의 처리 방안을 기술하여 모든 오류에 동일한 처리 방식을 적용합니다.모든 오류 또는 경고에 대해 동일한 처리가 가능하며, 명시적 처리와 같이 매번 SQL 문장마다 기술하는 방식이 아니기 때문에 개발자의 실수에 의한 누락이 발생하지는 않습니다.
일반적으로는 간단한 프로그램에서는 명시적 처리를 많이 선호하는 편이며, 코드 라인이 많은 프로그램이거나 팀 코딩을 해야 하는 경우에는 묵시적 처리를 선호하는 편입니다.
| 묵시적 오류 처리 | 명시적 오류 처리 |
| WHENEVER 문장 사용 | 정규 호스트 언어 조건 문장 사용 |
| 전역적으로 실행 시간 조건 검사 | 문장 별로 실행 시간 조건 검사 |
| 위치적으로 SQL 문장에 영향 | 논리적으로 SQL 문장에 영향 |
(1) 명시적 오류 처리
명시적 오류 처리 방식에서는 묵시적 처리 방식처럼 전역적 혹은 지역적이라는 단어가 존재하지 않습니다. SQL 문장 마다 오류 처리 구문을 지정하여 오류를 처리합니다. 명시적으로 처리한다는 것은 SQL 문장 10개에 대해 10개의 오류 처리를 할 수도 있고 안 할 수도 있다는 것으로, 오류 처리를 하지 않았다고 하여 실행 상의 문제나 컴파일 상의 문제가 일어나지는 않습니다. 다만 발생 가능한 오류 처리가 누락되어서, 실제로 오류가 발생할 위험은 내재되어 있습니다.
명시적 오류 처리는 각 SQL 문장이 수행된 후에 SQLCA 구조체의 멤버인 ‘sqlcode’를 통해 확인 가능하며, 추출된 sqlcode 값에 따라 정상과 오류를 구분하여 처리합니다. 오류가 발생한 경우 오류 번호가 아닌 오류 메시지 내용을 확인하고 싶다면 SQLCA 구조체의 또 다른 멤버인 ‘sqlerrm.sqlerrmc’를 활요하면 됩니다. SQL 문장마다 사용할 수 있으며, 재사용 시 직전의 값은 초기화됩니다.
#include <stdio.h>
#include <sqlca.h>
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20]; /* DB USER ID */
VARCHAR pwd[20]; /* DB PASSSWORD */
Int empno;
EXEC SQL END DECLARE SECTION;
void main {
/* Log on oracle */
strcpy((char *)uid.arr, "userid");
uid.len = (short)strlen((char *)uid.arr);
strcpy((char *)pwd.arr, "password");
pwd.len = (short)strlen((char *)pwd.arr);
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
if(sqlca.sqlcode != 0) {
printf("[ERROR] Connect Error SQL_MSG : [%d].\n",
sqlca.sqlerrm.sqlerrmc);
exit(0);
}
EXEC SQL SELECT empno
INTO :empno
FROM scott.emp
WHERE empno = 1;
if(sqlca.sqlcode == 1403) {
printf("[WARNING] NO DATA FOUND.\n");
}
exit(0);
}
이 예제는 데이터베이스에 접속하여 scott.emp 테이블에서 사원 번호가 ‘1’인 데이터를 추출하는 프로그램으로서, 데이터베이스 접속과 데이터 검출 시의 에러 및 경고에 대해 명시적으로 기술하여 오류를 처리하고 있습니다.
이외 같이 처리하는 것을 명시적 오류 처리 방법이라고 합니다. 특별히 어려운 부분은 없지만 SQL 문장 마다 개발자가 직접 기술해야 하기 때문에 개발자의 실수에 의해 기술하지 않고 처리되는 경우가 발생할 수 있습니다. 이는 운영 중에 에러로 연결되어서 운영에 치명적인 해를 가할 수도 있습니다. 그러므로 명시적 오류 처리 방식을 이용할 경우에 항상 유념해야 합니다.
(2) 묵시적 오류 처리
명시적 오류 처리는 프로그램 내 모든 SQL 문장 마다 오류 처리를 해야 하며 개발자의 실수로 오류 처리를 하지 않은 경우에는 잠재적으로 오류 가능성을 내포한 프로그램이 되는 것입니다. 어떤 회사든지 이러한 명시적 오류를 누락한 프로그램은 어렵지 않게 찾을 수 있습니다. 이러한 코딩 누락에 의한 오류와 SQL 문장ㅁ 마다 기술해야 하는 번거러움을 해결하기 위해 묵시적 오류 처리를 이용할 수 있습니다.
묵시적 오류 처리에서는 전역적인 설정과 지역적인 설정이 모두 가능합니다. 전역적으로 처리한다는 것은 프로그램의 시작 전, 즉 호스트 변수 선언 후에 기술하는 것을 의미합니다. 지역적이라 함은 각 함수 별로 프로그램 시작 위치에 ‘EXEC SQL WHENEVER’ 문장을 두는 것을 의미하며. 전역적 혹은 지역적 설정 두 방식 모두 실행 가능한 첫 번째 SQL 문장 이전에 선언하여 사용하게 됩니다.
묵시적으로 에러를 처리하기 위한 구문은 아래와 같습니다.
EXEC SQL WHENEVER condition action;
- condition
| SQLERROR | 현재 문장이 에러를 발생시킬 때 (SQLCODE < 0) |
| NOT FOUND | 현재 SELECT 또는 FETCH 문장 후 검색한 행이 없을 때 (SQLCODE = 1403) |
| SQLARNING | 현재 문장이 경고를 발생시킬 때 (SQLWARN[1] = W) |
- action
| GOTO label | label 문장으로 분기합니다. |
| STOP | 즉시 종료합니다. |
| CONTINUE | 정상적으로 수행합니다. 실행시간 조건은 무시됩니다. |
| DO rountine_call | routine을 호출합니다. Proc*C/C++ release 2.2 이후에서는 매개변수 전달을 허용합니다. |
WHENEVER 문장 사용 시 condition은 정의되어 있으며, 각 condition에 대한 action은 다양한 방식으로 처리 가능합니다. 이번에는 예제를 통해 실제 처리 예를 알아 보겠습니다.
WHENEVER를 사용하여 모든 오류 상황에 특정한 라벨을 지정해서 처리하도록 한 전역적인 묵시적 오류 처리의 예제입니다. 명시적 처리에 비해서 간단하게 사용할 수 있는 이점이 있습니다. 다만 모든 오류에 대해 일괄적인 처리 방식을 적용하기 때문에 특정 오류에 대한 개별 오류 처리는 불가능 합니다.
#include <stdio.h>
#include <sqlca.h>
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
EXEC SQL END DECLARE SECTION;
EXEC SQL WHENEVER SQLERROR GOTO error_position;
/* 전역적으로 설정 */
void main() {
/* Log on oracle */
strcpy((char *)uid.arr, "userid");
uid.len = (short) strlen((char *)uid.arr);
strcpy((char *)pwd.arr, "password");
pwd.len = (short) strlen((char *)pwd.arr);
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
EXEC SQL INSERT INTO emp(empno, ename)
VALUES(1, 'Kevin');
EXEC SQL COMMIT WORK RELEASE;
exit();
error_postion;
printf("[ERROR]SQL ERROR CODE : [%d], MSG: [%s].\n",
sqlca.sqlcode,
sqlca.sqlerrml.sqlerrmc);
EXEC SQL ROLLBACK WORK RELEASE;
exit();
}
아래 예제는 WHENEVER를 전역적이 아닌 지역적으로 사용하여 WHENEVER 구문에 의해 지정된 처리를 main 함수 내에서만 수행하게 하며, 다른 함수에서는 WHENEVER와 상관없이 개별적으로 명시적인 처리가 가능하도록 구성한 프로그램입니다.
#include <stdio.h>
#include <sqlca.h>
EXEC SQL BEGIN DECLARE SECTION;
VARCHAR uid[20];
VARCHAR pwd[20];
EXEC SQL END DECLARE SECTION;
void main() {
EXEC SQL WHENEVER SQLERROR GOTO error_position;
/* 지역적으로 설정 */
/* Log on oracle */
strcpy((char *)uid.arr, "userid");
uid.len = (short)strlen((char *)uid.arr);
strcpy((char *)pwd.arr, "password");
pwd.len = (short)strlen((char *)pwd.arr);
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;
EXEC SQL INSERT INTO emp(empno, ename)
VALUES(1, 'Kevin');
EXEC SQL COMMIT;
Update_Emp(); /* 내부 함수 호출 */
exit();
error_position;
printf("[ERROR] SQL ERROR CODE: [%d], MSG: [%s].\n",
sqlca.sqlcode,
sqlca.sqlerrml.sqlerrmc);
EXEC SQL ROLLBACK WORK RELEASE;
}
void Update_Emp() {
EXEC SQL UPDATE emp
SET ename = 'Martin'
WHERE empno = 1;
if(sqlcq.sqlcode != 0 && sq;ca/sq;cpde != 1403) {
printf("[ERROR] UPDATE CODE : [%d].\n", sqlca.sqlcode);
EXEC SQL ROLLBACK WORK;
}
}
명시적 처리든 묵시적 처리든 프로그램을 개발함에 있어 오류 처리 부분을 꼭 기술해야 합니다. 많은 개발자들이 오류 처리의 중요성을 간과하여 오류 처리 부분을 누락흔ㄴ 경우를 많이 접하게 도비니다. 개발의 필수 덕목이 오류 처리라는 것을 꼭 명심하기 바랍니다.
Pro*C 프로그램의 구성
실제 Pro*C 프로그램을 작성하기 위해서 어떤 부분이 필요하고, 각 구성 요소 별로 어떤 처리가 필요한지 구체적으로 알아보자.
Pro*C 프로그램은 큰 맥락에서 보면 2개의 부분으로 구성되어 있으며, 하나는 애플리케이션 프롤로그고, 다른 하나는 애플리케이션 본체이다. Pro*C 프로그램을 작성하멩 있어 두 부분은 필수적으로 사용된다.
- 애플리케이션 프롤로그
: 변수를 정의하고, Pro*C 프로그램을 위한 일반적인 준비를 수행합니다. - 어플리케이션 본체
: ORACLE 데이터를 조작하기 위한 INSERT 문이나 UPDATE 문, 데이터를 추출하는 SELECT 문과 같은 SQL 문을 포함합니다. Pro*C가 처리할 때 필요로 하는 코드의 앞뒤에 어떤 C 코드를 지정해도 상관이 없으며 SQL 문장을 제외한 부분에서는 C 프로그램 문법이 사용됩니다.
proc 주요 옵션
1) close_on_commit
이 옵션의 기능은 EXEC SQL COMMIT; 등의 문장을 만나서 commit을 하게 될 때에, 그때까지 해당 session에서 열려있던 모든 cursor를 자동으로 close 시키는 것입니다.
디폴트 값은 no이며 거의 yes로 하는 일이 없다고 봐도 됩니다.
2) cpp_suffix
만일 사용하는 시스템에서 C++ 파일의 suffix를 .cpp가 아닌 다른 것으로 지정해 놓고 있다면 이 옵션에다가 써 주시면 됩니다. ^^; proc로 C++의 embedded SQL을 사용할 때에 쓰는 옵션인데, 설정 안하면 기본은 cpp입니다.
3) def_sqlcode
default는 no입니다. 만일 시스템의 공통 헤더파일에서 #define SQLCODE sqlca.sqlcode 라고 매크로를 만들어놓지 않았다면, 이것을 yes로 하면 그게 있는 것과 다름없는 상태가 되어버립니다. ^^;; 재미있는 매크로지요. 대부분의 프로그래머들이 sqlca.sqlcode라는 변수명 대신 SQLCODE라는 매크로명으로 프로그램을 하고 있음에 착안한 옵션입니다.
4) define
이것은 preprocessor를 위한 define문을 수행시켜줍니다. 분할컴파일등에 쓰이는 symbol에 대한 정의인데, 대표적인 예가, _PA_RISC2_0 이죠. (이 게시판에서 먼저 올라왔던 글에서 나옵니다.)
5) hold_cursor
cursor 캐시에서 커서 홀딩에 대한 컨트롤을 하냐 마냐 하는 옵션입니다. 제가 일하는 사이트에서는 이 옵션을 yes로 놓고 컴파일합니다. 디폴트 값은 no입니다.
6) iname
이건 input 파일의 이름입니다. 흔히, 컴파일하려는 소스코드 파일명이 들어가는데, 어차피 pc 파일을 프리컴파일 하려는 경우, iname 옵션을 굳이 쓰실 필요가 없습니다. 그냥 옵션명 없이 소스코드 파일명만 적어주지요.
7) include
include 파일의 위치를 찾아냅니다. proc에서 include하는 것은 EXEC SQL INCLUDE로 지정된 파일입니다. 이 파일이 들어있는 path를 여기에 적어줍니다.
include='(/aaa/bbb/inc,/aaa/ccc/inc)’
이런 식으로 여러개의 path를 적어줄 수 있습니다.
8) lines
간단하지만 유용한 옵션입니다. 우리가 디버깅 정보나 로그메시지를 만들 때 __LINE__ 같은 매크로를 씁니다. (소스코드 상에서의 현재 line을 가리키는 변수이지요) 그것이, 이 옵션을 꺼놓고 __LIINE__을 쓰면 c 파일을 기준으로 한 line수가 찍힙니다만, lines=yes 를 주면 이것이 .pc파일의 라인수로 출력됩니다. ^^ 반드시 켜놓으세요. 디폴트는 no입니다.
9) maxopencursors
이름에서 드러나듯이, 열 수 있는 커서의 최대 개수를 의미합니다. 디폴트는 10입니다. 한 프로그램에서 10개 넘는 커서를 동시에 열일이 거의 없기 때문에 대부분 디폴트로 놓고 쓰기는 합니다만, 혹시 10개 넘게 쓸 일 있으면 이것을 조정하셔야 합니다.
10) oname
iname의 반대입니다. 기본적으로, aaaa.pc 파일을 proc로 프리컴파일하면 나오는 파일은 aaaa.c 입니다만, 이 파일명이 좀 다른 것이었으면 좋겠다고 생각될 경우에는 이 옵션을 지정합니다. 하지만, 대부분 makefile등과 연동해서 컴파일 스크립트를 정의하기 때문에 거의 쓸 일은 없습니다.
11) release_cursor
커서 캐시에서 커서를 release 시키는 옵션입니다. hold_cursor와 조합해서 사용하는데, 저희 사이트에서는 이 옵션을 꺼 놓았습니다. 디폴트값은 no입니다.
12) sqlcheck
프리컴파일하려는 pc 파일에 등장하는 SQL문을 검증하는 옵션입니다. 값은 여러가지가 있는데, 안전을 위해서 대부분은 full로 설정합니다. 디폴트는 syntax 입니다.
13) sys_include
시스템 include path입니다. 대부분은 /usr/include인데, 혹시 이상하게 설정해 놓은 시스템이 있다면 바꾸시면 되겠습니다.
14) threads
멀티스레드를 쓰는 프로그램이냐 아니냐 하는 것입니다. 디폴트는 no입니다.
15) unsafe_null
fetch 할 때에, indicator 변수가 없어도 NULL 컬럼의 fetch가 가능하게 만드는 옵션입니다. 디폴트는 no입니다. 이 옵션이 없으면, indicator 변수 없이 fetch 후에, null 컬럼이 있을 경우에는 ORA-1405 에러를 발생시킵니다. indicator가 있으면 indicator 값에 세팅이 되고 정상처리 되겠지요. ^^
16) userid
precompile 때에, proc는 sqlcheck=full 로 옵션을 주었을 경우, SQL문을 검증하기 위해 실제로 DB에 들어갔다 나옵니다. 이때에 사용할 id와 password를 적어줍니다.
userid=scott/tiger 이런 식으로 적어준다.
[오류해결]PLS-S-00201 ‘ ‘ 식별자가 정의되어야 합니다.
SQLCHECK를 SEMANTICS로 설정하고 USERID/PASSWD를 입력하여 PRO*C를 실행해주면 된다.
[oracle@oracle ~]$ proc iname=sherpa.pc SQLCHECK=SEMANTICS userid=[ID]/[PW]
이후에 make all을 통해 정상적으로 작동
Redhat 리눅스를 기반 환경 설정
pcscfg.cfg 파일은 ProC를 사용하기 위한 시스템 설정 파일이다. $ORACLE_HOME/
precomp/admin 에 pcscfg.cfg 파일이 있다. 이 파일에 다음과 같은 내용을 추가한다.
sys_include=($ORACLE_HOME/precomp/public, /usr/include, /usr/lib/gcc-lib/i386-
redhat-linux/egcs-2.91.66/include)
include=($ORACLE_HOME/precomp/public)
include=($ORACLE_HOME/rdbms/demo)
include=($ORACLE_HOME/network/public)
include=($ORACLE_HOME/plsql/public)
ltype=shortsys_include 부분이 두 행에 걸쳐 있는데, 실제 사용할 때는 한 라인으로 작성해야 한다.
/usr/lib/gcc-lib/i386-redhat-linx/egcs-2.91.66/include 부분은 각자의 리눅스 환경에 맞도록 변경해야 한다. /usr/lib/gcc-lib/i386-redhat-linux 디렉토리는 대부분 존재할 것이다. 그 다음 하위 디렉토리를 여러분의 환경에 맞도록 수정한다.
Pro*C/C++ 프로그램 가이드
3.1 용어 설명
– 호스트 프로그램 : 삽입 SQL 문이 포함된 프로그램
– 호스트 언어 : 삽입 SQL을 포함한 C, C++, JAVA, COBOL 등을 지칭
– 호스트 변수 : 삽인 SQL문에서 조건에 사용되는 값을 전달하거나 검색한 값들을 프로그램에 전달하는 변수
3.2 삽입 SQL 문장의 사용
응용 프로그램 상에서, 완전한 SQL문장과 완전한 C 문장을 혼합해서 사용할 수 있고, C의변수와 구조체(structure)를 SQL 문에서 사용할 수 있다.
호스트 프로그램에서 SQL 문장을 사용하려면, EXEC SQL이라는 키워드를 사용하여 시작하고 세미콜론으로 종료한다.
C의 변수들을 SQL 문에서 사용하려면 다른 SQL 필드 이름과 구별하기 위해 콜론(:)을 앞에 붙여 사용한다.
…
EXEC SQL SELECT empno, ename, job
INTO :empno, :ename, :job
FROM emp
WHERE deptno = :deptno ;
…위의 SQL 문에서 SELECT 다음의 empno, ename, job 은 emp 테이블의 필드 이름을 나타내며, INTO 다음의 empno, ename, job은 호스트 변수를 의미한다. 즉 위의 문장은 emp테이블에서 주어진 부서 번호(deptno)에 속하는 직원들의 번호(empno), 이름(ename), 직업(job)을 가져와서 호스트 변수 empno, ename, job에 저장하는 것이다.
3.3 변수 선언
호스트 변수는 아래의 표1과 같은 타입으로 선언할 수 있다.
| 데이타 타입 | 설명 |
| Char | 한 문자 |
| Char[n] | N개의 문자 배열(문자열) |
| int | 정수 |
| short | 작은 정수 |
| long | 큰 정수 |
| float | 부동 소수점수(단정도형) |
| double | 부동 소수점수(배정도형) |
| VARCHAR[n] | 가변 길이 문자열 |
3.4 선언부(declare section)
호스트 변수를 C 언어의 규칙에 따라 선언부에서 선언해야 한다. 예비 컴파일 옵션중
MODE=ORACLE 이면, 특별한 선언부에 선언할 필요가 없다. CODE=CPP 옵션이면(C++을사용한다면), 반드시 선언부가 있어야 한다.
EXEC SQL BEGIN DECLARE SECTION;
/* 모든 호스트 변수를 선언 */
char *uid = "scott/tiger";
...
EXEC SQL END DECLARE SECTION;선언부에는 아래와 같은 것들을 포함할 수 있다.
– 호스트 변수
– 호스트 변수가 아닌 C/C++ 변수
– EXEC SQL INCLUDE 문
– EXEC SQL ORACLE 문
– C/C++ 주석
3.5 SQL 문의 사용법
3.5.1 SELECT 문
SELECT 문을 실행할 떄는 SELECT 문이 반환하는 데이타 행의 수를 다루어야 한다.
SELECT 문장은 아래와 같이 구분할 수 있다.
– 어떤 행도 반환하지 않는 질의
– 한 행만 반환하는 질의
– 한 행 이상을 반환하는 질의
한 행 이상을 반환하는 질의는 명시적으로 선언된 커서(cursor)나 호스트 배열의 사용을 필요로 한다.
여기서는 우선 하나의 행만을 반환하는 SELECT 문에 대해서 언급한다. 커서의 사용법은 아래에서 구체적으로 다룬다.
SELECT 문의 예는 아래와 같다.
EXEC SQL SELECT ename, job, sal + 2000
INTO :emp_name, :job_title, :salary
FROM emp
WHERE empno = :emp_number;오라클은 INTO 절에 있는 호스트 변수들에 반환 SELECT 문의 반환 값을 저장한다. 주의할 것은 SELECT 절에 있는 컬럼의 수와 INTO 절에 있는 호스트 변수의 수가 같아야 한다.
3.5.2 DML 문
INSERT, UPDATE, DELETE 문을 사용하는 방법은 아래와 같다. INSERT의 경우 VALUE절에 적절한 호스트 변수를 전달한다. UPDATE는 WHERE 절과 SET절에 호스트 변수를 명세하여 사용할 수 있고, DELETE는 WHERE 절에 호스트 변수를 명세하면 된다.
…
EXEC SQL INSERT INTO emp (empno, ename, sal, deptno)
VALUES (:emp_number, :emp_name, :salary, :dept_number);
EXEC SQL UPDATE emp
SET sal = :salary, comm = :commission
WHERE empno = :emp_number;
EXEC SQL DELETE FROM emp
WHERE deptno = :dept_number ;
…
3.5.3 커서의 조작
커서를 다루기 위해서는 아래의 명령이 필요하다.
삽입 SQL 문 설명
DECLARE 커서의 이름을 명명하고, SELECT 문과 연관 시킴
OPEN 질의를 수행하고, 결과 집합을 명시
FETCH 결과 집합에서 하나의 행을 가져오고, 커서를 이동시킴
CLOSE 커서를 닫음
아래의 예와 같이 DECLARE CURSOR문을 이용하여 emp_cursor라는 이름의 커서를 정의한다. 커서와 연관된 SELECT 문에 INTO 절을 포함할 수 없다. 커서의 경우 FETCH 명령에서 INTO 절을 사용한다.
EXEC SQL DECLARE emp_cursor CURSOR FOR
SELECT ename, empno, sal
FROM emp
WHERE deptno = :dept_number;커서의 선언은 다른 커서 조작 명령(OPEN, FETCH, CLOSE)보다 앞에 위치해야 한다. 커서 조작 명령은 하나의 단위로 컴파일 되어야 한다. 예를 들어 파일 A에서 DECLARE를 하고 파일 B에서 OPEN할 수 없다.
아래의 예와 같이 emp_cursor를 오픈할 수 있다.
EXEC SQL OPEN emp_cursor;OPEN 명령은 결과 집합의 첫번째 행의 바로 앞을 지정하고 있는 상태이다.
FETCH 명령을 이용하여 결과 집합에서 행들을 가져오고, 호스트 변수의 결과들을 저장하도록 한다. FETCH 명령은 아래와 같이 사용할 수 있다.
EXEC SQL FETCH emp_cursor
INTO :emp_name, :emp_number, :salary;여러 결과를 다 가져오기 위해서, 보통 FETCH 명령은 아래 처럼 루프 속에서 사용된다.
EXEC SQL WHENEVER NOT FOUND GOTO ...
for (;;)
{
EXEC SQL FETCH emp_cursor INTO :emp_name, :emp_number, :salary;
printf(“Name : %s”, emp_name); /* 이름 출력 */
…
}결과 집합이 비었거나 더 이상의 행을 가지고 있지 않다면, FETCH 명령은 “no data
found”에러를 발생한다. 일반적으로 위의 예처럼 무한 루프를 빠져 나오기 위해
WHENEVER NOT FOUND를 사용하게 된다. WHENEVER 문은 에러 처리에서 자세히 설
명한다.
결과들을 다 가져왔으면, 자원을 해제하기 위해 커서를 종료한다.
EXEC SQL CLOSE emp_cursor;
int emp_number;
char temp[20];
VARCHAR emp_name[20];
/* 호스트 변수에 값 지정*/
printf("Employee number? ");
gets(temp);
emp_number = atoi(temp);
printf("Employee name? ");
gets(emp_name.arr);
emp_name.len = strlen(emp_name.arr);
EXEC SQL INSERT INTO EMP (EMPNO, ENAME)
VALUES (:emp_number, :emp_name);3.5.4 VARCHAR 변수
가변 길이 문자열을 선언하기 위해 VARCHAR 슈도 타입을 사용한다. VARCHAR2 컬럼의 값을 처리할 때, C의 표준 문자열 보다 VARCHAR를 사용하는 것이 더 편리하다.
VARCHAR를 구조체로 생각하면 된다. 예를 들어 아래와 같이 VARCHAR로 선언하면 예비 컴파일러는 arr과 len을 멤버로 갖는 구조체로 확장한다.
VARCHAR username[20];
struct {
unsigned short len;
unsigned char arr[20];
} username;VARCHAR를 이용하면, SELECT나 FETCH 이후에 명시적으로 VARCHAR 구조체의 len
필드를 사용할 수 있다.
따라서 아래와 같은 코드를 사용하여 arr 필드에 널(null) 문자를 추가하거나, 길이 필드를 이용하여 strncpy나 printf 함수를 사용한다.
username.arr[username.len] = ’₩0’;
…
printf("Username is %.*s₩n", username.len, username.arr);
SQL 문에서는, 구조체 이름에 콜론(:)을 붙여서 VARCHAR 변수를 참조한다.
...
int part_number;
VARCHAR part_desc[40];
...
main(){
...
EXEC SQL SELECT pdesc INTO :part_desc
FROM parts
WHERE pnum = :part_number;
...질의가 실행된 이후에, part_desc.len은 part_desc.arr에 저장된 문자열의 실제 길이를 저장한다.
C 문장에서는, 구조체의 접근 방식으로 각각의 필드들을 이용한다.
printf("₩n₩nEnter part description: ");
gets(part_desc.arr);
/* INSERT나 UPDATE에서 VARCHAR를 사용하기 전에 길이를 설정해야 한다. */
part_desc.len = strlen(part_desc.arr);3.5.5 호스트 구조체(host structure)
호스트 변수들을 저장하기 위해 C의 구조체를 사용할 수 있다. SELECT나 FETCH 문의
INTO절, INSERT 문의 VALUE 절에서 호스트 변수를 저장하고 있는 구조체를 참조할 수
있다.
구조체가 호스트 변수로 사용될 때, SQL 문에서는 구조체의 이름만 사용되지만 각각의 필드들은 ORACLE에 데이타를 보내거나 ORACLE로부터 데이타를 받게 된다.
아래는 emp 테이블에 호스트 구조체를 사용하여 데이타를 추가하는 예제이다.
typedef struct {
char emp_name[11]; /* 컬럼 길이보다 하나 크게 선언 */
int emp_number;
int dept_number;
float salary;
} emp_record;
...
/* emp_record 타입의 변수 선언 */
emp_record new_employee;
strcpy(new_employee.emp_name, "CHEN");
new_employee.emp_number = 9876;
new_employee.dept_number = 20;
new_employee.salary = 4250.00;
EXEC SQL INSERT INTO emp (ename, empno, deptno, sal)
VALUES (:new_employee );구조체에 선언된 필드들의 순서와 SQL 문에서 관련된 컬럼들의 순서가 일치해야 된다. 아래의 예는 순서가 맞지 않아서 에러를 발생하는 예이다.
struct {
int empno;
float salary;
char emp_name[10];
} emp_record;
...
/* 구조체 필드의 순서와 대응되는 컬럼 순서의 불일치 */
SELECT empno, ename, sal
INTO :emp_record FROM emp;3.5.6 호스트 배열(host array)
배열을 사용하면, 하나의 SQL 문으로 배열의 전체 원소를 조작할 수 있다. 따라서 특히 네트워크 환경에서, ORACLE 통신 오버헤드가 현저하게 줄어든다. 예를 들어, 300명의 직원에 관한 정보를 EMP 테이블에 추가하길 원한다고 하자. 배열이 없다면 300개의 INSERT 문을 실행해야 한다. 배열을 사용한다면, 하나의 INSERT 문으로 가능하다.
배열은 다음과 같이 선언한다.
char emp_name[50][10];
int emp_number[50];
float salary[50];
VARCHAR v_array[10][30];
문자 배열(스트링)을 제외하고는, SQL 문에서 참조할 수 있는 배열은 1차원으로 제한되어 있다. .
int hi_lo_scores[25][25]; /* 허용되지 않음 */
VARCHAR name[2][20]; /* 허용됨 */
char phone[2][14]; /* 허용됨 */
SELECT 문의 INTO 절에 호스트 배열을 사용할 수 있다. SELECT 가 반환하는 행의 최대수를 안다면, 최대 수 만큼의 호스트 배열을 선언하면 된다. 아래의 예와 같이 사용할 수있다.
char emp_name[50][20];
int emp_number[50];
float salary[50];
EXEC SQL SELECT ENAME, EMPNO, SAL
INTO :emp_name, :emp_number, :salary
FROM EMP
WHERE SAL > 1000;위의 예에서, SELECT 문은 최대 50개의 행만 반환한다. 만약 50개의 행 이상을 반환한다면, 위의 방법으로 모든 행을 가져올 수 없다. 더 큰 배열을 사용하거나 커서를 선언한 후 FETCH 문을 사용해야 한다.
호스트 배열을 INSERT 문에서 사용하는 예는 아래와 같다.
char emp_name[50][20];
int emp_number[50];
float salary[50];
/* 호스트 배열에 데이타 지정 */
...
EXEC SQL INSERT INTO EMP (ENAME, EMPNO, SAL)
VALUES (:emp_name, :emp_number, :salary);UPDATE 문에도 호스트 배열을 사용할 수 있다.
int emp_number[50];
float salary[50];
/* 호스트 배열에 데이타 지정 */
EXEC SQL UPDATE emp SET sal = :salary
WHERE EMPNO = :emp_number;호스트 배열을 호스트 구조체의 필드로 사용할 수 있다.
struct {
char emp_name[3][10];
int emp_number[3];
int dept_number[3];
} emp_rec;
...
strcpy(emp_rec.emp_name[0], "ANQUETIL");
strcpy(emp_rec.emp_name[1], "MERCKX");
strcpy(emp_rec.emp_name[2], "HINAULT");
emp_rec.emp_number[0] = 1964; emp_rec.dept_number[0] = 5;
emp_rec.emp_number[1] = 1974; emp_rec.dept_number[1] = 5;
emp_rec.emp_number[2] = 1985; emp_rec.dept_number[2] = 5;
14
EXEC SQL INSERT INTO emp (ename, empno, deptno)
VALUES ( :emp_rec);
...3.5.7 지시 변수(indicator variable)
모든 호스트 변수에 부가적인 지시 변수를 관련시킬 수 있다. 일반적으로 지시 변수는 입력으로 사용되는 호스트 변수에 NULL을 할당하고, 출력으로 사용되는 호스트 변수에 NULL이 오거나 잘려진 값이 저장되는지 검사하기 위해 사용된다.
모든 지시 변수는 2 바이트 숫자형(short)로 선언되어야 한다. SQL에서 사용법은 아래와 같다.
:host_variable INDICATOR :indicator_variable
또는
:host_variable:indicator_variable지시 변수 값의 의미는 아래 표와 같다.
값 의미
0 연산이 성공적으로 수행됨
-1 NULL이 반환되거나, 삽입되거나, 변경됨
-2 호스트 변수에 잘려진 값이 저장되고, 컬럼 값의 원래 길이도 알 수 없음
> 0 호스트 변수에 잘려진 값이 저장되고, 반환된 값은 컬럼 값의 원래 길이를 의미
아래의 예와 같이 지시 변수 SELECT 문에서 사용할 수 있다.
EXEC SQL BEGIN DECLARE SECTION;
int emp_number;
float salary, commission;
short comm_ind; /* 지시 변수 */
EXEC SQL END DECLARE SECTION;
char temp[16];
float pay; /* SQL 문에서 사용되지 않는 변수들 */
...
printf("Employee number? ");
gets(temp);
emp_number = atof(temp);
EXEC SQL SELECT SAL, COMM
INTO :salary, :commission:ind_comm
FROM EMP
WHERE EMPNO = :emp_number;
if(ind_comm == -1) /* commission 이 NULL인지 확인 */
pay = salary;
else
pay = salary + commission;INSERT에 NULL을 주기 위해서 아래와 같이 사용할 수 있다. 아래의 예는 사용자의 입력에 따라 emp_number의 값을 유연하게 입력하는 것을 보여준다.
printf("Enter employee number or 0 if not available: ");
scanf("%d", &emp_number);
if (emp_number == 0)
ind_empnum = -1;
else
ind_empnum = 0;
EXEC SQL INSERT INTO emp (empno, sal)
VALUES ( :emp_number:ind_empnum, :salary);
3.5.8 INCLUDE 문
삽입 SQL을 이용하여 응용 프로그램을 작성하기 위해서는 sqlca.h나 oraca.h 파일을 포함해야 한다. 아래와 같은 방법으로 포함할 수 있다.
#include <sqlca.h>
#include <oraca.h>
또는
EXEC SQL INCLUDE sqlca;
EXEC SQL INCLUDE oraca;여기서 sqlca는 SQL Communication Area를 뜻하며 내부적으로는 sqlca라는 구조체가 선언된 화일이다. 데이타베이스는 SQL문의 실행이 끝날 때마다 sqlca 구조체에 알맞은 값을 지정하여 호스트 프로그램에서 참조할 수 있게 해, 데이타베이스와 호스트 프로그램 사이의 통신 역할을 하게 한다. sqlca에 담겨지는 정보는 경고 메시지, 에러 발생 여부 및 에러코드 등이다. 자세한 내용은 다음 절에서 설명하고 있다.
oraca(Oracle Communication Area)는 sqlca라는 SQL 표준에 덧붙여서 오라클에서 확장한 구조체로서 sqlca에서 제공되는 정보 외에 추가로 필요한 정보를 호스트 프로그램에게 제공하기 위한 구조체이다.
이 oraca를 사용하기 위해서는 다음과 같은 문장을 통해 ORACA=YES라는 값을 지정하여 oraca를 활성화시켜야 한다.
EXEC ORACLE OPTION (ORACA=YES);
그러나, ORACA를 사용하면 프로그램 실행시 추가 작업으로 인한 부담이 늘어나므로 보통의 경우에는 위의 문장을 생략해서 기본값인 ORACA=NO로 지정하여 oraca를 활성화시키지 않는다.
3.6 에러 처리
Pro*C/C++을 이용한 응용 프로그램 작성에서 SQL문의 실행에 따른 에러 처리 및 진단의 방법은 크게 세 가지로 나눌 수 있다.
– WHENEVER문을 이용하는 방법
– sqlca를 이용하는 방법
– oraca를 이용하는 방법
3.6.1 WHENEVER문
WHENEVER문의 구문은 다음과 같다.
EXEC SQL WHENEVER <condition> <action>;<condition>에는 아래의 표와 같은 것을 사용할 수 있다.
| 조건 | 의미 |
| SQLWARNING | 경고 메시지가 발생한 경우 |
| SQLERROR | 에러가 발생한 경우 |
| NOT FOUND | WHERE절의 조건을 만족하는 행을 발견할 수 없거나,SELECT INTO나 FETCH가 어떤 행도 반환하지 않은 경우 |
<action>에는 아래의 표와 같은 것을 지정할 수 있다.
| 조치 | 의미 |
| CONTINUE | 프로그램은 다음 문장을 수행함. 디폴트 동작으로 WHENEVER를 쓰지 않은 경우와 같음 |
| DO | 에러 처리 함수를 수행. 에러 처리 함수 수행 후 실패한 SQL문의 다음 문장으로 제어가 넘어감 |
| DO BREAK | 실제적인 “break” 문장. 루프에서 사용 |
| DO CONTINUE | 실제적인 “continue” 문장. 루프에서 사용 |
| GOTO | label_name 레이블로 제어 이동 |
| STOP | 프로그램 수행을 종료하고, 트랜잭션은 롤백됨 |
WHENEVER문이 정의되면 그 이후의 SQL문을 실행할 때마다 <조건>에 해당되는지를 검사하고 해당되면 사건이 일어날 때마다 <조치>에 정의된 동작을 취하게 된다. 이 WHENEVER문은 다른 조건이나 조치로 구성된 WHENEVER문을 만날 때까지 계속 유효하게 동작한다.
WHENEVER문의 사용 예를 보자.
main()
{
.....
EXEC SQL DECLARE emp_cursor CURSOR FOR /* 커서 설정 */
SELECT empno, ename FROM emp;
EXEC SQL OPEN emp_cursor; /* 커서를 연다 */
EXEC SQL WHENEVER NOT FOUND DO break;
while(1)
{
EXEC SQL FETCH emp_cursor INTO :emp_number, :emp_name;
.......
}
EXEC SQL CLOSE emp_cursor; /* 커서를 닫는다 */
....
}
위 예의 while루프에서 FETCH문이 실행될 때 더 이상 레코드가 발견되지 않으면
WHENEVER문의 조치에 의해 루프를 빠져 나오게 된다.
main()
{
…
EXEC SQL WHENEVER SQLERROR DO sql_error("에러 메시지");
EXEC SQL SELECT ....
18
…
EXEC SQL UPDATE .....
…
}
sql_error(char * errmasage)
{
printf("에러 %s₩n", errmasage);
exit(-1);
}위 예에서는 WHENEVER문이 정의된 이후에 실행되는 SQL문에서 에러가 발생하면
sql_error()라는 함수를 실행하게 된다. 즉 SELECT가 실패해도 sql_error()가 호출되고,
UPDATE가 실패해도 sql_error()가 호출된다.
또 다음과 같은 예를 보자.
/* 무한 루프에 빠지는 예 */
…
EXEC SQL WHENEVER NOT FOUND GOTO no_more;
while(1)
{
EXEC SQL FETCH emp_cursor INTO :emp_number, :emp_name;
…
}
no_more:
EXEC SQL DELETE FROM emp WHERE empno=:emp_number;
....
}
위의 예를 보면 FETCH에서 더 이상 해당되는 행이 없는 경우 no_more로 넘어가게 되고
no_more 다음의 DELETE문에서 다시 NOT FOUND조건에 해당되는 경우 다시 no_more
로 넘어가서 무한 루프에 빠지게 되는 것을 알 수 있다.
아래의 예와 같이 GOTO를 다시 설정하여 무한 루프를 방지한다.
...
EXEC SQL WHENEVER NOT FOUND GOTO no_more;
for (;;)
{
EXEC SQL FETCH emp_cursor INTO :emp_name, :salary;
...
}
no_more:
EXEC SQL WHENEVER NOT FOUND GOTO no_match;
EXEC SQL DELETE FROM emp WHERE empno = :emp_number;
...
no_match:
...
3.6.2 sqlca의 사용
SQLCA는 구조체이다. SQLCA의 필드는 에러, 경고, SQL이 수행될 때 마다 오라클이 갱신하는 상태 정보를 담고 있다. 따라서 SQLCA는 가장 최근의 SQL 연산의 결과를 반영한다.
SQLCA를 사용하기 위해서는 아래와 같은 문장을 포함해야 한다.
EXEC SQL INCLUDE SQLCA;
또는
#include <sqlca.h>
sqlca 구조체의 구조는 다음과 같다.
struct sqlca
{
char sqlcaid[8]; /* "SQLCA" 문자 스트링 */
long sqlabc; /* slqca구조체의 길이 */
long sqlcode; /* 에러코드 */
struct
{
unsigned short sqlerrml; /* 에러 메시지 길이 */
char sqlerrmc[70]; /* 에러 메시지 내용 */
} sqlerrm;
char sqlerrp[8]; /* reserved */
long sqlerrd[6]; /* sqlerrp[0] : reserved
sqlerrp[1] : reserved
sqlerrd[2] : 수행된 행의 개수
sqlerrd[3] : reserver
sqlerrd[4] : 파싱 에러 옵셋
sqlerrd[5] : reserved */
char sqlwarn[8]; /* sqlwarn[0] : 경고 플래그
sqlwarn[1] : 문자스트링이 절단된 경우
sqlwarn[2] : 안쓰임.
sqlwarn[3] : SELECT문에서 필드 개수와
INTO문의 호스트 변수 개수가
일치하지 않음
sqlwarn[4] : DELETE 또는 UPDATE문에서
where절이 없음.
sqlwarn[5] : reserved
sqlwarn[6] : 안쓰임.
sqlwarn[7] : 안쓰임. */
char sqlext[8]; /* reserved */
};
sqlca.sqlcode는 SQL문 실행시 발생한 에러 코드이며 그 값에 따라 다음과 같은 뜻이 있다.
| Sqlcode 값 | 의미 |
| 0 | 성공 |
| 양수 | SQL문의 실행에는 성공했지만 예외 상황이 발생한 경우이다. SELECT INTO 또는 FETCH문에서 WHERE절의 조건에 만족하는 행이 없는 경우에 양수의 sqlcode가 반환된다. |
| 음수 | SQL문의 실행에 실패한 경우이다. 따라서 대부분의 경우 트랜잭션을 복귀(rollback)하여야 한다. |
sqlca.sqlcode를 통해 알아낸 에러 코드의 의미와 원인 및 조치를 알고 싶으면 prompt상에서 oerr라는 명령을 사용한다. oerr 명령은 두 개의 인수를 사용한다. 첫 번째는 에러 메시지를 발생시킨 요소의 코드(예를 들어 ora는 오라클 서버)이며 두 번째 인수는 에러 코드 번호이다.
prompt> oerr ora 에러 코드의 절대값
여기서 에러코드는 절대값을 입력하여야 한다. 즉, 다음과 같이 -942 에러가 발생하였다면 942를 입력하여야 한다.
prompt> oerr ora 942
sqlwarn[0]부터 sqlwarn[7]까지는 경고에 관한 요소이며 이들을 참조함으로써 보다 상세한 제어를 할 수 있다.
sqlca.sqlerrd[2]는 SQL문의 영향을 받은 행의 개수를 담고 있다. 즉, SELECT, DELETEUPDATE문 등의 실행 결과가 반영된 행의 개수를 말하며 sqlca.sqlcode와 더불어 가장 많이 참조되는 요소이다.
sqlca.sqlerrm.sqlerrmc는 에러 메시지를 담고 있으며 이를 참조하여 다음과 같이 에러 메시지를 출력할 수 있다.
sqlca.sqlerrm.sqlerrmc[sqlca.sqlerrm.sqlerrml]=’₩0′;
printf(“%s”, sqlca.sqlerrm.sqlerrmc);
sqlerrmc에는 최대 70자까지의 에러 메시지만 저장되므로, 에러 메시지 전체를 알고 싶으면 sqlglm()을 사용할 수 있다.
sqlglm()의 구문은 다음과 같다.
sqlglm(message_buffer, &buffer_size, &message_length);
여기서 각 매개변수의 뜻은 다음과 같다.
– message_buffer : 에러 메시지가 담겨질 문자 배열.
– buffer_size : message_buffer의 크기.
– message_length : message_buffer에 담겨진 메시지의 크기.
예를 보자.
main()
{
char msg_buffer[100];
int buf_size = 100;
int msg_length;
…
if (sqlca.sqlcode!=0) {
sqlglm( msg_buffer, &buf_size, &msg_length);
msg_buffer[msg_length] = '₩0';
printf("%s", msg_buf);
}
…
}
3.6.3 oraca를 이용하는 방법
SQLCA가 제공하는 런타임 에러와 상태 변화와 같은 정보를 더 자세히 알고 싶을 때,
ORACA를 사용한다. ORACA는 확장된 진단 툴을 제공한다. 그러나 ORACA는 런타임 오버헤드를 추가하므로, ORACA를 선택적으로 사용한다.
ORACA를 선언하기 위해서는 아래와 같은 문장을 프로그램에 추가해야 한다.
EXEC SQL INCLUDE ORACA;
또는
#include <oraca.h>
ORACA를 활성화하려면, ORACA 옵션을 명세해야 한다.
EXEC ORACLE OPTION (ORACA=YES);
ORACA 구조체의 정보는 다음과 같다.
struct oraca
{
char oracaid[8]; /* "ORACA" 문자 스트링 */
long oracabc; /* oraca의 크기 */
long oracchf; /* 커서 캐쉬 일관성 플래그 */
long oradbgf; /* 마스터 디버그 플래그 */
long orahchf; /* 히프 일관성 플래그 */
long orastxtf; /* Save-SQL-statement 플래그 */
struct
{
unsigned short orastxtl; /* 현재 SQL문의 길이 */
char orastxtc[70]; /* 현재 SQL문의 내용 */
} orastxt;
struct
{
char orasfnmc[70]; /* 현재 SQL문을 담고 있는 화일이름 */
unsigned short orasfnml; /* 화일이름의 길이 */
} orasfnm;
long oraslnr; /* 현재 SQL문이 위치한 행번호 */
long orahoc; /* 요청한 MAXOPENCURSORS 값 */
long oramoc; /* 최대로 open할 수 있는 커서 개수 */
long oracoc; /* 현재 사용되고 있는 커서 개수 */
long oranor; /* 재할당된 커서 캐쉬의 개수 */
long oranpr; /* 파싱된 SQL문의 개수 */
long oranex; /* 실행된 SQL문의 개수 */
};
ORACA를 사용한 예는 아래와 같다.
#include <sqlca.h>
#include <oraca.h>
…
main()
{
…
char SQLSTATE[6];
EXEC SQL WHENEVER SQLERROR DO sql_error("Oracle error");
EXEC SQL CONNECT :userid;
EXEC ORACLE OPTION (ORACA=YES);
oraca.oradbgf = 1; /* debug 연산 활성화 */
oraca.oracchf = 1; /* 커서 캐시 통계 정보 수집 */
oraca.orastxtf = 3; /* 항상 SQL문 저장 */
printf("Enter department number: ");
…
);
void sql_error(char *errmsg)
{
char buf[6];
strcpy(buf, SQLSTATE);
EXEC SQL WHENEVER SQLERROR CONTINUE;
EXEC SQL COMMIT WORK RELEASE;
if (strncmp(errmsg, "Oracle error", 12) == 0)
printf("₩n%s, sqlstate is %s₩n₩n", errmsg, buf);
else
printf("₩n%s₩n₩n", errmsg);
printf("Last SQL statement: %.*s₩n",
oraca.orastxt.orastxtl, oraca.orastxt.orastxtc);
printf("₩nAt or near line number %d₩n", oraca.oraslnr);
printf("₩nCursor Cache Statistics₩n------------------------₩n");
printf("Maximum value of MAXOPENCURSORS: %d₩n", oraca.orahoc);
printf("Maximum open cursors required: %d₩n", oraca.oramoc);
printf("Current number of open cursors: %d₩n", oraca.oracoc);
printf("Number of cache reassignments: %d₩n", oraca.oranor);
printf("Number of SQL statement parses: %d₩n", oraca.oranpr);
printf("Number of SQL statement executions: %d₩n", oraca.oranex);
exit(1);
}
…
3.7 오라클 접속 및 해제
3.7.1 접속
오라클에 질의를 하거나 데이타를 조작하기 전에 데이타베이스에 접속을 해야한다. 접속을 하기 위해 CONNECT 문을 사용한다.
아래는 간단하게 접속을 하는 방법을 보여 준다. 처음 예에서 username이나 password는 char 또는 varchar 호스트 변수이다. 밑의 예에서 usr_pwd는 사용자 명과 암호를 “scott/tiger”처럼 슬래쉬(/)로 구분해서 포함해야 한다.
EXEC SQL CONNECT :username IDENTIFIED BY :password ;
또는
EXEC SQL CONNECT :usr_pwd ;아래의 예는 오라클의 사용자 scott(암호는 tiger)로 접속하는 코드이다.
char *username = "SCOTT";
char *password = "TIGER";
...
EXEC SQL WHENEVER SQLERROR ...
EXEC SQL CONNECT :username IDENTIFIED BY :password;
여기서 CONNECT 문에 문자열을 직접 주면 에러가 발생한다.
EXEC SQL CONNECT ‘scott’ IDENTIFIED BY ‘tiger’; /* 에러 발생!!! */3.7.2 원격에서 접속하는 경우
원격에서 오라클 서버를 접속하려면(예를 들어 Pro*C/C++ 프로그램은 db.snu.ac.kr에 있고, 오라클 서버는 dbpub.snu.ac.kr에 있는 경우), 먼저 tnsname.ora 파일을 편집한다.
tnsname.ora 는 $ORACLE_HOME/network/admin (리눅스에서 설치한 경우)밑에 위치한다.
dbpub =
( DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = dbpub.snu.ac.kr)(PORT = 1521))
(CONNECT_DATA = (SERVICE_NAME = ora9i))
)%주의 : 이 설정은 서버마다 다르기 때문에, 관리자가 알려준 사항을 따라야 한다.
원격에서 접속할 때 CONNECT 문에 옵션을 하나 추가한다.
/* 호스트 변수 설정 */
char username[10] = "scott";
char password[10] = "tiger";
char db_string[20] = "dbpub";
…
/* 원격 DB에 접속*/
EXEC SQL CONNECT :username IDENTIFIED BY :password USING :db_string;3.7.3 접속 종료
오라클과의 접속을 해제할 경우에는 다음과 같이 두 가지 문장을 사용할 수 있다.
① EXEC SQL COMMIT1 WORK RELEASE;
② EXEC SQL ROLLBACK WORK RELEASE;
첫 번째 문장은 프로그램 내의 SQL문을 commit하고 접속을 해제하는 경우이고 두 번째 문장은 rollback한 뒤 접속을 해제하는 경우이다. RELEASE는 자원을 해제하고 log off하라는 의미이다. 일반적으로 프로그램이 정상적으로 수행된 경우에는 첫 번째 문장을 이용하여 접속을 끊고, 에러 발생시 프로그램이 종료되는 경우에는 두 번째 문장으로 접속을 끊는다.
3.8 컴파일 및 실행
sample1.pc 파일을 proc를 이용하여 예비 컴파일 한다.
$proc sample1.pc예비 컴파일 하면 sample1.c 파일이 생성된다. sample1.c 파일을 gcc를 이용하여 컴파일 한다. 이 때 오라클 관련 라이브러리들을 포함한다.
$gcc -o sample1 -I$ORACLE_HOME/precomp/public -L$ORACLE_HOME/lib -lclntsh
sample1.c-I(대문자 i)는 gcc의 옵션으로 헤더 파일의 디렉토리 경로를 지정한다. 여기서는 sqlca.h와 oraca.h 등의 오라클 관련 헤더 파일들의 위치한 $ORACLE_HOME/precomp/public을 포함하도록 하고 있다.
-L은 gcc의 옵션으로 라이브러리가 위치한 디렉토리 경로를 지정한다. 여기서는
$ORACLE_HOME/lib를 포함하고 있다.
-l(소문자 L)은 gcc의 옵션으로 라이브러리를 지정한다. 여기서는 clntsh 라이브러리를 가리킨다. $ORACLE_HOME/lib 밑에 있는 libclntsh.so 라는 공유 라이브러리(shared library)를 포함하라는 의미이다.
컴파일이 끝나면, sample1이라는 실행 파일이 생성된다.
[PRO*C] 환경 설정 및 컴파일 (리눅스,Xshell)
